
Essential Infrastructure Skills for Devops

I am a big fan of learning. The more time that I can spend learning about adjacent technologies, the better I can be at my job. I believe that your career can also benefit from learning about what other internal teams are up to. Developers talking with infrastructure folks, or System Administrators learning programing concepts makes us more well rounded technologists. It was one of the reasons I started a few cloud native user groups in my area.
I was asked an interesting question by a developer, who I will call John, in a recent user group. I was giving an impromptu presentation on Openshift Virtualization and mentioned off-hand that I was a figurative (and literal) Grey Beard; an ex-infrastructure guy who has changed his career trajectory to work with cloud-native technologies over the last few years.
“What, as an infrastructure guy, would you like developers to know?”
I have spent the last few years learning all that I can about containerization, public clouds, and Kubernetes, and this is the first time that I have been drug back into thinking about my previous career. John’s question was appreciated because it showed genuine curiosity about something that was outside his comfort zone. I hope to be like John at every opportunity I can.
So, what would I like someone to know about my previous infrastructure career?
Infrastructure and Platform Engineers
Platform Engineering is a newer concept, but it feels familiar to a systems administrator or systems engineers job role. Platform Engineering fundamentally provides a set of developer services and tools to make life easier. In many ways, infrastructure is out to do the same thing. A good infrastructure group will provide a set of easy-to-use services, both on-premises and in the public cloud.
Infrastructure and Platform Engineering jobs are – at least in my humble opinion – a service job. There is a sense of satisfaction with providing a useful, easy, and resilient service that allows developers and business departments to do their jobs effectively.
There is always a catch though, there can be many ways to solve a technology problem. I have learned that not every problem should be solved with infrastructure, but some problems should be.
High Availability Engineering
One of the most important jobs that tends to fall on infrastructure technologists is the idea of resilience. No one is happy if a single component, such as a failed disk, takes down an entire application. Over the years, resilience has evolved to include not only traditional HA concepts such as RAID and redundant switching but also the idea of availability zones and rack awareness.
Availability zones have been around in the datacenter for a while, but cloud providers have made the entry point simple for any company.
So how do we protect our application between availability zones? The way that cloud native folks tend to solve this problem is with software: Mongo can have replicas, or my software has internal logic to handle failures and perform service discovery.
Infrastructure can solve this problem differently without involving the software stack. Let’s use a simple example: my wife’s WordPress site which runs on EKS: It would be possible to engineer multiple replicas of the database (and have to pay for the compute for them to run), or I can use Portworx to replicate just the data so that it is available in a different Availability Zone in the event of a failure. No application reconfiguration is necessary. What is even better, I can protect any application with the same method.
To further illustrate this point, compare a configuration using application level recovery, we need to ensure that we have enough replicas of the application to account for the relatively low availability of EBS storage.
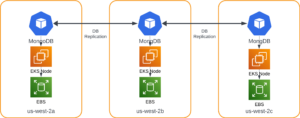
Contrast that with using a replication factor at the PVC/PV level:
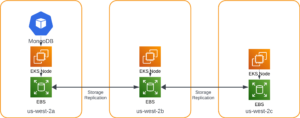
I only need enough replicas to handle application load as my storage can be replicated independently. In the event of a storage failure, my MongoDB Pod can restart in any AZ. Additionally, I can run smaller EC2 instances as I don’t have as many pods running.
Are using database replicas important? Absolutely, but I would always ask myself: Are you making those replicas to handle application load, or to just have another copy of the data somewhere?
Using Portworx (when my infrastructure is on Kubernetes of course), I can provide better and cheaper (as reflected in my AWS bill) protection for my applications that are running a more “application centric” DR plan. My cost savings was achieved by a combination of already having room in my cluster to run databases, as well as being able to undersize my DR environment (less kubernetes nodes) and scale in the event of a disaster. Cloud compute is more expensive than cloud storage for me. Of course my anecdote is not a substitute for running our own Total Cost of Ownership calculation.
Disaster Recovery
Disaster recovery is an important part of any company’s IT infrastructure. It is distinct from HA in that it is designed to recover from not a simple infrastructure failure, but from – well – a disaster.
Most “disasters” I have had to deal with in my career are from human error, rather than an actual disaster.
Disaster recovery typically involves a copy of our application and its data. There is usually (and this is desirable) a human decision and script execution to bring an environment online. Companies that have tried automatic failover usually end up causing their own disasters (see human error above). Besides, in many cases we have to roll back data to an earlier point in time due to the nature of the disaster.
In the same vein as above, treating an application as a portable configuration that I can move provides a lot of simplicity for operators. I don’t have to modify configurations to re-point the app to data services or change around internal load balancing. The fewer steps the better.
For my environment (again, I will pick on my wife’s website). I replicate the PVs from the EKS cluster to an on-premises rancher cluster. The deployments and stateful sets have a replication scale of 0 and can be brought online with a few scale commands (when I have tested, I tend to just use Stork’s built-in activate feature, which reads the desired scale from an annotation and starts the app. Then all I need to do is update Route53 and my application is recovered.
I can use the same procedure (and indeed, the same activate command) to recover multiple applications: WordPress sites, some dedicated gaming servers, and other miscellaneous applications, using the same method. Running recovery on these applications without tools such as Portworx ends up being more work than I can handle in my spare time. The best DR plans are plans that are simple and tested.
Why should we care about any of this as developers?
My intent is not to say that the above opinions on HA and DR are the correct ones for your company, application, or environment, but to simply show my thought process when I think about application availability and recovery in a modern cloud era, while still looking through the lens of my experience.
So I would close with this: have conversations with infrastructure and Platform Engineering folks. We have a lot to learn from each other. I will never be a developer, but the folks I have met have helped me take the first few steps into their world. I have benefited greatly from developers being patient with me. I hope to extend the same sort of information so we can all build a better product.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Chris Crow
Chris is a Technical Marketing Engineer Supporting Portworx



