
Data on Kubernetes at Scale: Why Your CSI Driver Can't Keep Up

In our first blog post about data on Kubernetes, Embracing Data on Kubernetes, we discussed the different types of data that live in your organization, where data on Kubernetes makes sense, and how Kubernetes is now commonly used to run applications plus persistent data all in one stack. Let’s dive a little deeper into data on Kubernetes, discuss some challenges you might have as you scale, and compare the options that you have at an infrastructure layer for Kubernetes persistent data:
- CSI drivers paired with enterprise storage arrays
- Cloud native storage solutions such as Portworx running inside Kubernetes
For decades, our storage arrays provided us enterprise capabilities that we needed to keep our infrastructure humming along and our data resilient. But we may have only had to provision a few volumes a week, or in extreme cases, a handful of virtual machines per day. With modern infrastructure architectures taking the front stage now, can your enterprise storage array keep up with the demands of high Create/Read/Update/Delete (CRUD) churn life cycles that are common in orchestrators such as Kubernetes?
Cloud native architectures have introduced infrastructure requirements that need to keep up with machine scale instead of human scale – often far surpassing the types of provisioning velocity that you or I may have been used to doing by hand or even with simple scripts in days long past. In this blog, we’ll show how cloud native storage solutions such as Portworx can keep up with the CRUD churn compared to traditional enterprise storage arrays as you scale to hundreds or thousands of PersistentVolumes (PVs) in your Kubernetes cluster.
Most CSI Drivers are Simple Shims
Enter Container Storage Interface (CSI) for Kubernetes. While Google originally created Kubernetes to primarily run stateless and ephemeral workloads, it’s now well known that stateful applications DO run in Kubernetes more and more every day. While the CSI spec was in its infancy back in the Kubernetes 1.9 days, it has come a long way since then. We now have storage vendors creating drivers that allow you to take advantage of and surface many of the enterprise features and benefits that storage arrays have historically provided.
But do the combinations of CSI drivers and hardware from array vendors really cut it in a cloud native architecture for data on Kubernetes? Can these features be used on cloud platforms in addition to on-premises deployments and give you the data mobility, resiliency, and feature parity that you need? Can the hardware and CSI driver be as efficient at provisioning operations at scale compared to a fully cloud native and software defined storage solution where no entity external to the Kubernetes cluster takes part in the provisioning workflow?
This last question is what I want to talk with you about in this blog. We’re going to uncover some of the dirty little secrets that array vendors don’t want you to know about, how CSI drivers for most storage solutions are just shims to legacy provisioning methods that have existed for years/decades, and how these arrays can be boat anchors and drag you down in a cloud native architecture instead of enabling you to be as efficient and effective as possible.
Although some of the control planes for these CSI driver based implementations may live in Kubernetes, you’ll be surprised that many of them are just piggybacking on code that might be older than Kubernetes itself when it comes to actual storage operations.
PoC Worked Great, But Can’t Scale? Don’t Be Surprised!
Even if the control plane for Kubernetes storage provisioning and life cycle management lives within Kubernetes, the array or backing device has to go through its own provisioning processes in the controller/microcode, essentially leading to double the provisioning work for a single volume (one call within Kubernetes for the PV, one or multiple API calls to the array controller to provision and present the LUN to the worker node). While this might work just fine in a limited PoC or a small environment, as your needs for PVs in Kubernetes scale, the additional time and provisioning calls end up adding time exponentially.
While legacy provisioning operations may be supported by CSI drivers or other solutions that re-hash Cinder in OpenStack architectures, you still need to deal with the integrations with the external array such as monitoring of underlying RAID/storage pool capacities, integrations via the driver for snapshotting and cloning, supporting replication primitives, monitoring performance, etc… – all of these require API calls to the external storage system when using CSI, which can lead to sluggish performance at the Kubernetes control plane.
This slowdown only gets worse as you scale the number of PVs being used and the storage features needed for each volume. Some vendors even rate-limit the number of API calls that their controllers can support, or may be performing blocking operations on the controller that only allow serial requests – all of which can reduce your multi-million dollar storage array into a boat anchor and bottleneck for your high churn Kubernetes environment.
You may even see some vendors taking a fancy, modularized approach to providing storage features for Kubernetes using legacy enterprise hardware and software – covering all of the different replication, data protection, snapshotting/cloning, and security features you want to use in Kubernetes. But when you dig deeper into each module, you’ll find the same issues – they are simply repackaging an API shim via a CSI driver or sidecar to interface with the native features of their products and then making API calls back to legacy software or hardware – which will expose many of the same issues as an “all-in-one” CSI driver, especially as you scale your PV usage within Kubernetes.
Keeping It Close – The Importance of Cloud Native Storage
Cloud Native Storage (CNS) solutions like Portworx allow all provisioning and lifecycle operations for Persistent Volumes to reside inside Kubernetes. While Portworx DOES use the CSI specification for PV provisioning and presentation to the worker nodes, it does not need to rely on any external entity to the Kubernetes cluster for these operations! Instead of having to make API calls to storage subsystems outside of the Kubernetes cluster itself, everything is self-contained within Kubernetes. This provides several benefits:
- Reduces complexity by removing dependencies on entities external to the Kubernetes cluster; all control plane operations for volume provisioning are contained inside the platform they are consumed from
- Improves observability of the Persistent Volume health and performance metrics without querying an external storage array
- Enables the ability to replicate data to achieve high availability and data resilience without relying on expensive RAID or other protection operations outside of the Kubernetes cluster
- Provides efficiency for common day 2 operations such as snapshotting and cloning without having to rely on an external system to execute those operations and report back with a success or failure
- Maintains the declarative nature of Kubernetes, as most APIs for external storage systems are imperative
Another critical item to keep in mind when designing your persistent storage solution for Kubernetes are things such as LUN presentation and connection limits to your worker nodes. Remember the days of VMware and reaching limits on the number of paths to a LUN or exceeding the number of LUNs allowed to be presented to a single host? Well, those limits are typically in place due to vendor limitations on the hardware side.
As you attempt to add more and more PVs to your Kubernetes cluster when using a legacy hardware array, you could end up with LUN attachment failures due to these types of limits. This is not only an issue with on-premises hardware arrays – even Amazon limits the number of EBS volumes you can attach to an EC2 instance to only 32 for the most widely used instance types! These types of limitations reduce your ability to maximize your compute investment by limiting the number of PVs that you could run across your worker nodes in Kubernetes.
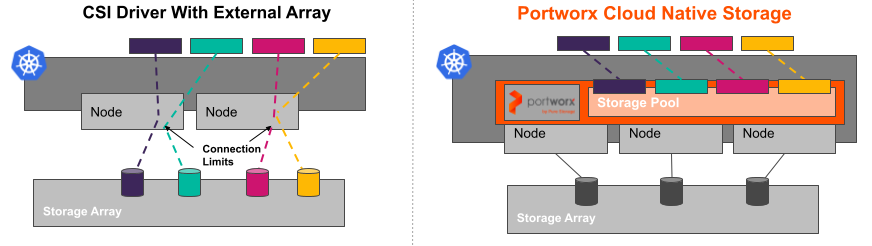
The Beauty of Abstraction and Reuse of Legacy Storage Arrays
One of the great features of Portworx is the ability to consume backing storage from any device and abstract it via storage pools, then provide provisioning capabilities native to and inside Kubernetes. You may be thinking that you need to ditch your existing storage array in order to take advantage of Portworx’s CNS capabilities and benefits – in fact, it’s quite the opposite! We encourage customers to utilize existing storage arrays and present block devices up to the worker nodes running Portworx to maximize your investment and lifetime of your legacy arrays and to be able to reap the benefits you may not get when using these arrays in a native fashion.
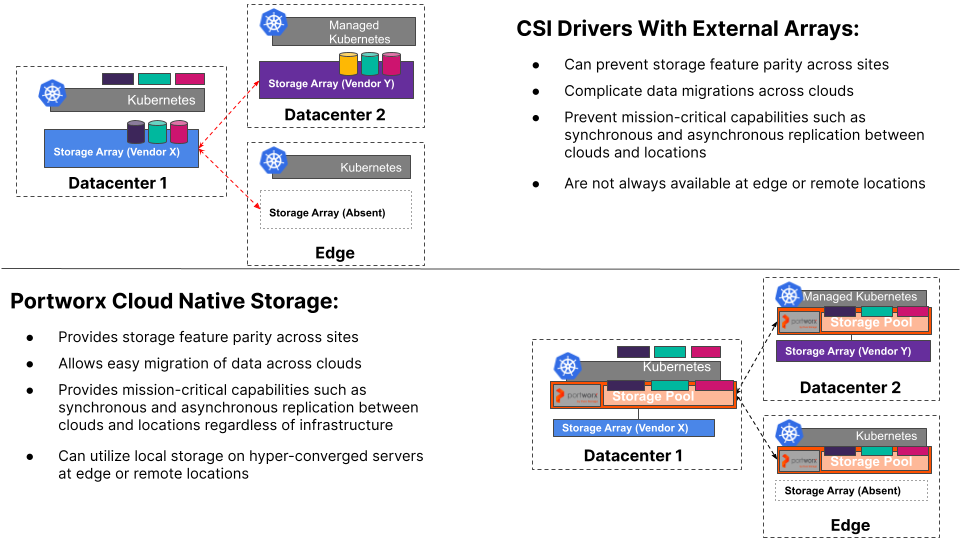
The benefits here are multiple and can be very impactful as you continue your journey within the cloud native ecosystem. Do you have storage arrays at different on-premises locations that aren’t from the same vendor, or even if they are, aren’t the same model and don’t support the same features? No problem – you can achieve feature parity simply by presenting LUNs from those arrays to Portworx nodes that abstract them!
Want to create a true hybrid cloud with storage feature parity between your primary datacenter and AWS EKS clusters? All good – simply present LUNs from your storage array to Portworx running on-premises and EBS volumes to your EKS worker nodes in AWS running Portworx, and you have feature parity no matter where you choose or need to deploy your applications.
Only run hyper converged servers with local storage on-premises and trying to achieve storage feature parity across your servers and VM instances in the cloud? We’ve got you covered there, too!
Let’s Talk External CSI vs. Cloud Native CRUD Performance at Scale
We commonly get prospects and customers telling us that the CSI driver for their array simply can’t keep up with the volume provisioning requirements they have for their Kubernetes clusters. When we sit down with them and explain all of the things that a CSI driver is having to do and the communications paths and delays that take place compared to a cloud native solution such as Portworx, light bulbs begin to glow. It really comes down to a simple statement – that efficiency in provisioning times with CSI drivers and external arrays where provisioning is typically measured in seconds can’t be touched when you compare to provisioning volumes natively inside Kubernetes using straight Portworx volumes!
As we discussed earlier, all of those calls to an imperative API on an entity external to Kubernetes come at a cost – which in the case of CSI drivers for an external array are time and efficiency. Here at Portworx, we simply don’t measure provisioning times in seconds when provisioning volumes from the native Portworx provisioner in Kubernetes – we measure in milliseconds! Again, you may not see these types of scenarios during your PoC when you are evaluating CSI drivers vs cloud native storage – they only rear their ugly heads when you start to truly load a system and are actually provisioning hundreds or thousands of PVs in your Kubernetes cluster! To prove this, we performed some testing at scale with our native Portworx provisioner.
Our test consisted of three provisioning tests where we timed how long it took to mass provision PVs and their respective pods using Portworx native volumes:
- Zero to 200 PVs+pods
- 201 to 400 PVs+pods
- 401 to 600 PVs+pods
The results were what we expected here at Portworx, but would be surprising to customers who have experienced provisioning with CSI drivers and external arrays. As you can see, the provisioning times remain flat regardless of the number of PVs and associated pods that we are provisioning using Portworx:
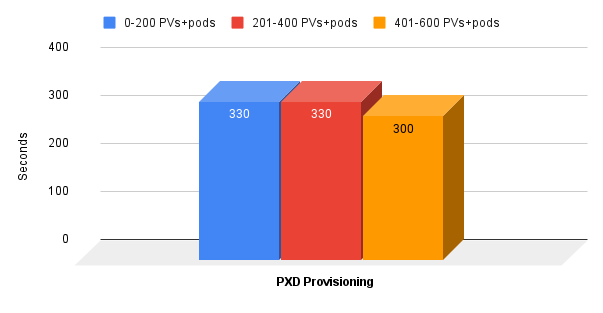
And remember when I said we measure PV provisioning in milliseconds instead of seconds here at Portworx? The average provisioning time for a Portworx native volume during the above test was 160 milliseconds!
So, what can you take away from this data? It’s likely that the CSI driver your legacy array vendor is “giving” you (or, in some cases, charging you for) is simply not good enough to keep up with the CRUD churn we see in Kubernetes. You will require a true CNS solution as you scale that keeps all of the provisioning, attachment, and metrics inside Kubernetes if you want to take advantage of all of the benefits that Kubernetes can bring to your organization.
From an application standpoint, slowdowns due to CSI communications can absolutely crush your service level agreements if you have pods that are slow to start in the case of scaling out for load, or even during detach/reattach operations due to a node failure. If you are expecting a pod to restart as fast as possible during a node failure and come back online, is waiting minutes for that to occur acceptable? With Portworx’s integration of Storage Orchestration Runtime for Kubernetes (STORK), you can be guaranteed that your pods will restart as quickly as possible and on a node that has a local replica of the PV. This is a great question to ask during a PoC for array vendors that are pushing their CSI drivers to determine if they have such a capability, and to understand the reattach time and their capabilities to attach a copy of the PV after a node failure.
If you are considering using a CSI driver for a legacy storage array, I’d encourage you to put it to the test and have some scale testing done as part of your PoC. Sometimes things look “good enough” on the surface when you are doing small-scale testing with a CSI driver, and it can be too late to fix things when you are under the assumption that you’ll see the same provisioning and pod spin up times when you are at scale and under load.
You might also want to consider looking at control plane memory and CPU utilization under these high scale scenarios – keeping track of all of those API calls against an external entity can lead to resource bloat, leaving fewer and fewer resources for the workloads that matter most on your Kubernetes cluster – your applications! Shameless plug here – Portworx control plane resource consumption stays flat no matter how many volumes you provision, and stays just as performant at the 600th volume creation as it did during the first.
Wrapping It Up
Hopefully this blog has given you an idea of why CSI drivers for external hardware arrays just aren’t good enough for a true cloud native storage solution in terms of performance and efficiency. In a high CRUD churn environment such as Kubernetes, the time to provision PVs, attach them to pods, and get the pod up and running is paramount. Having to rely on infrastructure outside of Kubernetes for provisioning of volumes and data consumed within Kubernetes just doesn’t make sense from efficiency and scalability standpoints.
By selecting a true CNS solution such as Portworx for your persistent storage needs in Kubernetes, you can be assured that you are running a purpose-built storage solution that can keep up with the demands of Kubernetes orchestration and life cycle management. Ensure you bake time into your PoC to do some type of testing at scale to understand the limitations that you might face with CSI drivers and external hardware arrays – before it’s too late.
If you’d like to get started understanding Portworx and cloud native storage solutions, head over to http://portworx.local to read more, or head to https://central.portworx.com to sign up for a 30-day trial of Portworx Enterprise and try it out in your own lab or on your own infrastructure!
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Tim Darnell
Director, Technical MarketingExplore Related Content:
- CSI
- Data on Kubernetes
- kubernetes
- Platform Engineering




