Hello and welcome back to another Portworx Lightboard session. Today we’re gonna be talking about data protection on different buckets of what we mean by that. So when we’re talking about data protection, it can mean a lot of things. What we’re gonna cover today is local HA and we’ll get into about what these mean individually, disaster recovery and backup and restore.
So the difference between these is depending on the perspective of where you’re looking to protect the application and what the plan is for recovering that application or individual piece of that application. So for local HA, so local high availability, you would have an application. That application would be sitting on some level of infrastructure. So in this case it’s Kubernetes and that Kubernetes has a persistent volume claim for that application. And of course, there are a number of different nodes underneath here. Let’s say that they’re just x86.
So local high availability means that the data itself is replicated across nodes such that the volume has a copy on other nodes, meaning that if the disk fails at this level, there are other copies of that data available so that you can make your application highly available. The other option is if the app or node fails, there’s other nodes for the application to start and access the data. So it could just be rescheduled by Kubernetes and as long as it can talk to a copy of its data, that application is highly available.
So in this case, local high availability is really approached by the orchestration layer and the data management layer. In terms of the data management layer, we need replication of the individual volumes and blocks of that volume. So that’s where Portworx has always been really good at providing local high availability and failover protection for Kubernetes applications by providing replication across the cluster.
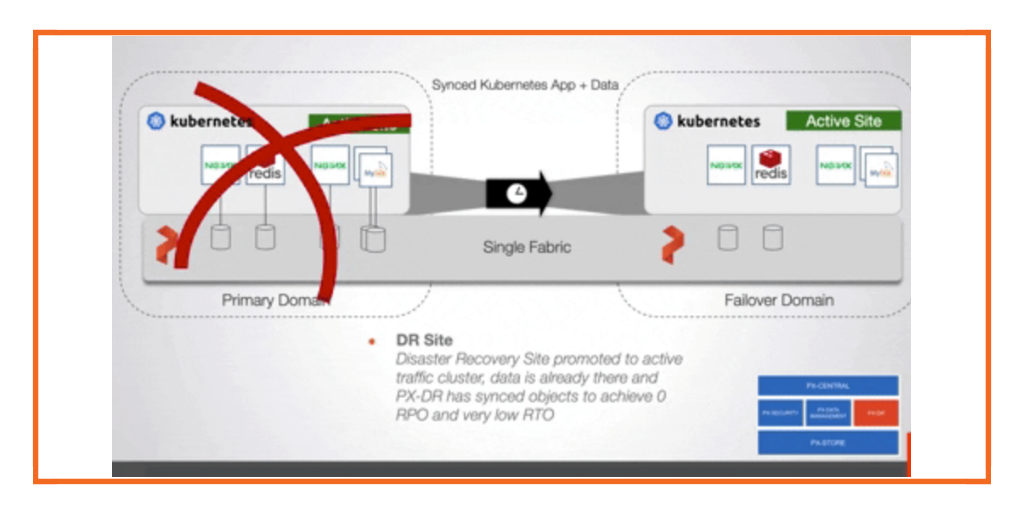
The second bit of this is disaster recovery. So this is more in the sense where you have, say you have a cluster again running Kubernetes and you have a number of different applications and those applications have volumes. Now for disaster recovery, there’s typically a primary site, so we’ll call this the primary and there is a secondary. Secondary is more generic so it can be sort of an active, active secondary, or a standby secondary. So again, you have a whole, another cluster over here basically waiting as an active or standby cluster ready for disaster to strike at the kind of cluster or data center layer and from the primary.
So what’s crucial here is that the disaster recovery mechanism can really tie these two together in terms of a pairing. It also in certain cases needs to be able to replicate data. So if you were to want to have a zero recovery point object, then you’d have to be synchronizing data across these clusters such that if a disaster happens, then the data is already available and ready to go and you can just turn on the applications. So that brings me to the applications is you need the application metadata or resources. In this case for Kubernetes, it’s all the YAML that defines the configuration of the application and this needs to be replicated as well.
So what happens is if this whole data center goes down, then automatically these get turned on, the data is already there and the applications basically you have an RTO that’s as fast as the scheduler can turn on those applications in the other application site. So this is kind of the synchronous model we’re talking about. There is an asynchronous model where it’s more of a timed mechanism. So it’s, you know, replicate my data asynchronously every 10 minutes, half hour, day, hour, whatever it may be. And that’s really just a DR scenario that is more backup based, but it still pulls the data and applications such that you can turn it on quickly so your RTO is low, but your RPO is gonna have some data loss. Thirdly, in terms of the data protection buckets that we’re talking about here, we’ve covered local HA and DR is backup and recovery. So again, you would have a Kubernetes cluster.
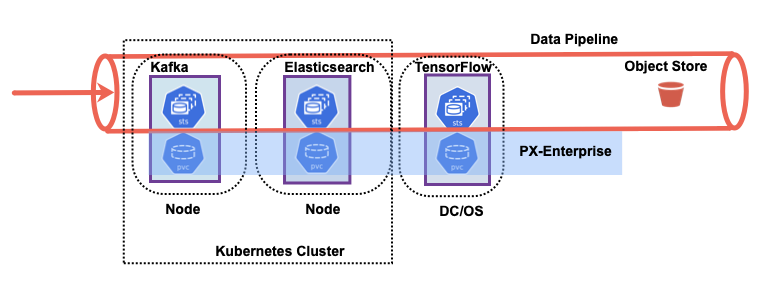
Some application or applications running on that cluster, some persistent state, and a backup is typically somewhere off-site whether that’s in a different failure domain on-prem or in a cloud-based object storage. The key here is that the backup that needs to be taken includes the data and volume, right? So this is the YAML and this is the data, and together they become kind of an application aware backup in the sense that we’re not just backing up the node in terms of a VM, we’re not just backing up kind of the entire etcd database for Kubernetes, but we’re targeting specific applications within Kubernetes namespaces and that includes YAML defining resources and persistent state. Now there is the ability to really focus in on a single application, but also broad enough where you can say go ahead and back up an entire namespace. So this could be defined at the namespace level. But in either case, this should be sent somewhere off-site to Cloud Object Storage and that can be backed up to give you the ability to restore to the same cluster in case you’re just backing up for compliance or on a regular basis or in the case that you have any issues with the cluster that you’re running backups from, you can restore it to a whole different Kubernetes cluster.
And again, that’s the backup and restore. So to recap, Data Protection buckets, we’re really talking about what different perspectives you need protection at in terms of high availability at the local availability zone or single cluster or across availability zones, then there’s a disaster recovery where a natural disaster or a security issue renders an entire data center app or our site unable to be used, so you need to turn on any active or standby site that can really get things going quickly or to have a regular backup protection scheme where you’re doing this sort of compliance or regulation and need to restore to certain points in time. So hopefully, this gives you a sense of the different data protection opportunities and configurations you have with Portworx. And definitely go take a look at PX-DR, PX-backup and obviously PX-store which hopefully you’ve tried already. But then again, if you haven’t go ahead and try out PX Essentials as well, this gives you kind of a free view of the local high availability and PX-DR and backup to read about or try PX-Enterprise, okay? Until next time, take care.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!