
Knowledge Hub
What is Kubeflow? An Introduction
Summarize Blog With
Table of Content
Developing and deploying AI applications involves a series of steps, from data ingestion and preprocessing to model tuning and deployment, each requiring a special set of tools and infrastructure. Managing these tools and processes can quickly become complex and lead to inefficiencies. That’s where Kubeflow can help.
Kubeflow provides a single platform for the entire machine learning lifecycle and ensures that your AI applications move smoothly from staging to production. Over the past year the project has also evolved well beyond classic MLOps: with its 1.11 release in December 2025, Kubeflow was officially repositioned as the Kubeflow AI Reference Platform, with a sharpened focus on generative AI, distributed LLM training, and fine-tuning at scale.
In this article, we’ll understand what Kubeflow is, how running Kubeflow on Kubernetes helps solve complex MLOps and AI infrastructure challenges, and what’s new in the latest releases.
What is Kubeflow?
Kubeflow is an open-source platform designed to simplify the deployment and management of machine learning (ML) and AI workflows on Kubernetes. It serves as the foundation for modern AI stacks, often running alongside other cloud-native technologies like KubeVirt to create a unified platform for both containers and virtual machines. At its core, it operates as a collection of microservices, making the entire ML lifecycle simple, portable, and scalable.
Kubeflow Pipelines automate end-to-end ML workflows, enabling continuous integration and delivery of models. They also support a wide range of ML frameworks for compatibility and ease of use across different environments. This helps ML practitioners focus on ML tasks without worrying about infrastructure complexities. Overall, Kubeflow helps standardize MLOps processes across the board.
Kubeflow has been a Cloud Native Computing Foundation (CNCF) incubating project since July 2023, and the community is now actively preparing the project for CNCF Graduation. That maturity is reflected in how approachable the platform has become: as of the 1.11 release, you can simply pip install kubeflow and start building AI workloads with the new Kubeflow SDK.
Why is Kubeflow important for Machine Learning workflows?
In traditional ML deployments, teams manually configure infrastructure, orchestrate training jobs, and scale serving systems, all of which are error-prone and time-consuming. For instance, a typical ML workflow might require coordinating between different compute clusters, managing GPU allocations, and handling complex data dependencies across stages.
Kubeflow simplifies this by offering a unified platform that automates the key tasks such as data preprocessing, model training, hyperparameter tuning (such as learning rate and kernel size), and deployment. This flexible architecture ensures organizations can integrate custom solutions or extend functionality through custom operators, plugins, or APIs. When teams leverage Kubeflow to build machine learning pipelines, they gain access to robust data management capabilities that enhance every stage of the ML lifecycle.
The relationship between Kubernetes and Kubeflow
Kubernetes and AI are closely intertwined, with Kubernetes providing the scalability and flexibility needed to power complex AI and ML workflows. Kubeflow builds on top of Kubernetes by offering a specialized layer designed specifically for ML workflows using Custom Resource Definitions (CRDs). Kubeflow uses Kubernetes to manage ML tasks, ensuring they can scale efficiently across multiple nodes through native features like GPU-aware scheduling and StatefulSets for distributed training.
Kubernetes portability enables Kubeflow to run effortlessly across various environments—on-premises, in the cloud, or in hybrid setups—ensuring a consistent deployment experience, and allows teams to accelerate AI workloads on Kubernetes with a build-once and deploy-anywhere approach. Recent releases support Kubernetes 1.31–1.33 directly (and down to 1.29 with native-sidecar workarounds), keeping pace with current Kubernetes versions.
Kubeflow Core Concepts
How Kubeflow Simplifies MLOps and Orchestration
Traditional MLOps workflows are fragmented and involve complex processes like manual pipeline orchestration and environment configuration. As noted earlier, Kubeflow solves this by providing a unified control plane that automates the ML lifecycle through Kubernetes-native components. It also encompasses Kubernetes features for dynamic scaling and portability across environments through standardized CRDs. This abstraction streamlines operations, enhances reproducibility, and allows teams to focus on innovation rather than infrastructure.
Key Components of Kubeflow
Kubeflow comprises several primary tools and components that enhance its functionality. Key components, in addition to the model registry, include:
- Pipelines: Composable workflow engines for managing end-to-end ML workflows through directed acyclic graph (DAG) based execution and versioning. They enable automation, reproducibility, and versioning. When a pipeline is launched, the pipeline controller breaks the task into smaller tasks, each running within a composable container, while the API server coordinates communication between components using custom controllers and operators. The latest Pipelines releases add loop parallelism and ongoing security and UI improvements.
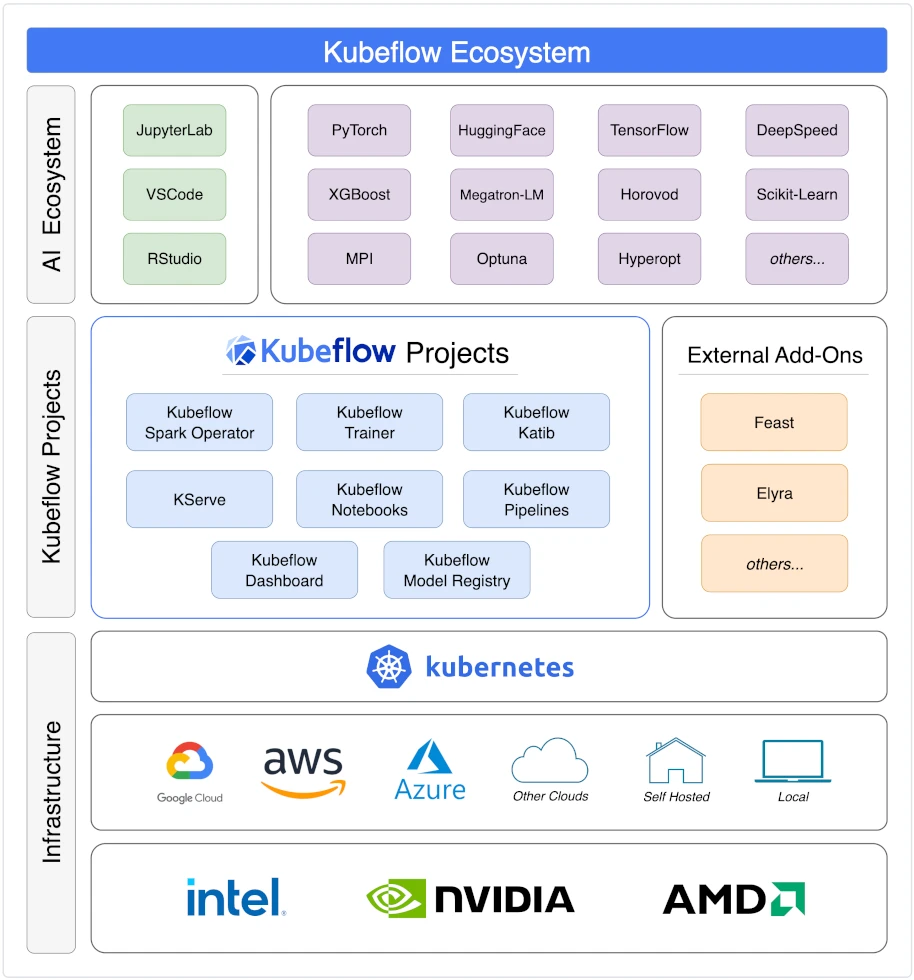
Figure 1: Kubeflow Ecosystem
- Notebooks: Shareable Jupyter notebooks that provide isolated, interactive environments for experimentation, data exploration, and model development, seamlessly integrated with Kubernetes for resource scalability. Crucially, to ensure code and datasets are preserved across sessions, each notebook instance connects to a Persistent Volume Claim (PVC) that manages the underlying storage lifecycle.
- Kubeflow SDK: A unified Python interface to train models, run hyperparameter tuning, and manage model artifacts across the Kubeflow ecosystem. Introduced with the AI Reference Platform, the SDK also enables local development without a Kubernetes cluster, so practitioners can iterate on training code locally before scaling to production.
- Dashboards: A central dashboard for pipeline management, monitoring resource usage, and tracking model performance, with support for custom visualization. It provides a complete view of user interactions across components such as pipelines and notebooks, which communicate via REST APIs.
- Katib: Component for hyperparameter tuning, model optimization, and automated experimentation with various configurations. Recent releases extend Katib with hyperparameter optimization tailored for LLM fine-tuning.
- Kubeflow Trainer (formerly the Training Operator): A Kubernetes-native distributed AI platform for scalable LLM fine-tuning and model training across frameworks including PyTorch, MLX, HuggingFace, DeepSpeed, JAX, and XGBoost. Trainer v2 replaces the older per-framework CRDs with a single, unified TrainJob API. (More on this below.)
- Model Registry: A central store for model metadata and artifacts, now with a dedicated UI, async-upload jobs, an emerging Model Catalog pattern, and deeper integration with model serving.
- Spark Operator: Now a core Kubeflow component, the Spark Operator is a Kubernetes custom resource operator for declaratively defining and running Spark applications using YAML, with hardened, rootless Istio-CNI integration.
- KServe: A production-grade model serving platform that supports multiple frameworks, scaling, and traffic management for controlled outputs. Note that KServe graduated from Kubeflow and is now a standalone CNCF incubating project; it remains tightly integrated with the Kubeflow ecosystem, with deeper Model Registry and KServe integration, a Python SDK, OCI storage, and model caching added in recent releases.
Overview of Kubeflow’s Architecture
In general, Kubeflow has a modular architecture that leverages the Kubernetes control plane to coordinate between the components outlined above. Each component runs as a containerized service, ensuring robustness, scalability, and fault isolation. This modularity allows organizations to extend functionality based on their needs—whether replacing the default model serving solution or adding custom monitoring tools—while maintaining system stability.
Recent releases have also made the platform leaner and easier to operate. Kubeflow 1.11 reduces per-namespace overhead (defaulting to zero pod overhead for idle namespaces/profiles), strengthens multi-tenant defaults, and transparently switches object storage from MinIO to SeaweedFS. Component-based Helm charts now let teams install individual pieces—such as Katib, Pipelines, or Model Registry—independently, rather than deploying the full platform.
Integrating with Popular ML Tools and Frameworks
Kubeflow supports a broad range of machine learning frameworks. Historically, the Training Operator exposed framework-specific custom resources—TFJob for TensorFlow and PyTorchJob for PyTorch—each with its own configuration. Kubeflow Trainer v2 modernizes this model by consolidating those CRDs into a single, unified TrainJob API, backed by reusable TrainingRuntime and ClusterTrainingRuntime templates.
This means a PyTorch training job, a JAX job, or an LLM fine-tuning run all share the same intuitive API, while platform administrators manage the Kubernetes-specific details separately in the referenced runtime definition. A simplified TrainJob looks like this:
apiVersion: trainer.kubeflow.org/v1alpha1 kind: TrainJob metadata: name: pytorch-simple namespace: kubeflow spec: trainer: numNodes: 2 image: docker.io/kubeflowkatib/pytorch-mnist:v1beta1-45c5727 command: - "python3" - "/opt/pytorch-mnist/mnist.py" - "--epochs=1" runtimeRef: name: torch-distributed apiGroup: trainer.kubeflow.org kind: ClusterTrainingRuntime
Figure 2: A distributed training job in Kubeflow
Pipelines can incorporate preprocessing or model training tasks using libraries like scikit-learn, and the unified API lets teams adopt Kubeflow regardless of their preferred framework, unifying workflows for diverse projects.
Where to Run Kubeflow
Kubeflow can be deployed on-premises, in the public cloud, or in a combination of both using managed Kubernetes services, allowing flexibility in choosing the environment. On-premises deployments leverage bare metal or virtualized infrastructure and are ideal for strict data privacy requirements or existing private clusters. However, these require careful configuration of network, storage, and access policies.
Public cloud deployments on managed Kubernetes services like Amazon EKS, Google GKE, or Azure AKS are popular choices. While these provide the infrastructure, many organizations seek a fully managed Kubeflow experience to further reduce the operational overhead of maintaining the ML control plane. Hybrid deployments combine on-premises and cloud for flexibility and optimized resource utilization, enabling workload portability through consistent CRDs across environments.
Deploying Kubeflow with Portworx on Amazon EKS allows seamless setup and management within a cloud-based Kubernetes framework. You can also run machine learning pipelines with Kubeflow and Portworx.
Advanced Features of Kubeflow
Distributed Training and LLM Fine-Tuning with Kubeflow Trainer
Kubeflow enables efficient distributed training of large datasets across multiple nodes through Kubeflow Trainer. The Trainer automatically handles node discovery, fault tolerance, and resource allocation, ensuring training jobs scale efficiently across GPU nodes. With Trainer v2 (GA in July 2025) and subsequent releases, the project has leaned heavily into modern AI workloads:
- Unified TrainJob API and LLM blueprints: A single API for distributed training and fine-tuning, with built-in runtimes and fine-tuning blueprints (including torchtune and the Llama 3.2 model family), plus CustomTrainer and BuiltinTrainer options.
- Parameter-efficient fine-tuning: Support for LoRA, QLoRA, and DoRA, along with broader LLM post-training enhancements.
- Advanced scheduling: Topology-aware and gang scheduling with Kueue for efficient placement of large, multi-node jobs.
- Broad framework and runtime support: PyTorch, JAX, XGBoost, MLX, DeepSpeed, and MPI/HPC workloads (including Flux Framework integration), with metrics propagation surfaced directly in TrainJob status.
- Ecosystem alignment: Kubeflow Trainer has joined the PyTorch ecosystem, reinforcing its role as a first-class home for distributed PyTorch and LLM workloads on Kubernetes.
Feeding GPUs with the Distributed Data Cache
One of the most significant additions for AI workloads is the Distributed Data Cache. It lets you stream data directly to your GPU nodes with zero-copy transfers from an in-memory cache cluster powered by Apache Arrow and Apache DataFusion. This allows teams to load massive tabular datasets efficiently, maximize GPU utilization, and minimize I/O for large-scale pre- or post-training distributed AI workloads—a key concern as GPU costs and data volumes climb. This is exactly where a high-performance data layer matters: persistent, scalable storage for datasets, notebooks, and checkpoints keeps expensive accelerators busy rather than waiting on I/O.
Using Kubeflow for Hyperparameter Tuning
Kubeflow’s Katib provides a user-friendly interface for defining hyperparameter search spaces and automates tuning by running experiments with different parameter combinations. By running parallel trials efficiently, Katib optimizes model experimentation and performance while enhancing reproducibility and team collaboration. Recent releases extend this with hyperparameter optimization geared specifically toward LLM fine-tuning.
Multi-cloud and Hybrid Deployments
Kubeflow supports multi-cloud and hybrid deployments, allowing seamless integration across cloud providers and on-premises infrastructure through Kubernetes abstractions like StorageClass, NetworkPolicy, and ServiceAccount resources. This ensures that ML workflows run consistently across environments, optimizing cost and performance.
Security and Multi-tenancy
Security has been a major theme across the 1.10 and 1.11 releases. Kubeflow now enforces PodSecurityStandards “restricted” on all system namespaces and “baseline” on user namespaces, ships multiple CVE fixes, and has modernized its service mesh with rootless Istio-CNI. Combined with stronger multi-tenant defaults, these changes make Kubeflow more suitable for security-conscious, multi-team enterprise environments.
Use Cases and Applications for Kubeflow
Optimizing ML Workflows for Enterprises
Enterprises use Kubeflow to streamline the development, training, and deployment of machine learning and generative AI applications, significantly reducing time to market.
Real-world Use Cases in Industries Like Healthcare, Finance, and Retail
A recent survey from the Kubeflow project found that 28% of developers use Kubeflow in the healthcare, finance, and retail industries, with 49% of users overall running Kubeflow in production. In these industries, Kubeflow can support the development of personalized treatment recommendations and predictive models; in financial services, it can help with predictive analytics for credit scoring or fraud detection. Similarly, retailers can use Kubeflow pipelines to develop personalized recommendation systems and enhanced customer experiences.
Supporting collaborative data science teams
Disjointed workflows, lack of standardization, and misalignment between teams often hinder collaboration in data science. With shared tools like Jupyter Notebooks, the Kubeflow SDK, and Pipelines, data scientists and engineers can collaboratively experiment, track changes in models, and streamline the path to deployment.
Challenges and Limitations of Kubeflow
Resource-Intensive Deployments and Management
Deploying Kubeflow has historically been resource-intensive, as core components like pipeline controllers and model servers demand significant compute resources and administrative overhead. Recent releases address part of this: Kubeflow 1.11 introduces zero pod overhead for idle namespaces and component-based Helm charts that let teams install only what they need. Still, large-scale clusters require careful capacity planning, which can be challenging in resource-constrained environments.
Learning Curve for Newcomers to Kubernetes and Kubeflow
New users have traditionally faced a steep learning curve—understanding Kubernetes concepts like pods, nodes, and namespaces, and how Kubeflow layers on top of them. The Kubeflow SDK and the pip install kubeflow experience meaningfully lower this barrier, letting practitioners start locally and scale into Kubernetes later. That said, operating Kubeflow in production still rewards solid Kubernetes fundamentals.
Potential Debugging and Troubleshooting Issues
Debugging and troubleshooting Kubeflow pipelines can be complex, as they require understanding multiple abstraction layers—from container logs to Kubernetes events to framework-specific diagnostics. Common issues include identifying bottlenecks in pipeline execution, diagnosing failures in model training, or managing dependencies between components. Note also that the move to Trainer v2 involves breaking changes (the Training Operator v1 source has been removed and the API group is now trainer.kubeflow.org), so teams upgrading from older versions should follow the official migration guide.
Conclusion
Kubeflow is a powerful platform that simplifies and automates ML and AI workflows by providing a unified, Kubernetes-native environment that integrates and manages the stages of the ML lifecycle. Its evolution into the Kubeflow AI Reference Platform—with a unified TrainJob API, the Kubeflow SDK, LLM fine-tuning blueprints, a distributed data cache for GPU-bound workloads, and hardened security—reflects where the industry is heading: scalable, reproducible, production-grade AI on Kubernetes.
To install Kubeflow and begin experimenting, we recommend exploring the official documentation for detailed setup instructions, tutorials, and best practices. Following a step-by-step Kubeflow tutorial is a great way to master basic workflows, such as creating pipelines, training models, or deploying them for inference. Additionally, engaging with community forums, tutorials, and support will help on the journey to implementing Kubeflow in your machine learning projects.
In parallel, get started with a free trial of Portworx to support data and storage management for your AI/ML projects and workflows.
Frequently Asked Questions about Kubeflow
Q. Why should I use Kubeflow instead of just running ML scripts on my laptop?
Running scripts on a laptop works for experimentation, but it doesn’t scale. Kubeflow solves the “it worked on my machine” problem by standardizing your machine learning workflow on Kubernetes. It allows you to build portable, scalable pipelines that move seamlessly from development to production without rewriting code. And with the new Kubeflow SDK, you can develop and iterate locally first, then scale the same code into a cluster—orchestrating the entire lifecycle (data prep, training, tuning, and serving) so your team can focus on the model, not the infrastructure.
Q. Is Kubeflow limited to TensorFlow?
No. While it started as a TensorFlow-centric project, Kubeflow is now completely framework-agnostic. Through the unified TrainJob API in Kubeflow Trainer, it supports PyTorch, JAX, XGBoost, MLX, HuggingFace, DeepSpeed, and more—including first-class support for LLM fine-tuning. Because it runs on Kubernetes, you can run essentially any framework that can be containerized, giving you the flexibility to use the best tool for your specific data science problem.
Q. What’s new in the latest Kubeflow releases?
Two releases stand out. Kubeflow 1.10 (March 2025) delivered Trainer 2.0, a new Model Registry UI, the Spark Operator as a core component, LLM-focused hyperparameter optimization, and security hardening. Kubeflow 1.11 (December 2025) rebranded the project as the Kubeflow AI Reference Platform, introduced pip install kubeflow and the Kubeflow SDK, reduced per-namespace overhead, switched object storage from MinIO to SeaweedFS, and shipped additional CVE fixes.

