
This post will answer the question “How can I run multiple Cassandra clusters on the same hosts?”
It will investigate the constraints of running multiple Cassandra clusters before showing how Portworx gives you better control over your storage, therefore providing higher density and better utilization of your compute resources.
Background
Cassandra is well known for its ability to handle some of the world’s largest database workloads. It was developed at Facebook and is now used by other web-scale companies like Instagram, Reddit, and Netflix. But Cassandra is also a beast to run, taking considerable resources to function at peak performance.
The cost of operating a Cassandra cluster can be quantified by:
- the number of compute resources in the cluster
- the amount of storage consumed by the dataset
- the network transfer between nodes & ingress/egress for connected clients
The more resources consumed by your cluster, the more it will cost. That seems obvious, but the challenge comes in minimizing the resources to run Cassandra while maintaining sufficient performance. This is especially challenging when you want to run multiple Cassandra clusters, or rings.
The simplest way to operate multiple Cassandra clusters is to use new physical hosts for each ring. But this is also the most expensive.
Instead, let’s look at two options for how we can safely run multiple Cassandra clusters on the same hosts.
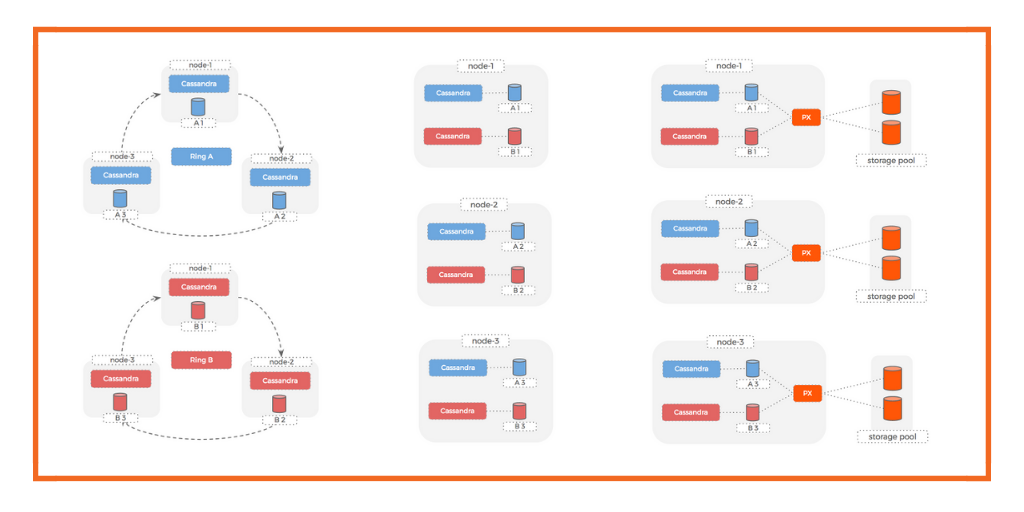
Option 1: Different clusters, different disks
When deploying multiple Cassandra clusters to the same hosts, we have to think about how we will consume our disks: Will we use one disk per container or will we manually partition the disks?
The simplest solution would be to use one disk per host, with a single partition and create a folder for each Cassandra container. Each of these folders would then be used as a Docker Volume accessible inside the container.
However, this is the most fragile solution. One problem with our filesystem or an erroneous “rm -rf” leads to problems for all the Cassandra clusters. Ideally, we would we would like to allocate a separate disk for each Cassandra container. This gives us both isolation and ease of management.
Our setup
To squeeze every ounce of performance from our Cassandra cluster, we choose to run it on bare-metal, high-spec machines.
Each machine has 32xCPU, 512Gb RAM and 2x500Gb local SSD drives. We were pleased when the delivery arrived 🙂
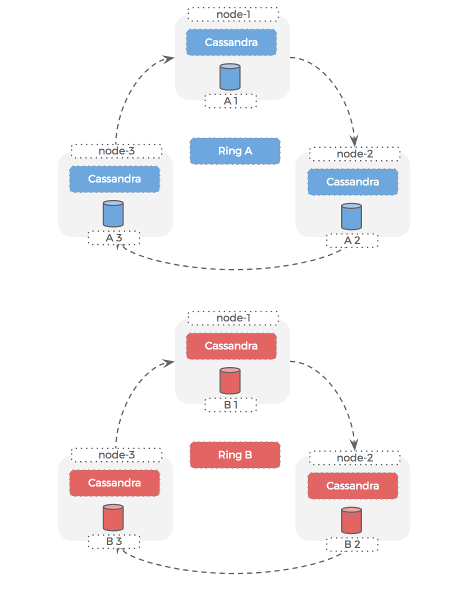
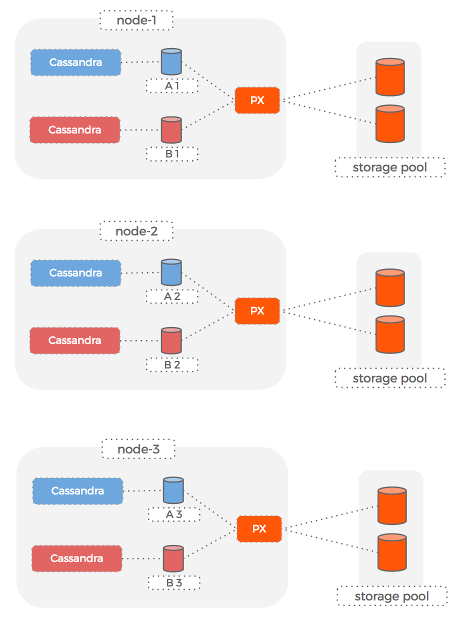
We are responsible for two production Cassandra rings that need to run on these machines, so we decide that each ring will use one of the two local SSD drives.
This gives us a strong sense of isolation between the datasets for the 2 rings. We can take a backup for one of the datasets independently of the other – because each lives on its own disk.
Here is how this setup looks:
Cassandra rings
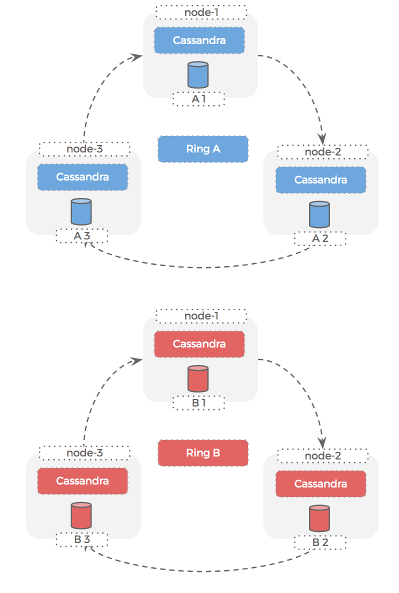
Hosts
Under-utilization
Two months into the project we take a look at our performance metrics and realize we are vastly under-utilizing our powerful hardware.
We are using only 5% DISK, 20% CPU and 15% RAM across our three-node cluster. We could be running four times the number of Cassandra rings and still have at least 20% of the resources free.
When the product team starts talking about two more Cassandra-based projects in the pipeline, we hatch a plan to run these additional Cassandra rings on the same three-node cluster. We tell finance about the cost savings and feel like a good day’s work has been done.
The problem
The next day we begin fleshing out how we are going to make this work and realize the problem:
Each node has only two block devices and we already have two Cassandra rings consuming both.
A naive solution
We think:
It’s ok – we can just buy more disks for the new Cassandra rings.
We could add two more SSD drives to each node and then each ring has its own disk again. However, our entire objective is to save money and use the same (under-utilized) hardware we already have.
Also, we remember that we are only using 5% of the existing storage and realize that buying more block devices might not be the best answer.
Option 2: Use Portworx to provide Cassandra with virtual volumes
Portworx takes the mantra of de-coupling compute from storage to a whole other level.
It pools the underlying storage and creates replicated, virtual slices as volumes that are presented to Cassandra containers.
This means we get the container-level isolation that we need, but we can use the same underlying disks for multiple clusters.
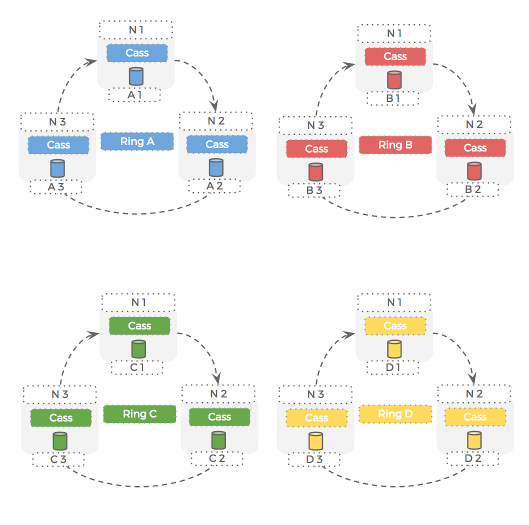
Let’s take a look at how this de-coupling of the storage pool from container volumes actually works:
Cassandra rings
Hosts
When we want to run two new Cassandra rings on our three-node clusters, we can use the pxctl command line tool to create Portworx volumes for the new Cassandra rings, or use our scheduler of choice: Kubernetes, Mesosphere DC/OS, or Docker Swarm. This is equivalent to buying, attaching, and mounting new block devices but without having to actually buy and mount any disks.
This meets our requirements for storage virtualization and our cluster now looks like this:
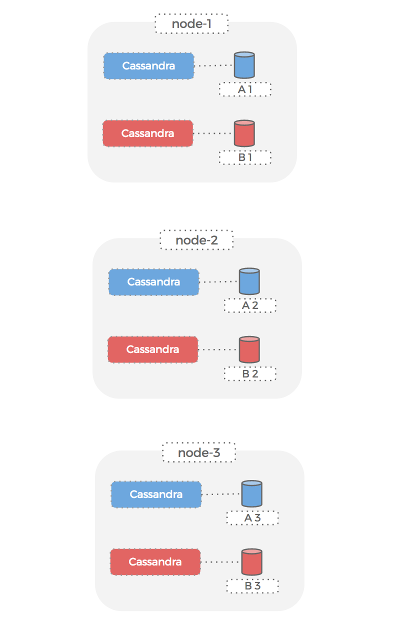
Cassandra rings
Hosts
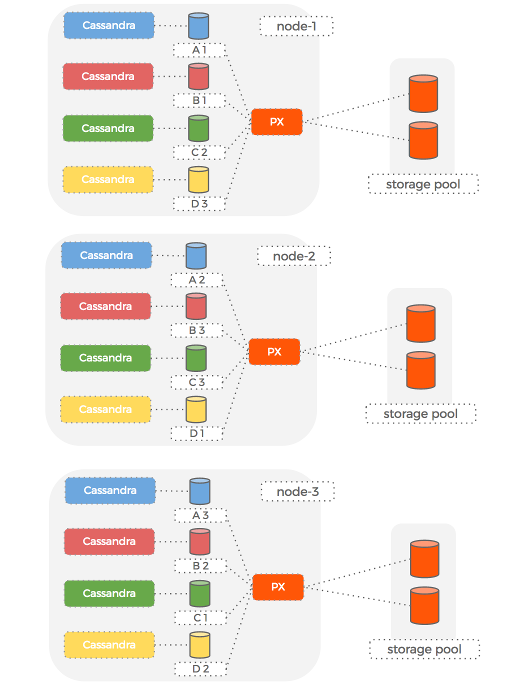
We now have four Cassandra rings running on the same hardware as our original two. Each Cassandra ring has an independent volume that can be backed-up, snapshotted, encrypted, and generally treated as an independent entity from the other Cassandra volumes.
Compute vs storage
The problem we had was a tight coupling between the number of disks and number of Cassandra instances we wanted to run, therefore causing an under utilization of CPU and memory.
We remove that coupling by using Portworx allowing us to make better use of our storage resources.
This means we can maintain the policy of container level data isolation and keep adding Cassandra rings until our CPU utilization is at the right level.
Managing storage
Our original two ring setup was using 5% of the total storage. When we double the number of rings, instead of having to double our total storage capacity (by adding new disks), we simply double the amount of used storage on the same disks.
We could keep adding Cassandra rings until our CPU utilization is at the right level for that machine.
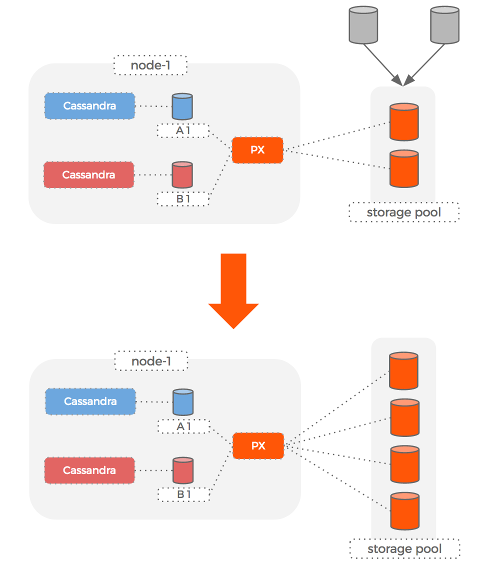
What happens if the underlying storage disks actually fill up?
This would be a problem if we were using a single block device for a single ring. If the disk fills up our only choice is to replace it with a bigger one and during this time, the node would be down.
With Portworx, because the volume being used by Cassandra is de-coupled from the underlying storage disks, we can simply add a new storage disk to the pool and then tell Portworx to increase the size of the volumes, all while Cassandra is still running.
Conclusion
Modern data centers make use of very powerful machines in an attempt to maximise their floor space / compute capacity ratio.
Unfortunately, these powerful servers with ample CPU and RAM do not come with a rack of a thousand block devices. You might have eight disks attached to a machine that is capable of running 40 Cassandra containers.
To really embrace Cloud Native Computing – we need to de-couple the underlying storage from the containers consuming volumes.
To summarize, the key to run multiple Cassandra clusters on the same hosts is:
- Use an independent stand-alone volume per Cassandra container for safety and isolation
- De-couple your underlying block devices from the volumes offered up to Cassandra
- Increase the number of Cassandra clusters per host until CPU utilization is at the right level
Hopefully this blogpost has shown you how Portworx can help you do that.
Take Portworx for a spin today or check out these additional links:
- Cassandra Docker: how to run Cassandra in Docker containers
- Production guide for running containers with Cassandra
- How to reduce Cassandra recovery time
- Cassandra Stress Test with Portworx
- Run Cassandra on DCOS
- Snapshotting Cassandra Container Volumes for CI/CD Using Mesosphere DC/OS
- Docker persistent storage for Cassandra
- Kubernetes storage for Cassandra
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.
Explore Related Content:
- big data
- cassandra
- databases





