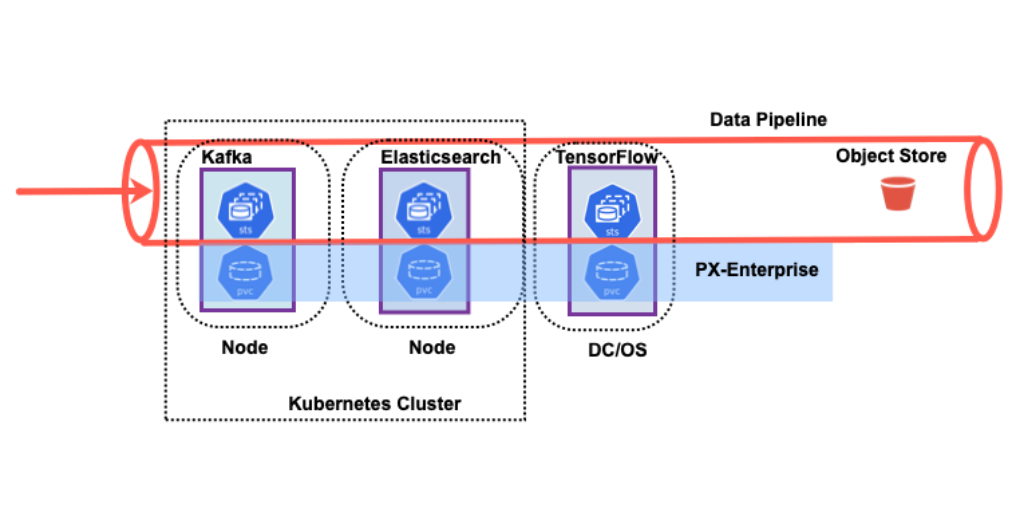
Having a resilient data pipeline for your business is becoming a necessity to stay competitive in these times where vast amounts of data are being generated and consumed. Data is not only being generated by financial and other business-related systems, but also by a whole new realm of applications built for the Internet of Things (IoT) and edge devices. The data being generated can be structured, unstructured, time series data and or, streams. Data should be captured using one system and data analysis should be performed using another system in order to maintain separation of concerns. Data pipelines can be defined as building and operating a set of data systems arranged in a composable manner for capturing, processing, analyzing, and storing business data.
Containers allow you to focus on a single area of concern, whether application-data capture, application-data storage, and/or application-data analysis. Container orchestrators like Kubernetes can help deploy, manage, and scale containerized components of modern cloud-native data pipelines. In order to create an end-to-end resilient data pipeline in Kubernetes, you have to compose a set of systems that are scalable, auto-healing, easy to observe, and easy to operate using Kubernetes orchestration.
A data pipeline can be composed of many systems, with varying scale and dimension. We will walk through a particular data pipeline composition and discuss the data pipeline elements:
- Create data or event:
- An event is created by a user or an originating system like IoT Edge device.
- Stream data:
- You want to capture the data as soon as it is generated. In this example, we are using Kafka, a durable message broker, to capture streaming data. Kafka has its own high-availability architecture using partitions and stores partition data to disks. Portworx Storage class can be used to persist data across Kafka pod restarts.
- Capture and load data:
- You can store the data in Elasticsearch in order to index, query, and analyze the data. Elasticsearch will store the data in the data nodes and will persist data across pod restarts using Portworx provisioned storage.
- Real-time analytics:
- If you are working on machine learning (ML) aspects, then you may want to add Spark or Tensorflow to your data pipeline for your ML needs. Portworx supports Tensorflow frameworks on the DC/OS container orchestrator.
- Archive your curated data:
- Store and archive your data. Portworx offers a solution called cloud snapshots, which will backup your Kubernetes volumes for long-term storage to an object store like an S3 bucket.
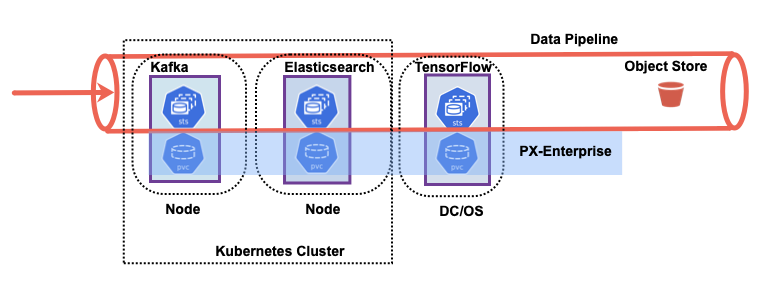
In the example above, you will notice that each stateful application in the data pipeline has its own architecture for high availability. Each application can also have varying levels of replication factors and self-recovery mechanisms. Managing data recovery at only the application layer can potentially increase the end-to-end latency of your data pipeline. Because the Portworx platform is application lifecycle aware, your end-to-end pipeline latency will remain relatively constant during application pod restarts or reschedules in a Kubernetes cluster.
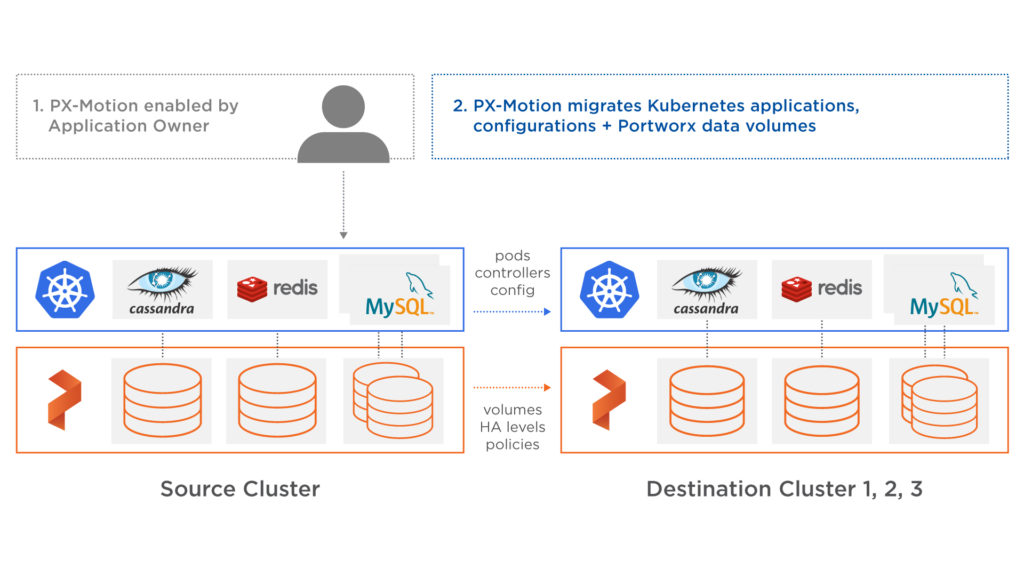
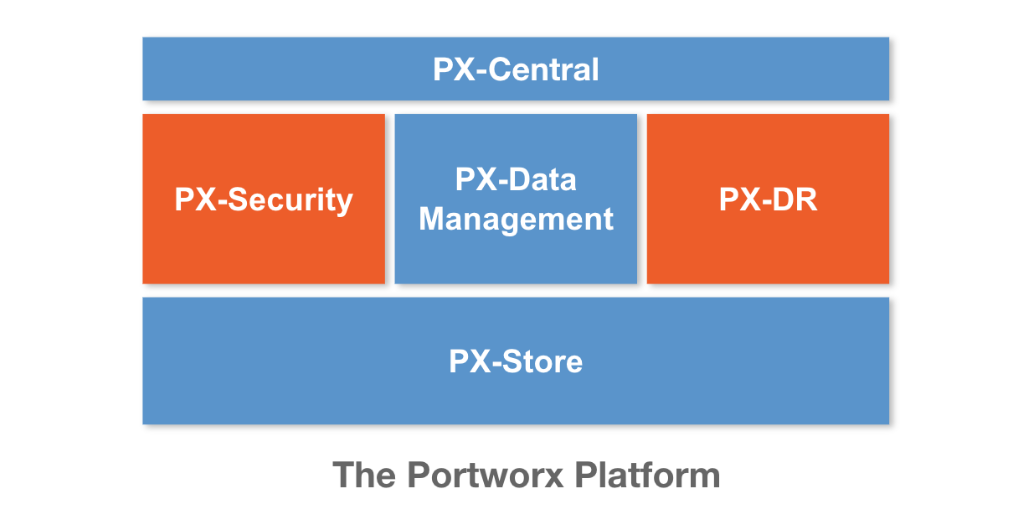
The Portworx data platform can help your composed data pipeline reduce end-to-end latency by understanding the lifecycle of the application elements in the pipeline. For instance, Portworx with PX-Motion, can help you migrate an existing pipeline element to a new Kubernetes cluster when you need additional capacity. Portworx can help the data pipeline elements with:
- Expansion of persistent data capacity
- Use of different classes of persistent storage
- Use of various replication factors for persistent stores
- Encryption at a container volume level
- Observability using Prometheus integration
- Operability by providing alerts
- Using data specific actions to take application consistent snapshots.
If you have questions about how the Portworx platform can help your organization with data protection and data portability when running on cloud native container orchestrators, please reach out to one of our Portworx experts and request a demo.
Learn more about how to run popular data workloads on Kubernetes
HA Kafka on Kubernetes
- Kafka on Google Kubernetes Engine (GKE)
- Kafka on AWS Elastic Container Service for Kubernetes (EKS)
- Kafka on Microsoft Azure Kubernetes Service (AKS)
- Kafka on Red Hat OpenShift
HA Elasticsearch on Kubernetes
- ELK on Google Kubernetes Engine (GKE)
- ELK on AWS Elastic Container Service for Kubernetes (EKS)
- ELK on Microsoft Azure Kubernetes Service (AKS)
- ELK on Red Hat OpenShift
HA Cassandra on Kubernetes
- Cassandra on Google Kubernetes Engine (GKE)
- Cassandra on AWS Elastic Container Service for Kubernetes (EKS)
- Cassandra on Microsoft Azure Kubernetes Service (AKS)
- Cassandra on Red Hat OpenShift

Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Vick Kelkar
Vick is Director of Product at Portworx. With over 15 years in the technology and software industry, Vick’s focus is on developing new data infrastructure products for platforms like Kubernetes, Docker, PCF, and PKS.