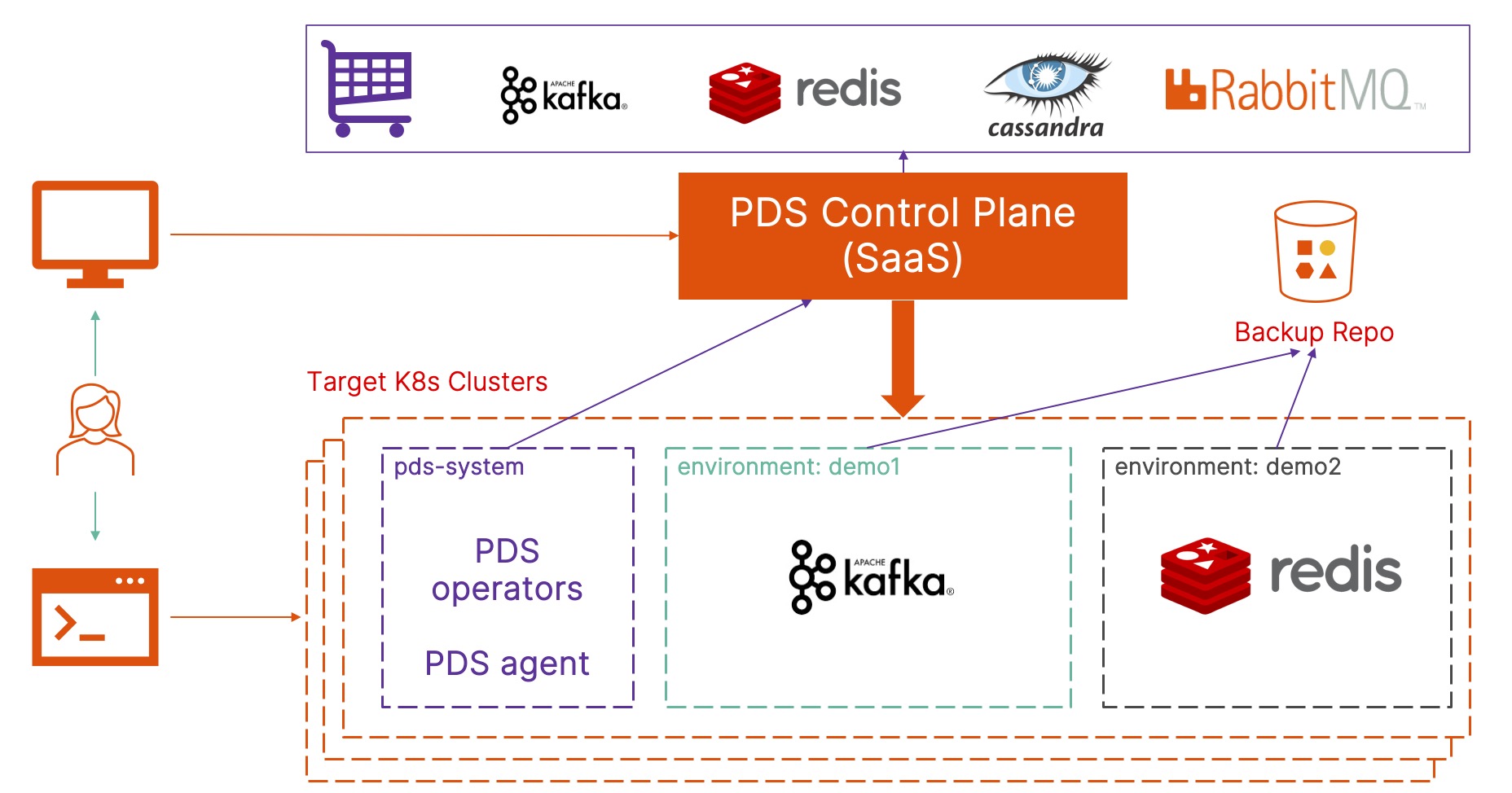
Get hands-on with OpenShift + Portworx at your own pace Try it Free


A few weeks ago, I couldn’t help but marvel at how far the cloud-native community and the industry have come. I still remember my very first Dockercon (the good old days) and how excited I was to rub shoulders with like-minded geeks who firmly believed containers represented the next wave of innovation in software development and saw how building and running software was going to change forever.
Now here we are in 2023, and we really have come a long way. While Dockercons are a thing of the past and we’ve beaten the pandemic with all the great tech we have built, I can say with certainty that Kubernetes is here to stay and is only going to be growing at an even faster clip. It’s now well on its way to being the de facto operating system for the cloud. While it’s been great to see Portworx customers adopt Kubernetes at scale, this article from Open AI perfectly illustrates that you cannot build and run modern infrastructure if you aren’t running Kubernetes—after all, ChatGPT is built on K8s!
And many businesses—large and small, old and new—recognize that if you aren’t modernizing your infrastructure and your apps, you’re essentially running a race you intend to lose.
As is true with any new technology market, especially one that’s transformative, historically there have been a lot of offerings that solve point problems. In most cases, customers would end up playing the integrators and have to wrangle with several different tools. For example, as digital technology evolved and different consumer devices proliferated, we all dealt with our digital cameras, our camcorders (Yes, I’m dating myself), our mp3 players (and Walkmans if you’re from my generation), our mobile phones, gaming consoles, and so on. But once the iPhone hit the market and showed us that it can all be nicely integrated in a platform with a great user experience and convenience, lightbulbs went on!
We’re seeing a similar trend when it comes to Kubernetes. When I look back to a few years ago, I recall several distro vendors, different networking stacks, and numerous storage offerings. Portworx itself started with a singular focus on simplifying storage for Kubernetes and containers.
But as the industry matured and as customers started running Kubernetes at a bigger scale, commercial success and adoption led to consolidation into a few successful solutions. Now we have this landscape mostly dominated by Red Hat’s OpenShift, AWS’s EKS, Azure’s AKS, and Google’s Anthos/GKE. And these offerings have essentially evolved to become the container platforms of choice for customers in the cloud and in the datacenter. The ones that didn’t evolve into a platform lost out and couldn’t hold on to their customer base.
We saw similar trends in Kubernetes storage. There were several vendors who offered similar products but didn’t evolve to be a platform like Portworx did—and, as a result, they’re no longer in the race. They’ve become relics of the past, like their digital camera cousins.
It’s clear that customers want a platform experience when they make technology choices for running their large infrastructure. In the case of data on Kubernetes, we see customers prefer a solution that delivers an overall platform experience for all their data needs that is fully managed for them but doesn’t tie them to any cloud provider. But what does a platform experience really mean, and why do so many customers prefer that?
The Platform Experience
As with our earlier example about digital devices, customers generally tend to select point products when each one meets one or two of their needs. But when the needs increase and the scale of use increases, customers tend to pivot toward products that deliver a platform experience, similar to what an iPhone delivers. Although humans are wired in a complex way, our brains crave simplicity. Simplicity drives more productivity—and what business owner in the world doesn’t want more productivity?
This is the same in the world of Kubernetes. It’s widely deployed everywhere. Today, Kubernetes manages the applications in the cloud, in the datacenter, and at the edge. Hundreds of thousands of developers build and run their applications on Kubernetes. Kubernetes platform engineering teams that support these developers are increasingly building large-scale platform infrastructure to serve these applications and provide governance. They’re increasingly being called Platform Engineers. And the platform engineering teams are almost always outnumbered when it comes to the number of developers and applications that they serve. In some cases it’s 1000:1. Yes, that’s how lopsided the ratio is—and that’s why they’re my superheros and that is why I feel the Portworx mission is so important.
For any platform engineering team to be truly successful, to scale with their customers’ needs without becoming severely overworked and burned out, they need products that deliver the entire platform experience—not point solutions that they have to integrate and manage.
This is especially true when it comes to the world of data on Kubernetes. There were and still are some basic storage solutions, some backup solutions that only do backup or have repainted their VM-based backup solution for containers and numerous database offerings (open source and commercial, hosted and self-managed) that the developers and the platform teams have to wrangle with.
As we worked with our customers and the community more, we could easily see that they were dealing with this at scale. They were working with storage providers, backup vendors, database vendors, and cloud vendors all at the same time, and, in many cases, the integration point for all these technologies was the customers’ container platform. Imagine supporting thousands of applications, developers, and infrastructure nodes and then having to deal with so many vendors all at the same time.
This is why we made the decision a couple of years ago to morph Portworx into a cloud-native data platform for Kubernetes. We already had many pieces in place, and our customers were using our data storage product, PX-Enterprise, as a large-scale data management platform. But we quickly learned that this was not enough. Our customers were craving a complete solution for all their data needs.
As they onboarded more and more apps to their Kubernetes platform, they wanted a solution that could manage their entire application and data lifecycle. They wanted greater security and multi-tenancy. They wanted to support various services without getting bogged down into the finer details of each service, to be able to ensure business continuity for their customers, to make sure they were complying with regulatory requirements, and so on. This is when we realized that what customers need is a complete platform experience that eliminates their pain of having to use different tools to build the solution they want. They need the ability to let their application teams fully own the operations for their apps while still staying compliant with their SLAs, cost estimates, and regulatory requirements.
But what is a platform experience? And what does a true cloud-native data platform look like? And why do customers need it to be successful in delivering a rich application experience to their end users?
Let’s examine some of the capabilities a cloud-native data platform delivers to our application and platform superheroes to give them even more power.
It enables self-service deployment and management for application teams
When you’re serving a large number of customers and applications, it’s extremely important to deliver a self-service experience where the users can consume the major capabilities of the platform without intervention from the platform administrators. And when a large community uses the product, it’s critical to have enterprise-class role-based access control.
For example, with the Portworx platform, a developer can fully manage their application deployment storage characteristics, set policies, take backups, and move their apps and data to and from anywhere without ever having to file a ticket or wait for someone else to do it for them. This is true DevOps at scale.
It enables application teams to manage the complete data lifecycle from birth to archival on cloud or on-premises
Each application is built differently, and developers in each organization use a myriad of services and databases. As these applications generate volumes of data, it gets really hard for the platform engineering teams to determine which data is important and which isn’t. A cloud-native data services platform must enable self-service data protection like snapshots and clones as well as backups off the Kubernetes cluster. It also must provide complete visibility to both the developer and the platform engineer on the available backups and the ability to restore an entire namespace or just an application through single click or a command.
With the Portworx platform, developers can self-service back up their namespaces and projects, and platform engineering teams can set broad policies to govern the backup frequency, data retention, and even the destination of where the backups should be stored.
It enables platform teams to manage at scale through autonomous, policy-driven data management
The example I gave above with Open AI’s deployment isn’t uncommon in the cloud-native space. We routinely see customers pushing the limits on cluster sizes. There are Portworx customers who run thousands of nodes in a cluster and run hundreds of clusters with hundreds of nodes. Kubernetes runs at staggering scales, and managing data on Kubernetes at that scale requires more automated management of the data infrastructure, capacity allocation, and performance management with little to no user intervention.
The Portworx platform delivers this through its Portworx Autopilot functionality, which can monitor and manage large-scale clusters, dynamically manage capacity, and balance the applications in a Kubernetes cluster to deliver the best utilization.
It provides a curated catalog of different data services with zero touch day 2 operational management
As we all know, development of any application requires creating multiple iterations, trying out different methods and schemas, and testing a lot of sample data sets that mimic production. When running these applications in production, these data services also need to be administered properly, and often the application teams heavily rely on data services teams to keep these data services up and running.
The Portworx platform includes Portworx Data Services, which delivers single-click deployment with fully automated day 2 management of 12 different data services as of August 2023 (with more coming every quarter). It can also handle thousands of database instances on any cloud with little to zero user intervention, essentially putting database management on autopilot with a single pane of glass across all clouds. In a hybrid cloud environment, this significantly reduces the operational complexity and frees up platform engineers from having to be responsible for different data services. It also reduces DBA fatigue from having to administer so many data services, provides application owners total control and transparency over the data sovereignty, and gives line of business owners complete control over the costs. Plus, it enables development teams to spin up as many instances of their test data sets and test out different versions of the software instantaneously without expensive setup time.
It enables application owners to defy data gravity with application-aware app and data mobility
In many cases, what holds rapid application prototyping and development back is the infrastructure. We often find developers trying to build modern applications on outdated infrastructure. They end up MacGyvering solutions because they’re just victims of the infrastructure they run on. They’re held back from delivering great customer experiences because it’s exponentially harder to deliver application experience closer to where their customers are because they’re limited by what their infrastructure can support. Platform teams often struggle with keeping their infrastructure up to date as a result.
A true cloud-native data platform gives customers the ability to create a global data fabric, which enables applications to be deployed and to run everywhere. This enables easy mobility of applications from one infrastructure to another, from data center to cloud and vice versa, across different clouds, and between different versions of hardware and software infrastructure. When mobility increases, productivity increases and value creation accelerates.
It ensures business continuity and disaster recovery at an application level
Imagine an app store where app owners bring an app to the store, but it’s up to the store to manage that app in production. Managing the hundreds of thousands of apps being delivered through the app store is simply unsustainable at scale. But this scenario plays out regularly when large enterprise DevOps platform teams end up supporting thousands of apps across hundreds of development teams. Providing different app SLAs is a logistical nightmare.
A cloud-native data platform delivers application-aware and application-consistent business continuity and disaster recovery so each application owner can easily define how and where their application instances are deployed and what kind of SLAs—commonly called RPO (Recovery Point Objective) and RTO (Recovery Time Objective)—the application requires and get it at the granularity of each app. This provides tremendous control back to the application owner and frees up the platform team from having to understand and manage different application DR needs.
It delivers tangible operational cost savings as the scale of the platform operations increase
The true cost of any solution is never obvious at a smaller scale. For example, it’s easier to control the design and cost when you print 100 copies of a newsletter or a magazine, but it gets a lot harder to control costs when you have to print a million copies and manage the supply chain, manufacturing operations, the quality of the ink and printing, and the logistics of storage and distribution.
Similarly, the cost of managing one or two applications over a few instances isn’t the same as managing thousands of applications on hundreds of thousands of instances. The sheer scale of operating and managing applications in production can cause serious cost overruns, overwhelm an organization, and significantly burden the platform teams—and that affects the application team’s productivity as well.
A cloud-native data platform like Portworx helps rein in the expense by delivering infrastructure cost savings through a pay-as-you-grow model as well as operational cost savings by automating 90% of the day 2 workflows, thus reducing the operating expenses burden of maintaining a large platform team to run and manage apps in production.
Provides end-to-end observability from application to underlying media in a single pane of glass
One common thing I see platform teams struggle with is being able to understand how their applications are performing and where to look when there’s an issue. There’s no shortage of dashboards in our industry, and most show information that isn’t relevant or very useful.
Customers need to understand how the applications are performing, what are the throughput and latencies experienced by the application, what is the rate of growth storage, how their backups are working, and how the underlying media is performing. This is especially important in a cloud environment where the performance of the underlying cloud devices can be unpredictable at times.
A cloud-native data platform helps customers measure performance from the application level and provides the ability to drill down to the individual infrastructure components, including CPU, memory, and I/O devices. It integrates natively with the customers’ dashboards and other observability tools by continuously exporting all the relevant metrics. In short, it gives the application owner and the platform engineer total visibility into the efficiency of the application infrastructure and helps them run the application in the most efficient manner.
Summary
“When you focus on solving the whole problem, you uncover opportunities and insights that may be missed by those who only see parts of it.” —Elon Musk
This is what we did with the Portworx platform. While others were looking at the parts, we decided to step back and look at the problem as a whole. As Kubernetes continues to barrel forward as the technology of choice for this decade, and as cloud continues to be abstracted under Kubernetes, we understand the best way to unleash the power of Kubernetes is to deliver an end-to-end cloud-native data platform that is built for the application teams that run their applications in Kubernetes and for the DevOps platform teams that manage applications at scale—so they can deliver their apps at faster speeds than ever before.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Venkat Ramakrishnan
VP of Product and EngineeringExplore Related Content:
- platform