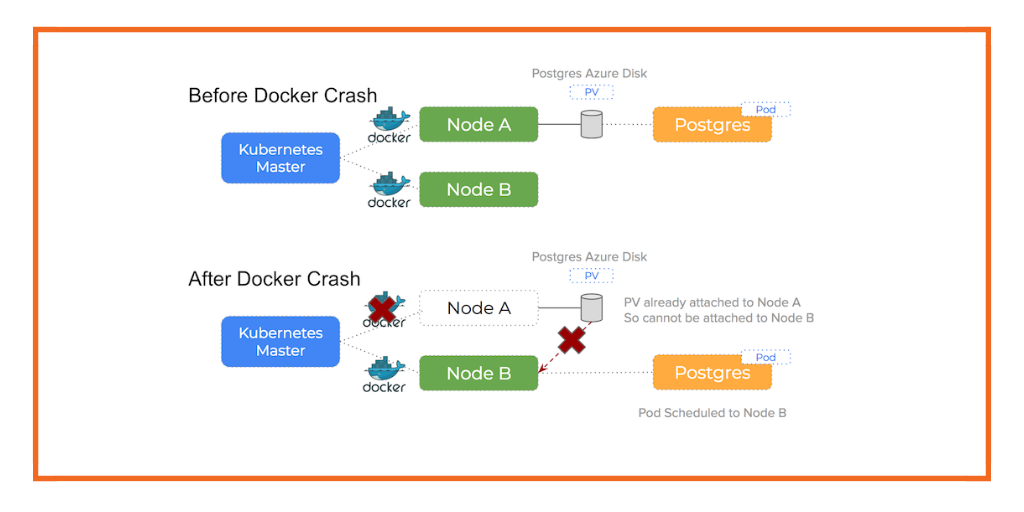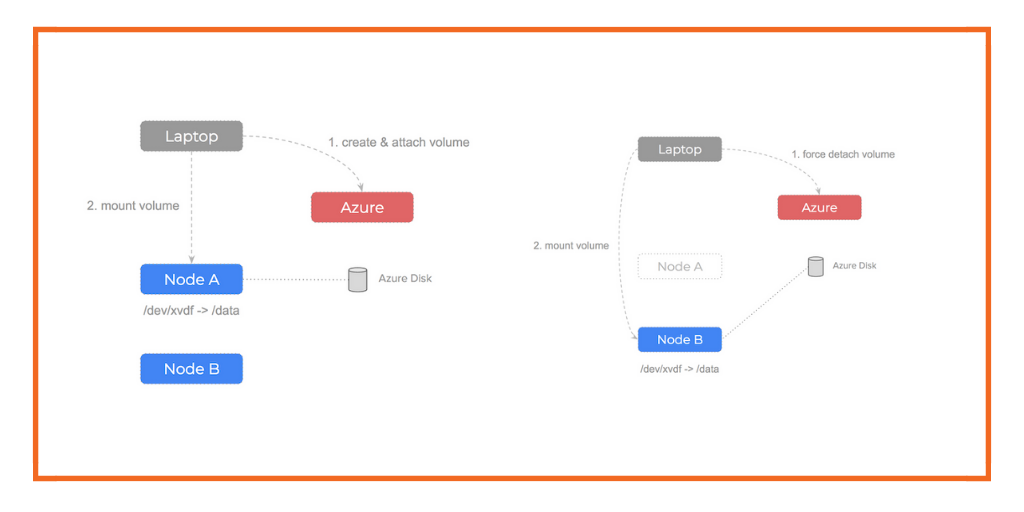
This is a micro-blog that is part of a series of posts regarding common errors that can occur when running Kubernetes on Azure.
Being the leader in running production stateful services using containers, Portworx have worked with customers running all kinds of apps in production. One of the most frequent errors we see from our customers are Failed Attach Volume and Failed Mount which can occur when using Azure Disk volumes with Kubernetes.
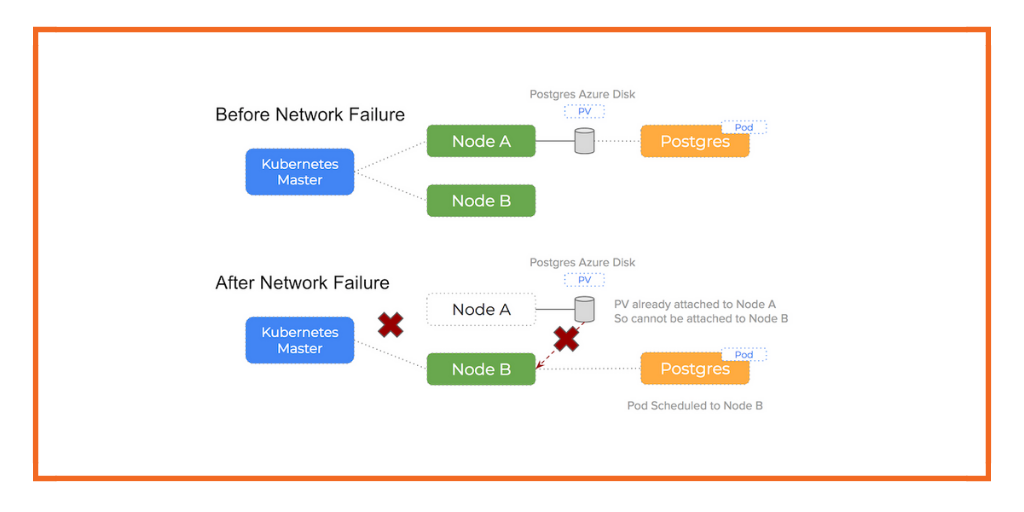
This post zooms in on errors that can happen when either a network partition or underlying hardware failure for a network interface card happens. In this case, the Kubernetes master can no longer assert the health of the node and the pod will be re-scheduled to another node which can result in Failed Attach Volume and Failed Mount warnings.
Network partition on Kubernetes
Networks are notoriously unreliable and there are various failure modes that can affect the health of a cluster. The Split Brain situation is a major source of problems for distributed systems and happens when one part of the network becomes out of communication with another.
At a lower level – a network card failing at the hardware layer or an IP mis-configuration can lead to a one part of the network unable to communicate with another.
The problem with network issues like this when using Azure disks on Kubernetes is that the disk is still attached to an otherwise healthy node but the Kubernetes master is unable to see the node and cannot know it is healthy. This will trigger a re-schedule event that will lead to another pod being scheduled to a healthy node. Now are are in the following situation:
An Azure disk volume that is already attached to a node is attempting to be attached to a second node and a single disk cannot be attached to two nodes at the same time
In our tests – we simulate a network failure by adding some evil firewall rules ($ iptables -A DROP) which leads to no traffic able to be sent or received to that node. When this happens, the kubelet is unable to communicate its status back to the Kubernetes master and is thus dropped from the cluster and all its pods are rescheduled to other hosts.
However, when attempting to attach the Azure Disk volume to this new, healthy node, as we have discussed, Azure views the volume as currently attached to the old node and we are essentially trying to attach to two nodes at the same time.
It’s important to know that Kubernetes will not force detach the Azure disk and so we get stalemate.
You can see how this happens in the following diagram:
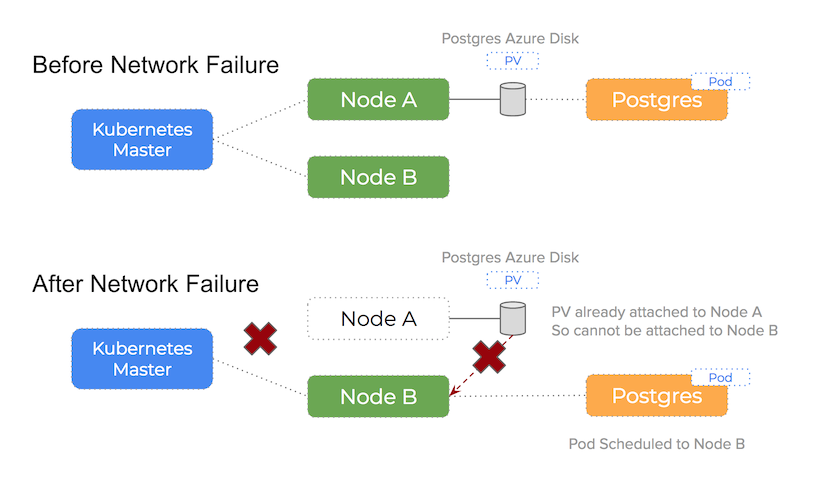
A TLDR of the problem:
When an event occurs that requires a pod to rescheduled and the scheduler chooses a different node in the cluster, you will not be able to attach the Persistent Volume to a new host if Azure sees the volume already attached to a existing host
We see 90% of Azure issues using Kubernetes happen because of this issue. Because the Azure Disk volume is still attached to some other (potentially broken) host, it is unable to attach (and therefore mount) on the new host Kubernetes has scheduled the pod onto.
Error Output
When you see a network partition, you will see the following error output:
Warning FailedAttachVolume Pod 111 Multi-Attach error for volume "pvc-d8269936-27f2-11e8-bbb9-0022480128db"
Volume is already exclusively attached to one node and can't be attached to another
Warning FailedMount Pod 1 Unable to mount volumes for pod "mysql-app-1467715154-1jv5b_ready30killnetwork(fa38d4cb-27cb-11e8-8ccc-0022480745ca)":
timeout expired waiting for volumes to attach/mount for pod "ready30killnetwork"/"mysql-app-1467715154-1jv5b". list of unattached/unmounted volumes=[mysql-vol-undefined]
Warning FailedSync Pod 1 Error syncing pod
As you can see, the two errors Warning Failed Attach Volume and Warning Failed Mount are displayed because of the quite helpful error description:
Volume is already exclusively attached to one node and can’t be attached to another
This error is a case of does what is says on the tin and captures the overall problem nicely.
Portworx and cloud native storage
To understand how Portworx can help you to avoid these problems – please read the main blog-post.
In summary:
An entirely different architectural approach is taken by Portworx. When using Portworx as your Kubernetes storage driver running on Azure, this problem is solved because:
An Azure Disk volume stays attached to a node and will never be moved to another node.
Conclusion
Again, make sure you read the parent blog-post to understand how Portworx can help you to avoid these errors.
Also – checkout the other blog-posts in the Azure series:
- Docker daemon crashed or stopped
- Update affinity settings or node cordon, forcing a reschedule
- An Azure node failed
Take Portworx for a spin today and be sure to checkout the documentation for running Portworx on Kubernetes!
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!