
Snapshotting Cassandra Container Volumes for CI/CD Using Mesosphere DC/OS

In a previous post, we saw how to set up Portworx on DC/OS using Mesosphere Universe. In this post, we’ll take that a step further and look at a real-world scenario where we use Portworx to snapshot Cassandra container data volumes to use as part of your CI/CD system.
Background
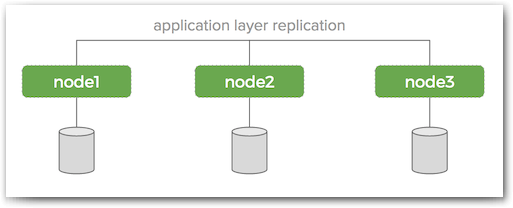
Running distributed databases such as Cassandra give you a fault-tolerant solution for your database storage.
You can safely use local disks for your Cassandra cluster. Why? Because if one of the nodes dies — even though it takes the disk with it — the cluster has replicated all of the data at the application layer.
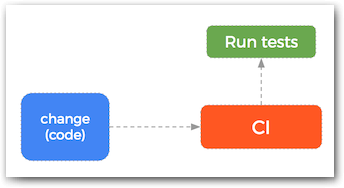
As you build features or versions of your application, it is important to test how those changes will affect performance and functionality of your app. Typically, a developer will change some code and then do $ git push. Based on this trigger, the CI system runs the test suite and you get the feedback that is most important: “did the change that the just happened break anything?”
CI means we can be sure that changes to our code do not break the system.
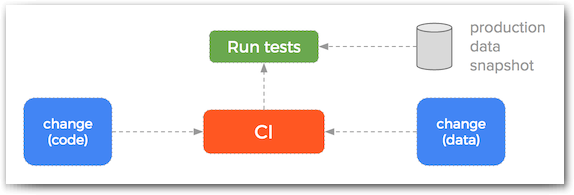
But data can cause failures too
It turns out that developers making code changes is not the only mutation we need to account for — data also changes. And this interaction of data and code can cause your application to fail. Think about a website form to take online orders. It might work fine for most users, but will fail if a user enters an email address with non-English characters. Just testing code and a small subset of synthetic test data won’t catch this type of error.
In an ideal world, we would be constantly testing our apps against production data. This means we could catch errors that come from production data that we did not anticipate in our test fixtures. At the very least, we should regularly test our app at $ git push time against realistic data so that the smallest number of bugs get through.
Bi-directional CI
To solve this problem, we can regularly test against the latest production data. To do this, we need a tool that can safely snapshot production data and present this volume to a Docker container so we can safely run our test-suite against it.
Using Portworx to tier and snapshot Cassandra data volumes
Using Cassandra alone, this would be a challenge. Cassandra replication works great for our production environment, but for testing what we want is a copy of this data in a separate environment. We don’t need the synchronous replication that Cassandra provides for that and chances are, we don’t need to run our CI environment on the same high-performance storage our production systems run other either.
Instead, we can use Portworx as the storage layer for our Cassandra data volumes. Portworx can provide high-performance container-granular storage for our production cluster (for example, SSDs) and lower-cost magnetic disk for our CI. With this set up, Cassandra can still provide its own replication in the production cluster, but we can also take snapshots of the production data and use the snapshots to run our test suite against. Compared to using Cassandra alone, this means:
- Snapshots can be scheduled for automation.
- The test suite has production data only seconds old.
- Storage resources are allocated more efficiently by using storage tiers.
- We catch errors that we had not anticipated in our tests.
- Our test suite can safely write to the database because it’s a snapshot.
Demo time
In the demonstration video, the following scenario unfolds.
Guestbook application
We have a simple guestbook application and everything is is running smoothly. We are running our app on DC/OS and have a Cassandra database so we don’t need to worry if a node dies. Our data is safe.
We notice that the API is returning an unfavorable data format and decide to make a change. We make the change and push the code to our CI server. The tests pass and we check the results in the deployed application.
Everything is working and we have a good feeling about doing DevOps right. Every time we make a change, we test it and only deploy to production if our tests pass. We head off to bed and will plan out the next product features tomorrow.
The next day, everything is broken
The next morning we notice the site is broken. Nothing is loading and we start to think:
“But all my tests passed last night – what could have changed?”
We start to dig around and notice that a user had typed a bad character and our code breaks.
Our test suite inserts dummy data into a Cassandra database and that is how our test suite did not pick up this problem; it only existed in the production system.
The realization that we need to test against both the latest code and production data hits us.
Portworx snapshots
Thankfully, we have backed our Cassandra database onto a data layer provided by Portworx. This makes it easy to take a snapshot of our production data and use it for our tests.
We modify our tests and CI config to use this volume when running the test suite. This time when we push the code, the test suite catches the error and now everything makes sense.
We fix the error, the test suite passes and our app is back up and online.
Gitlab config
Our .gitlab-ci.yml before adding Portworx snapshots:
before_script:
# start a cassandra container
- "docker run -d --name cassandra_test_${CI_BUILD_ID} cassandra"
Our .gitlab-ci.yml after adding Portworx snapshots:
before_script:
# create a snapshot volume
- "docker exec $PXCONTAINER /opt/pwx/bin/pxctl snap create --name app-ci-test-${CI_BUILD_ID} app-production"
# start a cassandra container with the snapshot volume
- "docker run -d --name cassandra_test_${CI_BUILD_ID} -v app-ci-test-${CI_BUILD_ID}:/var/lib/cassandra --volume-driver pxd cassandra"
This setup has a number of advantages that maximize for performance in production and flexibility in testing:
- Portworx storage tiering allows us to run our production system on high-performance storage and our CI system on lower-cost disks.
- We leverage the built-in replication provided by Cassandra in our production system.
- And separately take snapshots of Cassandra to use in our test environment. These snapshots can be scheduled for full data automation.
See Also
For further reading on Cassandra
- Cassandra Docker: How to run Cassandra in Docker containers
- Run multiple Cassandra rings on the same hosts
- Run Cassandra on DCOS
- Snapshotting Cassandra Container Volumes for CI/CD using Mesosphere DC/OS
To return to running Cassandra in Docker Containers
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.
Explore Related Content:
- cassandra
- ci/cd
- dc/os





