





This post is part of our ongoing series on running MongoDB on Kubernetes. We’ve published a number of articles about running MongoDB on Kubernetes for specific platforms and for specific use cases. If you are looking for a specific Kubernetes platform, check out these related articles.
Running HA MongoDB on Red Hat OpenShift
Running HA MongoDB on Amazon Elastic Container Service for Kubernetes (EKS)
Running HA MongoDB on Google Kubernetes Engine (GKE)
Running HA MongoDB on Azure Kubernetes Service (AKS)
And now, onto the post…
In a previous blog, we talked about How to Run HA MongoDB on Portworx. In that post, we demonstrated that you could use Portworx as a Kubernetes storage provider to perform synchronous replication of MongoDB data and automate data management tasks like snapshots, backups, volume resizing and even encryption.
In this post, we will present you with data points to help you understand the difference between using Portworx replication and MongoDB replication and even a combination of both forms of replication in order to achieve the highest level of availability in the most efficient manner possible.
We will demonstrate that using Portworx significantly improves MongoDB workloads running in containers in two ways: faster failover times and decreased resource utilization.
Thanks to Persistent Volume Claims in Kubernetes, when a host running our MongoDB pod fails, Kubernetes will reschedule it to a new host. When you use a external block device like Amazon EBS or Google Persistent disk, that failover operation includes detaching the block device from the original host and remounting it to the new host. As we’ve written in the past, that operation is slow and can lead to stuck volumes.
TL;DR- in testing failover on MongoDB, Portworx enabled Kubernetes to failover a MongoDB pod 300% faster, taking only 45 seconds, compared to 180 seconds.
Portworx provides a general purpose container volume replication technology that can be leveraged to provide high availability for any database. Our test clearly show that this is not only good for the operational simplicity it brings but that it is also much more efficient at replicating data than any database technology ever will be.
The reason is simple, MongoDB writes all operations on the primary to an oplog and then synchronizes the secondaries by executing all operations from the oplog in the primary in order. What Portworx does is replicate the blocks containing the resulting changes once the operations are processed therefore reducing the CPU and RAM required to replicate data.
Our tests show that with replica sets, MongoDB failed over as quickly as using Portworx, but that it required 3x the number of pods for the same level of reliability! In other words, replica sets, in addition to being more complex to set up and manage, require more compute resources to provide the same level of reliability and failover as Portworx.
TL;DR- Using Portworx to run MongoDB reduces compute costs significantly while speeding up failover.
Here are the results of the test. Read on for the full methodology and analysis.
| Configuration | Failover (seconds) | Failover Improvement (%) | Number of records written | % Improvements | Number of pods required |
|---|---|---|---|---|---|
| MongoDB + GKE Persistent Disk | 180 | 15,343 | 1 | ||
| MongoDB + Portworx | 45 | 300% | 49,014 | 319% | 1 |
| MongoDB + Replica Set + GKE Persistent Disk | 45 | 300% | 45,169 | 294% | 3 |
This section details the methodology that we used to get the results outlined above. In the test we want to measure two main things:
Additionally, we are interested in understanding if running Portworx cloud native storage volumes for MongoDB would improve either or both of these measures.
To test the failover time of MongoDB on Kubernetes with and without Portworx we built a simple Spring Boot application that implements the Spring Data MongoDB and Spring REST HATEOAS projects to implement a simple REST API for a Person repository.
This REST API, along with MongoDB is deployed to Google Compute Engine (GKE) and tested using the Restlet client to create 2 records before running the failover test and validate that these records were not lost during the failover.
To test the failover performance under load we chose to use the Load Impact load-testing tool. The following diagram depicts the first scenario where we are simply testing GKE using Google Persistent Disk for storage instead of Portworx:
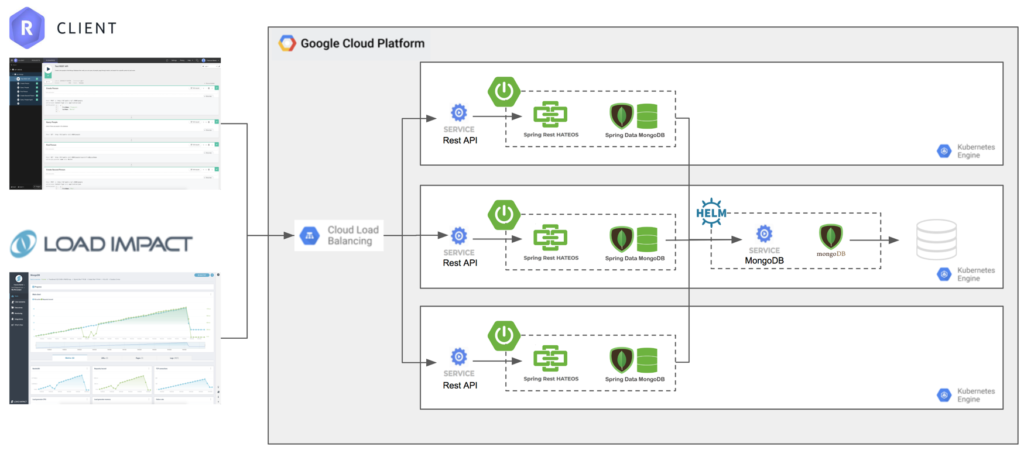
With this configuration we ran a 5 minute test with virtual users (VUs) being gradually added until a total of 50 are running at the end of the 5 minute test. Each virtual user submits 25 new Person entries with randomly generated first and last name every second and queries for all People every second (Spring Data MongoDB has the intelligence to page results so this doesn’t send back every Person in the database).
To test how long it takes to failover under load, the GKE node running MongoDB is deleted when we reach roughly 15 virtual users and at the end of the run we use the Restlet client to validate that our records are intact.
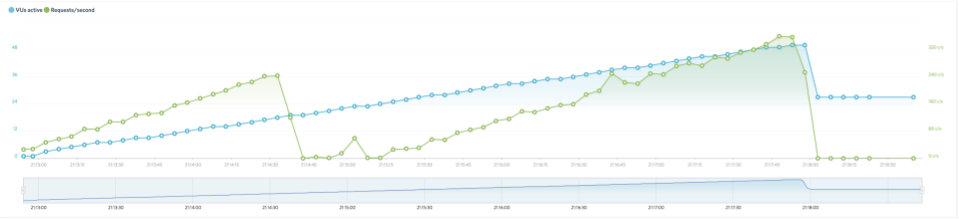
The following diagram shows the results of the first run (the blue line shows the number of virtual users and the green line shows the number of requests per second being measured by load impact):

The test showed that GKE took too long to restart MongoDB to handle any requests after the GKE node where it was running was deleted. It took roughly 3 minutes for the MongoDB database to be available again and once it did we were able to validate that our 2 seed records were not lost during failover. GKE dynamically created a disk for MongoDB and remounted that disk after failover, keeping the data intact. So, while we didn’t lose any data (good!), our app was unavailable for 3 minutes (bad!).
We then ran the same test but with Portworx as the storage class provisioner for MongoDB instead of Google Persistent Disks. This configuration included 3 replicas and is depicted in the below diagram:
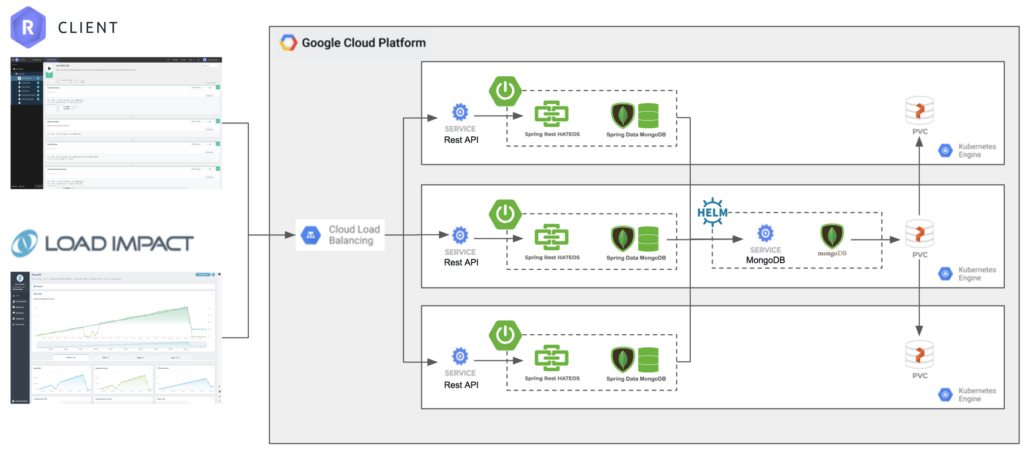
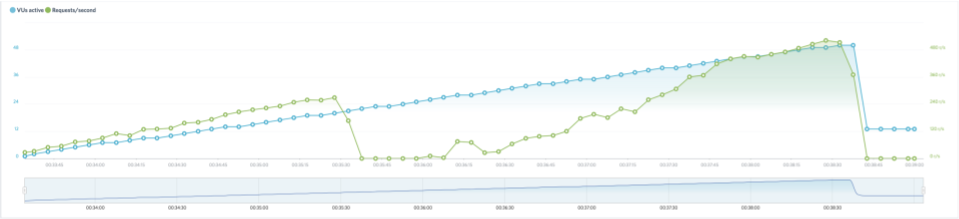
This time the failover was much faster and the load impact tool was able to resume sending requests after just under one minute of downtime (45 seconds). The results are shown here:
Finally, we tested running a MongoDB replica set deployed using the Kubernetes stateful set helm chart and backed by GKE storage. In this configuration MongoDB is replicating the data:
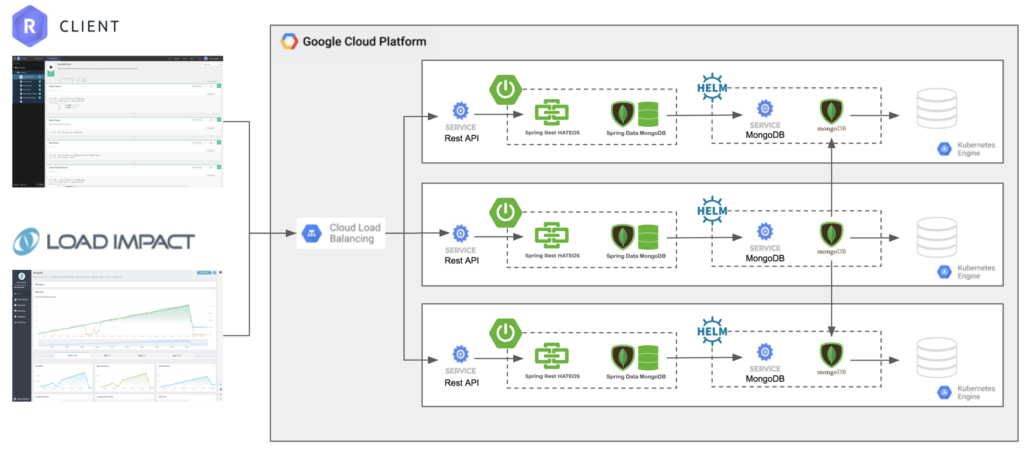
The results of the test with MongoDB replication were similar to the results with Portworx replication (45 seconds to failover) and the graph is shown here:
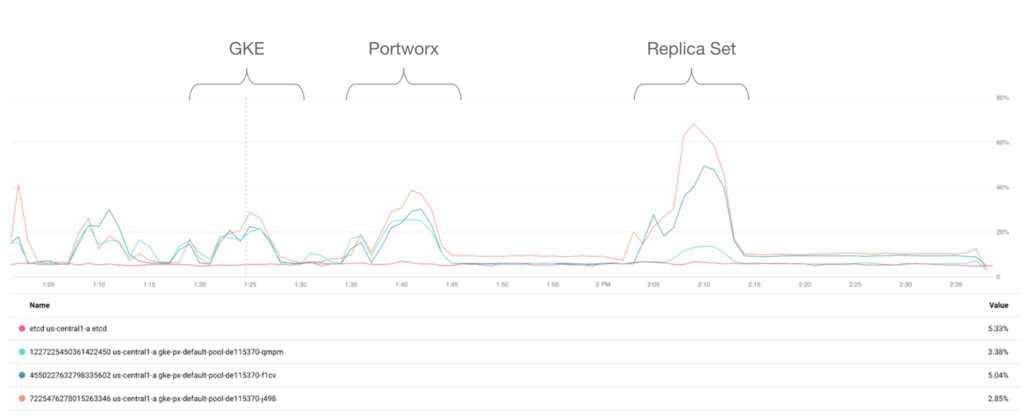
Finally, we measure GKE resource utilization during all three test runs and it clearly shows that, as expected, running a stateful set consume a lot more CPU. Here is the graph from Stack Driver after all three test runs:
These tests looked at MongoDB but we’ve seen similar outcomes from customers running Kafka, Cassandra and other SQL and NoSQL databases. Portworx replication works for all of them and provides a very efficient way to provide replication in addition to all the value it brings to the “day 2” operations of stateful applications in production and the automation of DevOps processes for data management tasks. We hope to share more data on these use cases in the future.


