

Mining crypto-currencies is by definition a competitive business. There are thousands of computers all trying to win the lucrative reward for mining the next block and because of the intensive nature of the proof of work algorithm – the more performance your computer has, the more likely you are to find that elusive winning hash.
This means that any amount of performance you can squeeze out of your infrastructure can turn into profits in the form of block rewards. This becomes especially true if you run mining nodes at scale.
This post will focus on the performant storage features that enables Portworx to improve mining pool performance.
It is part of a series of blog-posts about crypto-currencies and how Portworx will help you run production grade applications that interact with blockchain nodes.
Before we dive into the features of Portworx that help you to improve mining pool performance, lets take a look at the current problems you might face.
First up is ledger size – the blockchain for each cryptocurrency is growing exponentially. In December 2017, the size of the Bitcoin ledger is 149 gigabytes and this is predicted to grow exponentially into Terabytes of data over the coming years as more and more payments are made as adoption increases.
The second problem is that you need to store the ENTIRE blockchain on each machine that is running a cryptocurrency application such as an exchange, mining tool or wallet.
You can’t just use NFS or something equivalent because performance is paramount for blockchain applications. Mining is a constant race between thousands of highly powered computers and the smallest performance bottleneck will hurt your profits because your competitors will be able to outperform your setup and win the all important race to mine the next block.
This is why you need a fast, scalable storage layer like Portworx to avoid these performance bottlenecks.
Mining pool performance at scale
When running a single mining node at home – the chances of mining the next block are pretty small and the profits reflect that.
Once you scale up to tens, hundreds or even thousands of nodes – the chances are much higher but you then have another problem: managing a large cluster of machines.
Running a cryptocurrency mining node is the same as any other software, it will need compute, network and storage resources. You will also need cluster management software to automate the deployment and monitoring because these tasks becomes much harder at scale. Tools like Docker and Kubernetes exist to help us package and deploy cryptocurrency node software to a cluster of machines, keep it running and manage the network connections between those nodes.
You will also need a tool that can manage storage for each node and the containers running on it. That is because blockchain clients are inherently stateful – the full ledger for some crypto-currencies are large and each container will need it’s own writable copy.
The type of storage you use is important – it’s always better to use SSD drives as they have higher IOPS than spinning disks. Also – these disks should be local to the compute node as network based disks introduce read/write latency.
This presents a challenge – when we are using high powered machines with many CPU cores, we want to take advantage of container density to increase performance. However – we cannot attach a single disk to each container when we are running tens on one machine:
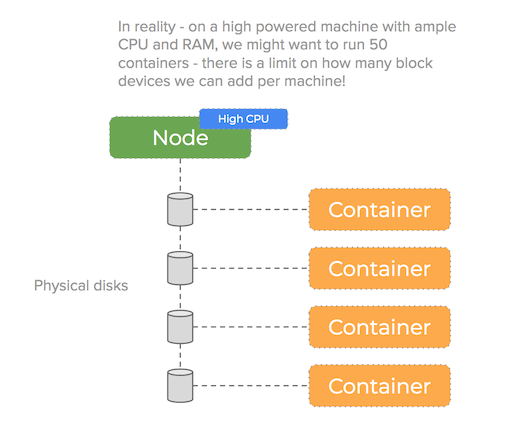
A single Linux VM only has capacity for a certain number of block devices (for example on AWS the limit is around 40) – we need a solution that can manage the underlying storage more efficiently.
Also, it is likely when running a mining pool that you are running other services alongside the miner nodes that might rely on databases, message queues and other stateful services. Ideally – we would use a performant storage storage solution that could be applied to both types of workload.
Ideally, you need a cloud native software defined storage solution that can deal with the things we have mentioned. Especially when investing large capital sums on performant hardware at scale this becomes more important than ever.
The key to improve mining pool performance is:
- Use SSD disks and not spinning disks as they are faster
- Use local disks not network based ones to decrease read/write latency
- Don’t use an entire disk per container so we can increase container density
- Use a cloud native, well designed and performant software defined storage solution
- Use a dedicated SSD or NVME journal device for meta-data if your storage provider supports this option
- Use the IO profile most suited to your application if your storage provider supports this option
- Run compute workloads on the same host as the blockchain ledger resides (hyper-convergence)
Portworx software defined storage
Portworx is a software defined storage solution that is inherently Cloud Native. This means it seamlessly interacts with tools like Docker and Kubernetes and can manage your underlying storage resources and present them to the containers in your cluster. It is cluster aware meaning that when running cryptocurrency mining software – you can use a single storage solution across potentially thousands of nodes.
It creates a storage pool using the underlying disks and can make smart decisions on how to manage those disks to both improve utility and more importantly for the purpose of this blog-post boost performance.
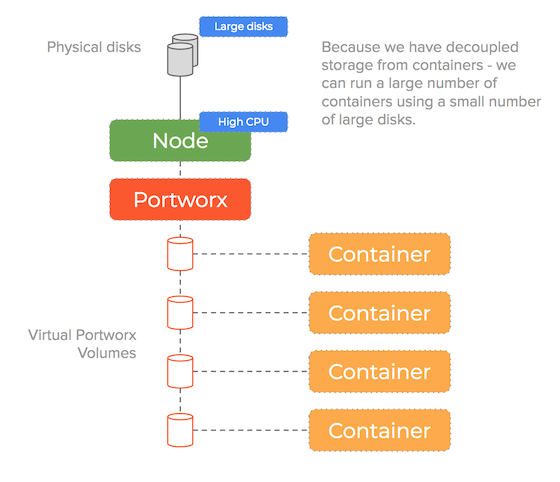
Portworx decouples storage from containers and as such can improve performance by allowing you to increase container density without hitting operational bottlenecks.
The following sections highlight other features that will further improve mining pool performance – we have seen very impressive performance numbers from the tests we have ran when doing the following things:
Adding a journal device to Portworx nodes
The job of a filesystem is to turn the sequence of bytes on an underlying disk (the block device) into an abstraction with files and folders. Otherwise you would have to know the byte offset for a file instead of just it’s name. Equally, it would be nice if the filesystem would recover from failures such as a power cut without having lost or corrupted any of your data.
To achieve these feats, Journaling file systems will need to write meta-data (or journal data) as well as the actual contents of files to the underlying disk.
If your filesystem is using the same underlying block-device for both raw file data and the meta-data – the IOPS are consumed by both things and so performance is impacted.
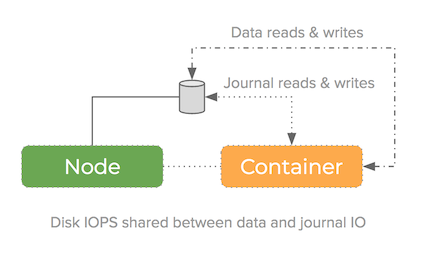
Some filesystems make it possible to add a second block-device for the journal – this can improve performance because we now have more IOPS to do the same job:
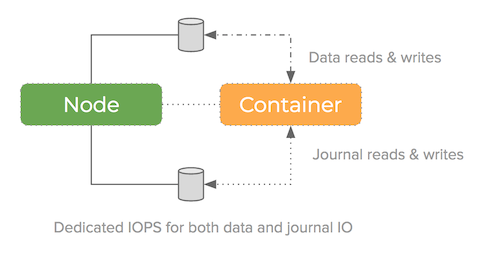
Portworx supports adding a second block device to act as the journal device and we have seen very encouraging performance numbers when we have done this in our tests.
The instructions for how to do this are in the docs.
When applied to all nodes in a cluster at scale, this will improve mining pool performance because the IOPS presented to the filesystem have increased by adding a disk that can be written to in parallel.
Performance tuning
Adding a journal device to Portworx nodes is an example of Global performance tuning – it will increase the IOPS of all container volumes on that node.
Portworx can also use different performance profiles for each volume using on a volume granular level.
This means you can alter the IO profile and change the way Portworx handles bytes on the underlying storage depending on the storage access profile of your container:
Sequential
This optimizes the read ahead algorithm for sequential access. Use io_profile=sequential.
Random
This records the IO pattern of recent access and optimizes the read ahead and data layout algorithms for short term random patterns. Use io_profile=random.
DB
This implements a write-back flush coalescing algorithm. This algorithm attempts to coalesce multiple syncs that occur within a 50ms window into a single sync. Coalesced syncs are acknowledged only after copying to all replicas. In order to do this, the algorithm requires a minimum replication (HA factor) of 3. This mode assumes all replicas do not fail (kernel panic or power loss) simultaneously in a 50 ms window. Use io_profile=db.
Performance numbers
The optimization level of the Portworx codebase should only be measured with one thing: numbers!
The challenge is to offer the wide range of performance and cluster orchestration features whilst remaining as close as possible to the underlying raw performance of the disks.
You can see from our performance numbers that Portworx is a very efficient and yet powerful software defined storage solution.
Random read performance overhead

Random write performance overhead

You can even run these benchmarks yourself!
Conclusion
To summarise, the key to improving mining pool performance is:
- Use SSD disks and not spinning disks as they are faster
- Use local disks not network based ones to decrease read/write latency
- Don’t use an entire disk per container so we can increase container density
- Use a cloud native, well designed and performant software defined storage solution
- Use a dedicated SSD or NVME journal device for meta-data if your storage provider supports this option
- Use the IO profile most suited to your application if your storage provider supports this option
- Run compute workloads on the same host as the blockchain ledger resides (hyper-convergence)
Make sure you also read the other posts in this series:
- How to run production blockchain applications using Portworx
- Deal with the growing ledger size using Portworx
- Acceptance test smart contracts with Portworx to avoid expensive mistakes
Be sure to download and try Portworx today so you can see how it works and get a feel for the product – it’s free to try for 30 days!
Here are some links that you might find useful to find out more about our product and awesome team:
* Docs
* Product introduction
* Our customers
* Team
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.


