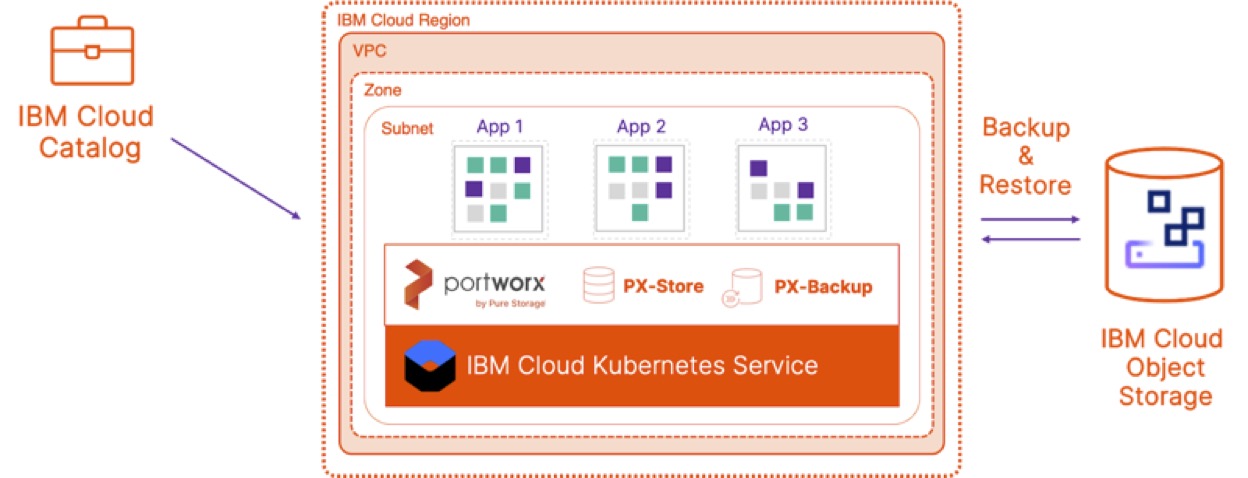
Data protection is the cornerstone to ensuring business continuity, and it has always been top of mind for all IT administrators. It is the process of protecting important information from corruption, compromise, or loss. According to the ESG Research Report on Data Protection Trends and Strategies for Containers from December 2020, 75% of the respondents believe that container-based applications can be backed up the same way as individual applications. This is cause for concern, especially at a time when more and more organizations are running containers in production.
Data protection is the cornerstone to ensuring business continuity, and it has always been top of mind for all IT administrators. It is the process of protecting important information from corruption, compromise, or loss. According to the ESG Research Report on Data Protection Trends and Strategies for Containers from December 2020, 75% of the respondents believe that container-based applications can be backed up the same way as individual applications. This is cause for concern, especially at a time when more and more organizations are running containers in production.
With this blog, my goal is to highlight three reasons why you need to take a step back and rethink your data protection strategy when it comes to containers:
- Traditional backup is machine focused.
If you have been around production IT environments, you understand how traditional backups work. You deploy a hardware- or software-based solution, connect it to your VMware vCenter, Microsoft SCVMM, Nutanix Prism, or bare metal nodes directly. At this point, it will inventory your infrastructure, identify, and enumerate the virtual machines running on your virtualization stack, and it will help you create backup policies to protect those VMs. This is great when each virtual machine or bare metal node is running a single application. But container-based applications are split up across multiple nodes, and the same node (VM or bare metal) can host containers that belong to different applications. So, if you are just protecting individual machines without an understanding of how your distributed application is deployed, then you might not be able to restore your application back to its original state when needed. - Traditional backup doesn’t speak Kubernetes.
Kubernetes is the orchestration and intelligence layer that helps you run your container-based applications. These cloud-native stateful applications are built using Kubernetes objects—like pods, deployments, services, stateful sets, persistent volumes, secrets, config maps, CRDs, and operators. If your backup solution doesn’t know how to talk to your Kubernetes cluster and identify applications using Kubernetes namespaces—or by using labels—then it won’t be able to protect your application the right way. To protect applications running on Kubernetes, we need to adopt a modern data protection solution that understands all the different Kubernetes objects that make up your application versus just protecting the nodes that run these applications. This modernization is similar to when administrators started using virtualization and they had to look at newer solutions for data protection, as their existing solution didn’t understand VMs. - Traditional backup is centrally managed.
Data protection has been the responsibility of the backup administrators in the past, but with container-based environments, that responsibility is being shared by IT operations, the backup administrator, container administrator, storage administrator, virtualization administrator, workload owner, and DevOps teams. Although it will differ from organization to organization, we see a trend around more self-service capabilities when it comes to container-based applications deployed using Kubernetes. Individual application owners want the ability to create their own backup policies and specify their own pre- and post-backup rules to ensure application-consistent backups. Modern data protection solutions like PX-Backup acknowledge this and allow role-based access control to all the different personas that need to protect their applications. With PX-Backup, IT or backup administrators can still define and control the backup targets (on-prem or in the cloud) but allow individual application owners to create their own backup schedules as needed.
As you are thinking about how you want to modernize your data protection stack for Kubernetes and container-based applications, here are five key elements or characteristics that you should look for when considering solutions:
- Container-granular: Machine-based backups are no longer sufficient.
- Kubernetes namespace aware: Your solution must speak the language of Kubernetes and understand all the different Kubernetes objects that combine to form a stateful application.
- Application consistent: Distributed systems running across a series of Kubernetes nodes require an application-consistent solution.
- Capable of backing up data and app config: Just backing up data isn’t enough; neither is just backing up app configs. You need a single solution that is easy to use and helps you protect your applications end to end.
- Optimized for the multi-cloud world: Your data protection solution should be able to protect your applications—regardless of where you run them.
If you want to learn more about Kubernetes backup, you should check out the following webinar that we delivered as part of the Cloud Native Data Management days. Here, we discuss the above points and add more details around the key features needed for a modern Kubernetes-native data protection solution. The webinar also shows a demo of it in action.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!