



An application modernization strategy succeeds or fails on platform engineering, and platform engineering succeeds or fails on how you handle data. Most internal developer platforms excel at stateless workloads but leave storage, backup, and data mobility as manual exceptions. This article looks at the gap and how data-intensive modernization suffers as a result.
Application modernization used to mean rehosting workloads onto containers and Kubernetes. Teams quickly learned lift-and-shift creates more problems than any clean architecture solves. You end up with a cluster full of containers and no improvement in developer velocity or release cadence.
Platform engineering emerged as the answer. Instead of asking every team to figure out Kubernetes, service meshes, secrets management, and observability on their own, you build an internal developer platform (IDP) with golden paths. Developers ship code. The platform handles the rest.
The 2024 DORA Accelerate State of DevOps Report, drawing on responses from more than 39,000 professionals, confirms the pattern. Internal development platforms lift developer productivity, with DORA finding roughly a 6 percent productivity gain at the team level when a dedicated platform team is in place. DORA also flags tradeoffs. Organizations in the middle of a platform engineering initiative see dips in throughput and stability before outcomes stabilize, a classic J-curve. User-centricity and developer independence decide which side of the curve you land on.
The promise is real. The execution bar is high. The place where most teams stumble is the same place Kubernetes itself stumbled for years. Data.
Kubernetes started as a platform optimized for stateless services, with clean primitives like Deployments and ReplicaSets assuming disposable pods. Stateful primitives like StatefulSets and PersistentVolumes arrived later to fill the gap, and today, Kubernetes supports stateful workloads at scale. But the ergonomics still lag. The simplest path on Kubernetes is stateless. Every stateful workload asks for extra thought.
This matters because production application portfolios are data-heavy. The CNCF 2024 Annual Survey of 689 IT professionals found 74 percent of organizations now use containers to manage stateful applications. The Data on Kubernetes 2024 Report, based on 150 technology leaders, found nearly half of organizations run 50 percent or more of their data workloads on Kubernetes in production, with leading organizations pushing past 75 percent. Databases remain the most common workload for the third consecutive year. The Voice of Kubernetes Experts 2024, a Dimensional Research survey of 527 participants commissioned by Portworx, reported 98 percent of respondents run data-intensive workloads on cloud-native platforms, with databases (72 percent), analytics (67 percent), and AI/ML (54 percent) as the top workload types. Dynatrace’s 2025 Kubernetes in the Wild report found about three in four organizations now run Redis in Kubernetes, up 12 percentage points since 2022.
Data is no longer a side project on Kubernetes. Data is the workload.
Running these workloads on Kubernetes exposes operational problems the core platform does not solve end to end.
Your platform team ends up maintaining a parallel universe of storage logic, half of which lives outside the IDP. Developers hit the easy path for stateless services and fall off a cliff the moment they need a database. The Voice of Kubernetes Experts 2025 report captures the cost. 31 percent of respondents cite persistent storage as a top challenge when scaling mission-critical workloads in cloud-native environments, sitting alongside security (72 percent), observability (51 percent), and resilience (35 percent).
Portworx sits in the category of Kubernetes-native storage and data-management layers designed to close this gap, covering persistent volumes, backup, disaster recovery, and cross-cluster data mobility through Kubernetes APIs. Portworx is one option in the space alongside other commercial offerings and open-source operators.
Walk into any platform team’s Slack workspace and count the tools. Backstage for the developer portal. Argo CD for GitOps. Crossplane for infrastructure. Kyverno or OPA for policy. Prometheus and Grafana for observability. Vault for secrets. Istio or Linkerd for service mesh.
Each tool is solid on its own. Stitched together, they form a plausible IDP. None of them solve persistent storage, backup, and data mobility as first-class platform primitives. Some participate indirectly. Crossplane provisions managed databases. Policy engines enforce data controls. Observability stacks watch storage health. But the distance between “provision a database” and “run a database safely with backups, DR, and cross-cluster portability” is where tickets pile up.
Here is a qualitative comparison of what most teams build versus what closes the gap.
| Dimension | Tooling-first platform | Data-aware platform |
| Primary focus | CI/CD, deployment, policy | CI/CD plus persistent state, backup, mobility |
| Stateful workload support | Manual, team-by-team | Self-service, API-driven |
| Backup and restore | Separate tooling, separate SRE | Part of the platform contract |
| Cross-cluster mobility | Custom scripts, tribal knowledge | Declarative, version-controlled |
| Developer experience for databases | File a ticket, wait for a DBA | Same golden path as a stateless service |
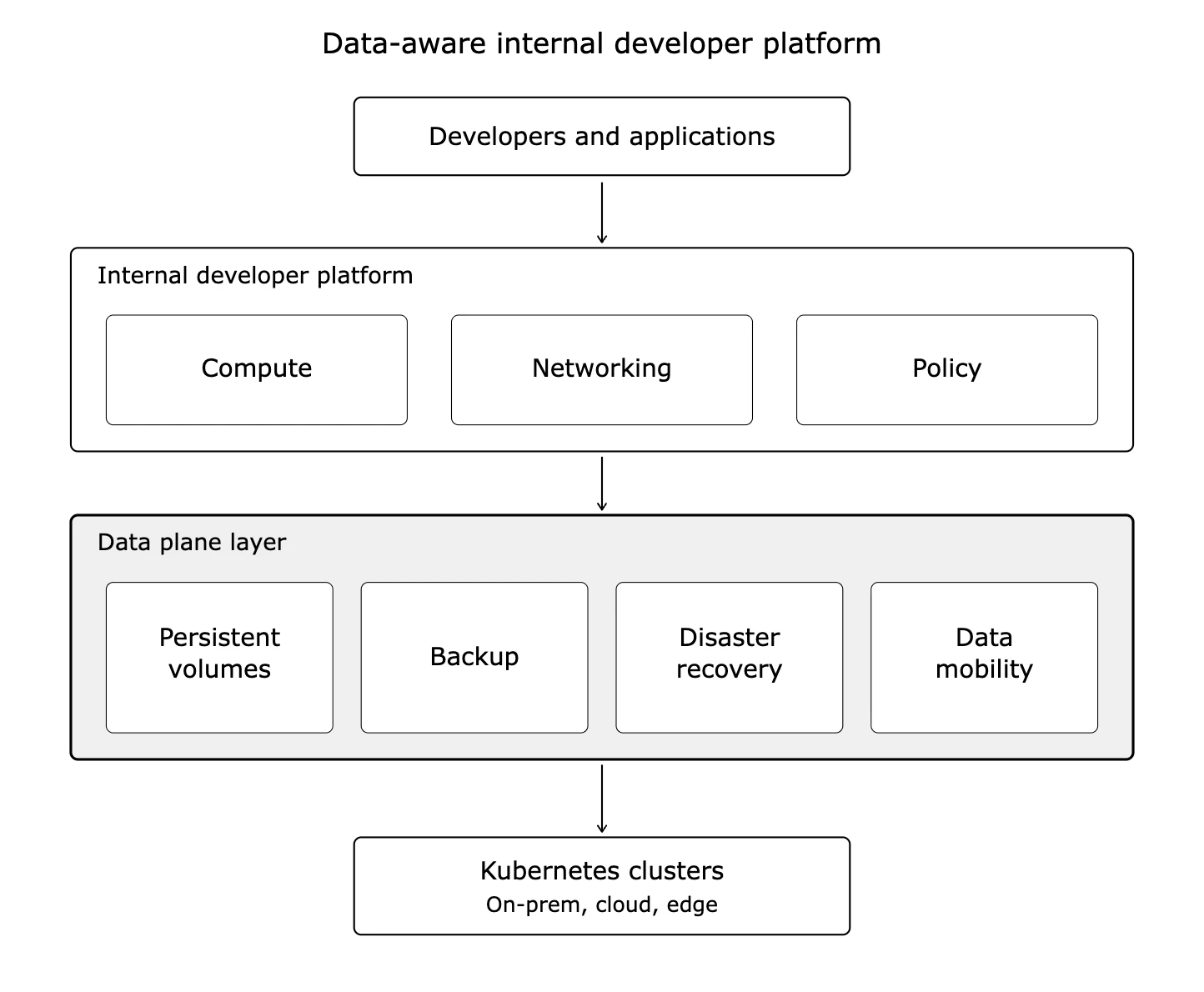
A data-aware IDP treats storage, backup, and data mobility as platform APIs, not operational escalations. The shape of this design is straightforward.
Self-service provisioning: Developers request a PostgreSQL database, a Kafka topic, or a vector store the same way they request an HTTP service. The platform handles volume classes, replication, and snapshots without ticket queues. Kubernetes operators encode the lifecycle logic a platform team would otherwise write from scratch. The Voice of Kubernetes Experts 2024 found 96 percent of surveyed organizations have a platform engineering function, and operator-based automation is a central part of how those teams deliver self-service data services.
Policy-driven backup: Every workload inherits a backup policy based on data classification. Developers do not write backup scripts. The platform enforces the policy.
Cross-cluster portability: Moving an application from a dev cluster to a staging cluster to production includes the data. No manual dumps, no custom sync jobs.
Declarative disaster recovery: RPO and RTO targets get expressed as Kubernetes custom resources. The platform reconciles against those targets.
Cost visibility: Storage consumption shows up alongside compute consumption in whatever FinOps tooling your org uses.
Once you build this layer, developers stop treating stateful workloads as a separate class of problem. The IDP covers the full surface area of modernization.
Day 1 operations get the headlines. Shipping a new service, launching a new cluster, cutting over a workload. These are the milestones leadership tracks.
Day 2 is where the money burns. Patching. Upgrading. Backup verification. DR drills. Certificate rotation. Storage capacity expansion. Failed node recovery. Data corruption investigation.
The Spectro Cloud State of Production Kubernetes 2025 report, based on 455 respondents, makes the Day 2 reality clear. Four in five teams claim a mature platform engineering function, yet more than half admit their clusters are “snowflakes” and highly manual. The same report finds 90 percent of teams expect AI workloads on Kubernetes to grow in the next 12 months, which piles fresh stateful demand onto platforms already struggling with their existing Day 2 load.
A data-aware platform compresses Day 2 work. Consider the comparison below.
| Day 2 activity | Without a data-aware platform | With a data-aware platform |
| Backup verification | Manual audits, sampling | Automated, continuous |
| DR drill | Quarterly, multi-day effort | On-demand, single-command |
| Storage expansion | Ticket to the infrastructure team | Self-service via API |
| Data migration between clusters | Custom scripting project | Declarative policy |
| Recovery from volume failure | Hours, manual | Minutes, automated |
Portworx addresses the Day 2 surface area with automated backup, cross-cluster DR, and storage operations handled through Kubernetes-native APIs, freeing platform teams to reclaim time for the work with compounding returns. Evaluate Portworx alongside options like Velero, OpenEBS, or vendor-specific storage services in your cloud provider.
You do not need a maturity model to assess your IDP. Four practical signals tell you the answer.
Time to first stateful workload in production. If a developer asks for a production-grade database and waits more than a day, your IDP stops at the stateless layer.
Percentage of applications with automated backup. If the number sits well below 90 percent, backup is a snowflake process.
DR drill frequency and effort. If you run drills once a year and dread them, your platform has no DR API.
Percentage of modernized applications including state. If you have modernized 100 workloads but 80 of them are stateless helper services, your modernization program is covering a subset of the problem.
Score yourself honestly. The gaps point directly at the data layer work you need to prioritize.
Q: Q. Why is platform engineering considered a data problem and not a tooling problem?
Platform teams have no shortage of tools for compute, networking, and policy. The gap sits at the data layer, where persistent volumes, backup, DR, and cross-cluster mobility rarely behave like first-class platform primitives. Modernization stalls because stateful workloads require manual operational paths outside the IDP.
Q: Q. How does application modernization depend on platform engineering?
Modernization without an IDP turns into a pile of containerized legacy apps with no improvement in velocity or cost. The 2024 DORA report finds platform engineering lifts developer productivity, with tradeoffs on throughput and stability during the transition. A well-designed IDP delivers the golden paths and self-service abstractions making modernization pay off.
Q: Q. What is the state problem in Kubernetes-based platforms?
Kubernetes started with stateless services as the primary use case, and stateful primitives like StatefulSets and PersistentVolumes arrived later. Today Kubernetes supports stateful workloads, but the ergonomics still lag. The CNCF 2024 Annual Survey found 74 percent of organizations use containers to manage stateful applications, and the Data on Kubernetes 2024 Report found nearly half of organizations run 50 percent or more of their data workloads on Kubernetes in production. The operational burden has shifted onto platform teams.
Q: Q. What does a data-aware internal developer platform include?
Self-service provisioning for stateful workloads, policy-driven backup, cross-cluster data portability, declarative disaster recovery, and cost visibility alongside compute. The goal is to treat data operations as platform APIs rather than operational escalations.
Q: Q. Why does Day 2 matter more than Day 1 for modernization outcomes?
Day 1 milestones look good on a slide, but Day 2 consumes the majority of platform team capacity, especially for stateful workloads. The Spectro Cloud State of Production Kubernetes 2025 report found four in five teams claim mature platform engineering yet more than half still run snowflake clusters, with 90 percent expecting AI workloads to grow further in the next 12 months. A data-aware platform compresses Day 2 operations through automation, which frees capacity for that next wave of modernization.

