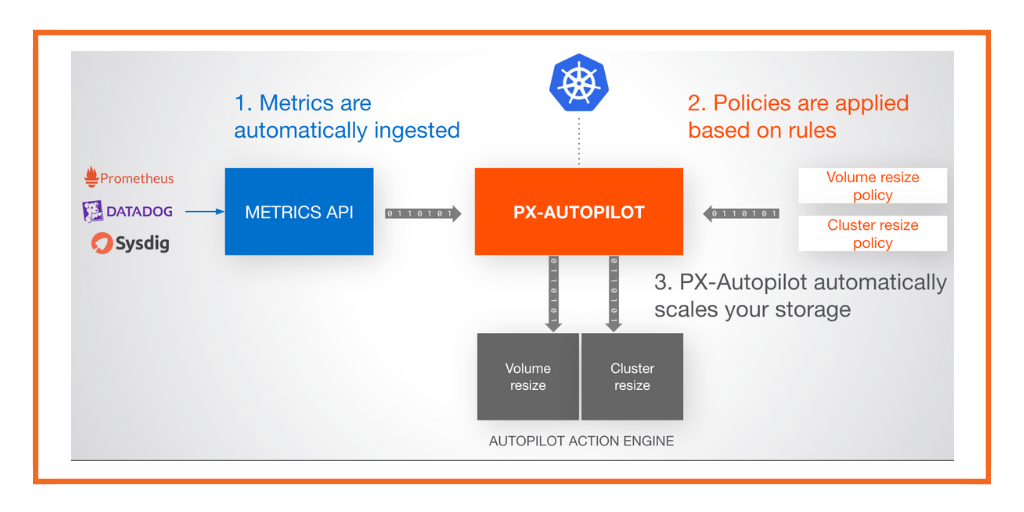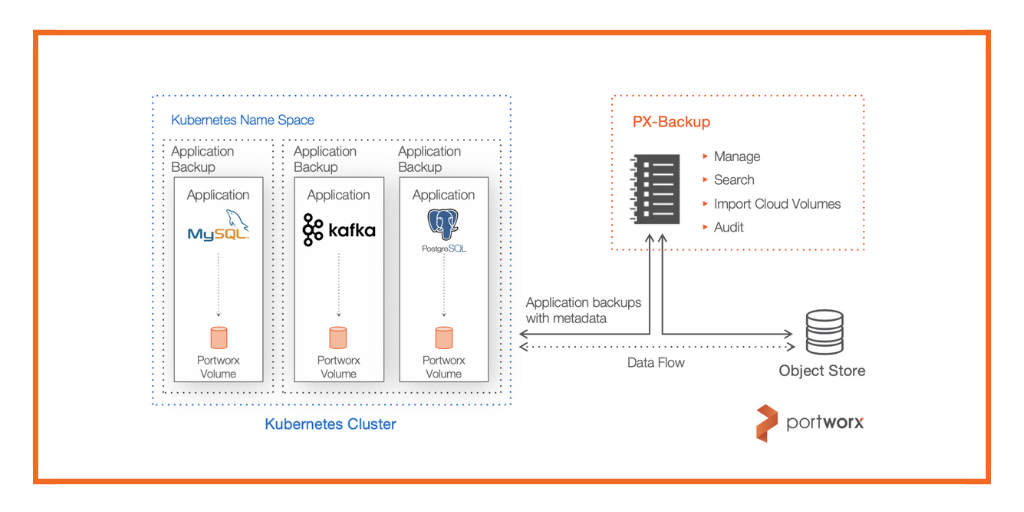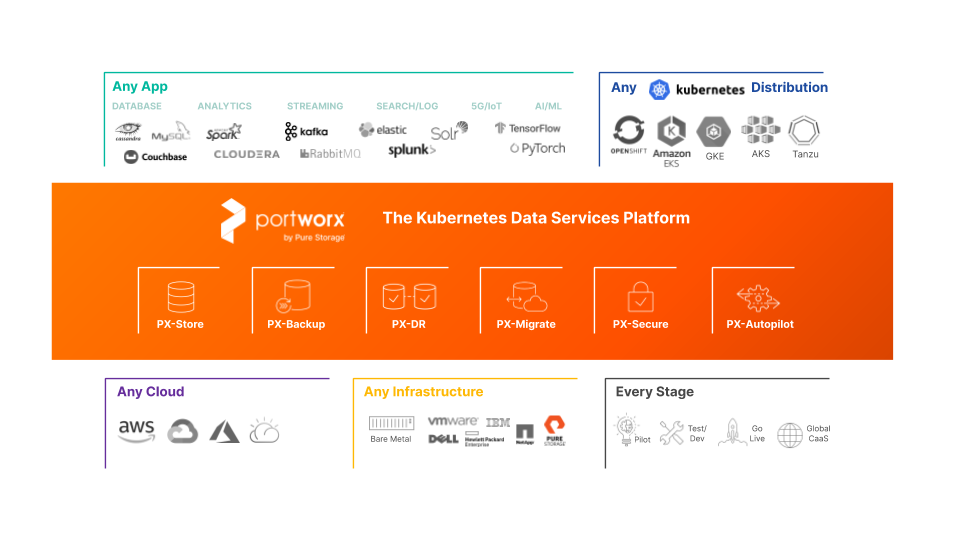
With the news that Portworx has joined Pure Storage, creating the most complete Kubernetes Data Services Platform for building, automating, protecting, and securing cloud-native applications, I wanted to reflect on how we got here from an architectural perspective. We started out six years ago with the conviction that containers will enable massively distributed applications and hyper-agile deployment practices and this, in turn, will create new requirements for storage infrastructure.
The reason is that container patterns would inevitably strain storage systems built for virtual machines. There are three main reasons:
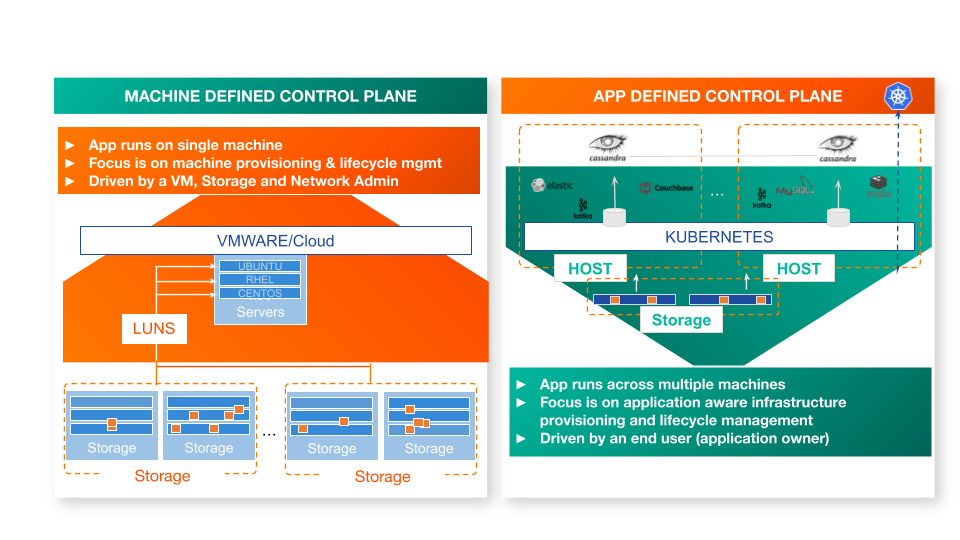
- Traditional storage systems are admin-driven, whereas containers are automation and application-driven. The storage system itself must be application-aware in order to provide optimal provisioning, scheduling, and operations such as application-consistent snapshots.
- Containers are highly dynamic – they are spun up and torn down rapidly and are not tied to any host – this cannot be supported by existing storage protocols that were built for relatively static environments.
- Containers enable at least a 10x higher application density which requires storage operations such as snapshots to be supported at a completely different scale.
With that conviction, we set out to build a storage overlay that is extremely lightweight, spins up at the speed of containers, is highly available, scales horizontally, and has no requirements of infrastructure homogeneity in the cluster. And most importantly, it is woven in and tied to the application lifecycle and not the machine lifecycle. This was a completely different kind of storage system.
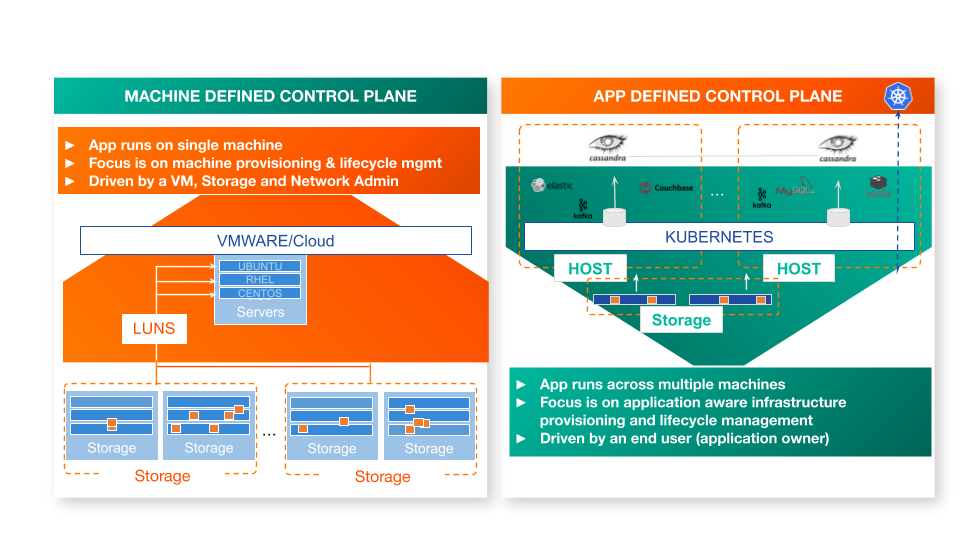
We were not setting out to build a new filesystem or a storage array – our goal was to build an intelligent storage overlay that is integrated with the application control plane–at the time we started Docker, but now mainly Kubernetes–and is able to satisfy the requirements of modern distributed applications. For example, a highly-available distributed NoSQL database such as Cassandra or MongoDB will replicate data across instances – the storage runtime should be able to transfer anti-affinity rules in the application spec such that volumes for containers that are part of the same application are not provisioned in the same fault domain. We were building a storage system that could run on top of any storage substrate– DAS, AWS EBS, Google Persistent Disk, Pure Storage, NetApp, etc–to provide container-granular, application-aware storage services to any stateful service.
In order to achieve these goals, the best decision was to start with building a distributed application-aware block storage service and not a filesystem. Doing so allowed us to punt the complexity of filesystems to ext4/xfs/… while taking advantage of Linux stacking block architecture to build application-level services such as encryption (dm-crypt), caching (dm-cache) on top of proven and battle-tested code.
We also decided to run the storage infrastructure alongside the applications and make the storage control plane work in coordination with the application control plane. This allowed us to be hyperconverged, perform operations such as resizing an active filesystem that usually requires downtime seamlessly, and allow non-disruptive upgrades. In addition to building features, running on the worker nodes allowed us to leverage Linux tools to build monitoring, metrics, and distributed tracing to troubleshoot and gather analytical data.
We stayed true to the vision and launched the first containerized scale-out block storage service in the industry in 2016. I am proud to say that the core of the enterprise product remains architecturally the same today as the day of the launch. Kudos to the team!
Today there is a suite of functionality built on the top and adjacent to the core: autoscaling, external storage, and cloud drive management,rule-based storage management (PX-Autopilot), DR, Backup…
But there is so much more to be done. And that is why I am very excited to join Pure Storage. With so much talent, the best in class in primary storage, and perfect alignment in culture, Portworx couldn’t have found a better home.
So stay tuned, we have only made a small dent in the Cloud Native world, we have big plans for the future!
More About Today’s News from the Pure and Portworx Execs
Charlie Giancarlo, Pure Storage Chairman and CEO
Matt “Kix” Kixmoeller, Pure Storage, VP of Strategy
Murli Thirumale, Portworx Co-founder and CEO
Gou Rao, Portworx Co-founder and CTO
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!