
A Closer Look at the Generative AI Stack on Kubernetes

Kubernetes, the most preferred orchestrator for modern scalable applications, excels at managing complex, distributed systems and is particularly adept at handling stateful and stateless workloads required for deploying and managing a complete generative AI stack.
Organizations are increasingly adopting Kubernetes (K8s) for AI workloads over traditional bare-metal setups due to several compelling advantages. Kubernetes offers enhanced scalability, allowing organizations to efficiently manage the dynamic scaling of applications and services based on computing needs. Its orchestration capabilities streamline the deployment and management of containerized applications, ensuring better utilization of resources and reducing operational overhead. Kubernetes supports a multi-tenant architecture, which is crucial for maximizing resource usage and minimizing costs in environments where multiple workloads and teams share infrastructure resources. The platform also promotes better fault tolerance and high availability, ensuring that AI applications remain robust and resilient against failures. These benefits make Kubernetes an attractive option for organizations looking to optimize their AI and machine learning operations.
This article delves into the technical architecture necessary for running large language models (LLMs), embedding models, reranker models, vector databases, and the entire Retrieval Augmented Generation (RAG) pipeline on Kubernetes. It applies to both scenarios in which Kubernetes is running in the cloud or in the datacenter.
The Generative AI Stack
Let’s take a look at the architecture before delving into the deployment aspects.
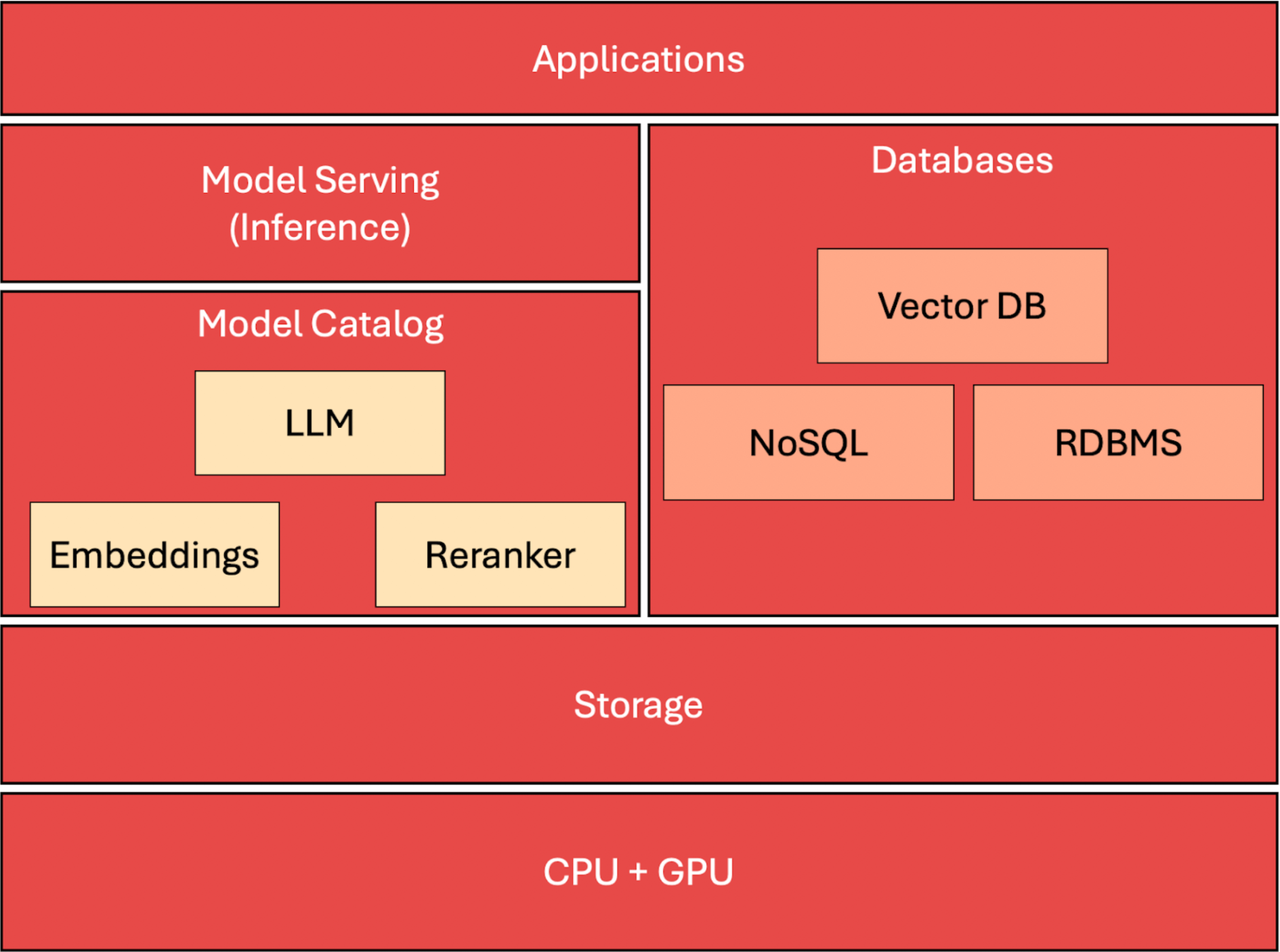
Accelerated Compute
To run generative AI applications, customers rely on an accelerated compute layer based on high-end CPUs and GPUs such as the Intel Xeon and NVIDIA L40S. This layer is crucial to the performance of GenAI applications. NVIDIA’s Container Toolkit, NVIDIA GPU Device Plugin, and NVIDIA GPU Operator enable Kubernetes pods to access the CUDA layer to accelerate inference.
Cloud Native Storage Platform
The storage layer in a generative AI stack is a cornerstone that significantly influences overall system performance and scalability. It ensures the efficient management, retrieval, and persistence of large volumes of data, which are critical for training and operating AI models. Effective storage solutions enable faster data access and more efficient data processing, reducing latency and improving throughput for tasks such as model training and inference. Moreover, the storage layer supports high availability and disaster recovery capabilities, essential for maintaining the integrity and availability of data in production environments. Robust storage solutions also allow for scalability, accommodating growing data needs without compromising performance.
Keeping model catalogs directly within Kubernetes (K8s) offers significant efficiency and operational benefits, especially for generative AI workloads. By maintaining a centralized repository of models inside the Kubernetes environment, organizations can avoid the latency and complexity associated with repeatedly ingressing data from external systems every time it is needed. This approach not only speeds up the deployment and iteration of AI models but also enhances data governance and security by keeping sensitive data within a controlled environment. Additionally, integrating enterprise storage solutions with Kubernetes facilitates high availability (HA) and disaster recovery (DR) capabilities. This integration ensures that model data is consistently available and resilient to failures, supporting seamless scalability and robustness that are critical for high-performance AI applications. Thus, embedding model catalogs in Kubernetes aligns with the strategic need for efficient, reliable, and scalable AI operations.
Model Catalog
The model catalog serves as a central repository for all AI models, including LLMs, embeddings, and reranker models. It streamlines model management by centralizing storage, reducing redundancy, and facilitating easier updates and deployment of models across different environments. The use of a model catalog is crucial for efficiency and consistency in model usage across various applications and services.
To deploy a model catalog on Kubernetes, you should use a persistent volume with ReadWriteMany (RWX) capability to enable concurrent access by multiple pods. This can be achieved through Portworx’s SharedV4 volumes, which enable mounting the same volume across multiple pods. Set up a Persistent Volume Claim (PVC) based on NFS or Portworx’s SharedV4 volumes and mount it to the pods that require access to the models. This approach ensures that large models are available to all parts of your application without needing to be re-downloaded or copied, enhancing performance and reducing latency.
Model Serving
Open large language models like Meta Llama 3 or Mistral form the backbone of many AI-driven applications, handling tasks from simple text responses to complex contextual understanding and generation. These models require significant computational resources, particularly for tasks involving multiple concurrent requests.
Once the LLMs are available in the model catalog, they can be served through inference engines such as Hugging Face Text Generation Inference, vLLM, NVIDIA Triton with TensorRT-LLM or other serving engines.
Embeddings and reranker models are specialized language models used to transform text into numerical data that can be easily compared and processed. Examples include all-MiniLM-L6-v2 and BAAI bge-reranker-large They are crucial for tasks such as semantic search, recommendation systems, ranking the results, and enhancing the relevance of results returned by LLMs.
Deploy language models using Kubernetes Deployments with access to GPU resources. Utilize node labels and node selectors to schedule these pods on appropriate GPU-equipped nodes. Implement an auto-scaling solution based on custom metrics like GPU utilization or queue length of the serving engine to handle varying loads. Use Kubernetes services to expose the LLMs, providing a stable endpoint that client applications can interact with, and employ load balancers to distribute incoming traffic evenly among pods. Configure resource limits carefully to optimize the use of memory and CPU, as these models can be resource-intensive. Leverage Kubernetes ConfigMaps and Secrets to manage configuration and sensitive data, respectively. Horizontal Pod Autoscaling (HPA) can be implemented to scale the number of pods based on CPU and memory usage metrics.
Databases
Relational databases store structured data, while NoSQL databases handle unstructured or semi-structured data, both serving as foundational components for storing application and operational data needed by AI models and the application layer. Mainstream relational and NoSQL databases such as PostgreSQL, MySQL, MongoDB, and Cassandra can be used to retrieve the data that acts as the ground truth for LLMs to generate factually correct responses.
Vector databases are the new breed of databases designed to efficiently store and query vector embeddings generated by AI models. These databases are crucial for enabling fast and scalable retrieval of similar items based on embeddings, which is key for features like similarity searches in applications. Unstructured data is passed through the embedding model to generate the vectors, which are then indexed, stored, and retrieved from the vector database.
Use StatefulSets for relational, NoSQL, and vector databases to provide stable persistence and consistent network identifiers. Use Portworx storage classes optimized for running databases to get the best performance and throughput. Customize your deployment with ConfigMaps for configuration and use Secrets for sensitive data like database credentials. Employ Kubernetes-native tools or third-party operators for managing database replication, backups, and automatic failover to enhance reliability and disaster recovery capabilities. Set up readiness and liveness probes to ensure the database is always ready to handle requests and maintain high availability.
App Orchestration Layer Based on LangChain or LlamaIndex
The app orchestration layer manages the interaction between users, AI models, and data stores. It handles task distribution and scaling and provides APIs for front-end applications. Both LangChain and LlamaIndex enable complex AI workflows, integrating various AI services into cohesive applications. These are mostly stateless applications, with the data persisted in one of the databases exposed in the database layer. For example, the responses to frequently used prompts and queries can be cached in Redis or MongoDB.
Deploy LangChain or LlamaIndex-based applications as a set of stateless services using Kubernetes Deployments. This allows for easy scaling based on demand without worrying about state or individual pod identities. Expose LangChain services through Kubernetes Ingress or load balancers to manage traffic and ensure availability. Utilize ConfigMaps for configuration and Secrets for sensitive data management. Implement robust security policies using Network Policies and Role-Based Access Control (RBAC) to protect the services.
Summary
Kubernetes, the premier orchestrator for scalable applications, excels in managing complex distributed systems, making it ideal for deploying and managing a complete generative AI stack.
This article explored the technical architecture for running LLMs, embedding models, reranker models, vector databases in cloud and datacenter environments based on Kubernetes. This stack’s key components include an accelerated compute layer that uses high-end CPUs and GPUs, a robust cloud-native storage platform, a central model catalog, efficient model serving mechanisms, versatile databases, and an app orchestration layer powered by LangChain or LlamaIndex.
The next article will focus on utilizing Portworx to run GenAI workloads, further enhancing the efficiency and scalability of AI applications on Kubernetes.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Janakiram
Janakiram is an industry analyst, strategic advisor, and a practicing architect.



Chapter 8: Day 2 Operations: Lifecycle Management and Observability
