



Running inference at scale on Kubernetes works only when data movement keeps up. Most teams tune GPUs, autoscalers, and model servers, then watch performance collapse anyway. The reason sits underneath the stack. Model weights, KV-cache state, and vector indexes all depend on fast data movement, and a slow data path stalls the pods that wait on it.
Kubernetes has become the default home for production AI. The CNCF Annual Cloud Native Survey, based on 628 IT professionals and published in January 2026, reported that 82% of container users now run Kubernetes in production. The same survey found that 66% of organizations hosting generative AI models use Kubernetes to manage some or all of their inference workloads. Inference is no longer an experiment. It is a production service with a budget, an SLA, and a data-path dependency that most teams underestimate.
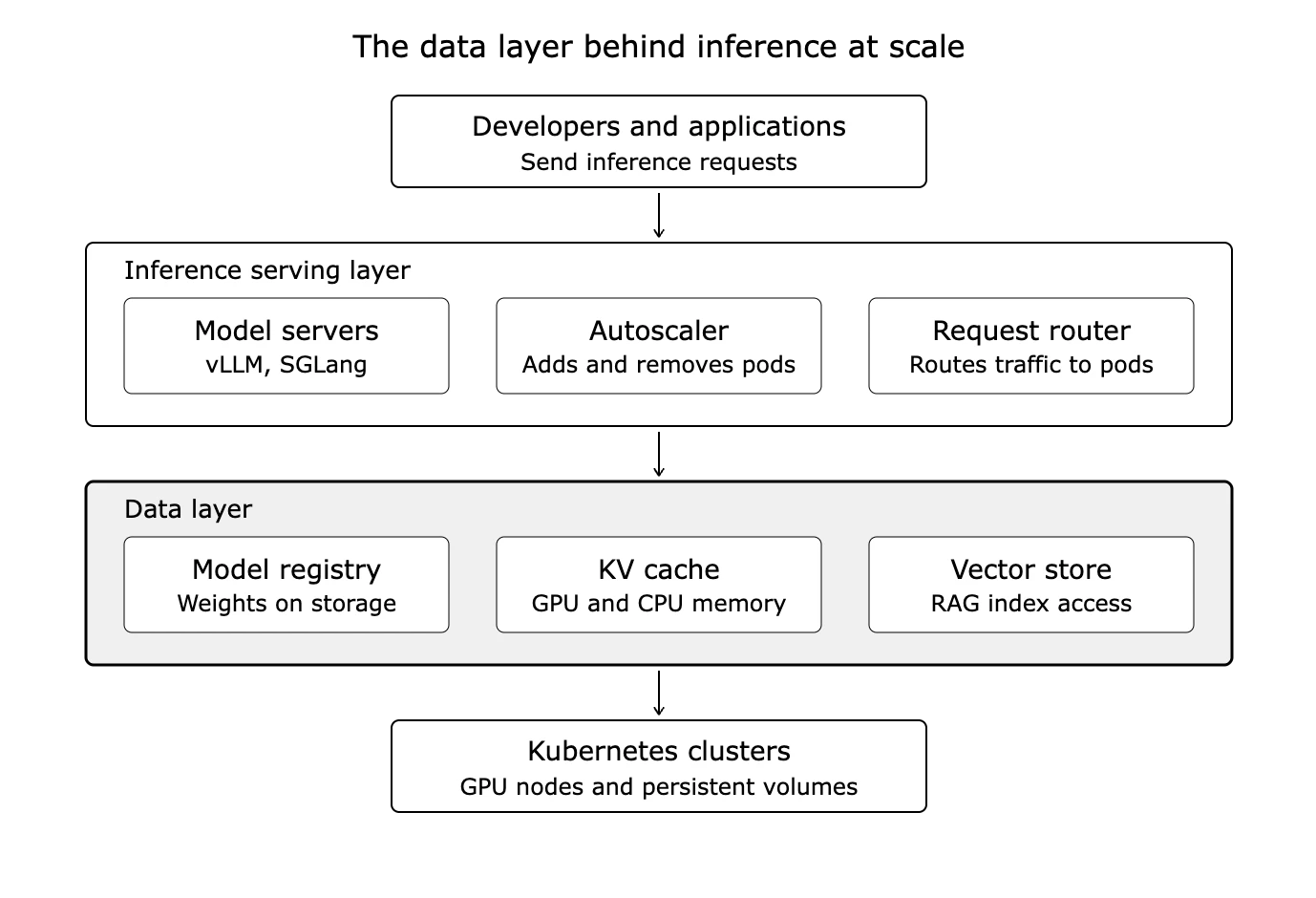
Inference looks like a compute problem. You provision GPUs, deploy a model server, and route traffic. The model spends a lot of its operational life moving data, not just computing on it.
Three data paths commonly shape inference performance. The first is model-weight loading, which moves weights from a registry into GPU memory before a pod can serve anything. The second is KV-cache management, which holds the token context for every active request. The third applies to retrieval-augmented generation, where vector retrieval pulls grounding data from a knowledge base.
These paths stress different parts of the stack, and they stress them in different ways. Weight loading is large sequential reads from storage during startup and scale-out. KV-cache management is a high-frequency activity in GPU and CPU memory. Vector retrieval is low-latency index access for RAG workloads. A design that handles one well can fail the other two. That mismatch is often where inference performance breaks.
Teams plan inference around stateless assumptions. A web service starts in seconds and scales on CPU metrics. Inference does neither. It carries state, and that state has to be managed.
Model weights are the clearest example. A 7-billion-parameter model can take five to ten minutes to load from network storage into GPU memory, according to a production engineering guide published by Zartis in April 2026. The figure is workload-dependent, not a fixed benchmark, and larger models take longer. During that window the pod runs, the GPU bills, and no request gets served. Multiply that across a scale-out event and the costs grow significantly.
The KV cache adds a second state problem. LLM inference engines preemptively allocate GPU memory for the KV cache when a model server boots, as a Cloud Native Now analysis explained in 2026. The cache stores the mathematical context of generated tokens so the model does not recompute the full prompt for every new word. In most deployments the KV cache is ephemeral GPU and CPU memory, so a pod restart loses useful context and prefix-cache state. Advanced systems can offload or share KV blocks across a memory and storage hierarchy, but that introduces new latency and storage tradeoffs rather than removing the problem.
This is the state problem nobody planned for. Inference pods are stateful workloads wearing stateless clothing. They need a model-distribution strategy, fast warm caches for weights, and, for workloads that benefit from prefix reuse or long-context serving, a deliberate KV-cache and offload strategy. The model and cache data behind that strategy is exactly the kind of stateful workload Kubernetes storage layers exist to handle. Portworx provides persistent storage and volume management for stateful workloads on Kubernetes, including model registries and warm weight caches. Alternatives in the category include OpenEBS and cloud-vendor block storage. The choice matters less than the recognition that inference has state, and state needs a plan.
Autoscaling is the feature that makes Kubernetes attractive for inference. It is also the feature the data path breaks first.
The standard horizontal pod autoscaler assumes a new pod absorbs load almost immediately. That assumption holds for stateless services. It fails for inference because the new pod cannot serve traffic until its model finishes loading. The Cloud Native Now analysis noted that native Kubernetes autoscaling is poorly matched to LLM inference, since GPU memory metrics trigger false scaling events and CPU metrics tell you nothing about whether the inference system is healthy.
The result is a gap. Traffic spikes, the autoscaler adds pods, and those pods sit in a model-loading state while existing pods absorb the surge alone. If the model-loading path is slow, the gap widens. If it is fast, the gap shrinks. Weight-loading throughput is the variable that decides how well autoscaling works under pressure.
A cold start is the time from pod creation to first served request. For inference, model load time dominates that number. Teams reduce it by caching weights on fast local storage or persistent volumes so a new pod reads from a warm source rather than pulling the full model across the network.
GPUs are expensive to leave idle. Scale-to-zero shuts inference pods down during quiet periods and brings them back on demand. The llm-d project, an open source distributed inference framework for Kubernetes backed by Red Hat, Google, IBM, and others, added scale-to-zero support in its v0.5 release in early 2026, using an activator component to handle the cold-start sequence without dropping requests. Scale-to-zero only pays off when the path back from zero is fast, and that path runs through model loading.
GPU nodes fail. When they do, the pods reschedule onto healthy nodes and reload their models. Weights pinned to a single failed node cause long outages as the model reloads from scratch. A data layer that keeps weights reachable across the cluster cuts that recovery time sharply.
Day 1 is deployment. You get a model running, traffic flows, and the demo works. Day 2 is everything after, and Day 2 is where inference platforms live or die.
Day 2 problems are data and state problems. Model versions change and the registry has to serve old and new weights without downtime. Traffic patterns shift and the memory and offload tiers have to hold up. Nodes fail and volumes have to follow the pods. Snapshots, backups, and disaster recovery all apply to inference data the same way they apply to a database.
This is the work that gets skipped in planning and discovered in production. Before picking a tool, define the criteria. You need a model-distribution strategy, volume management that survives pod and node churn, and snapshot and replication support for the data inference depends on. A Kubernetes-native data platform handles those without bolting on a separate system. Portworx supports these Day 2 operations, including data replication and backup for stateful Kubernetes applications. Teams also use Velero for cluster backup and recovery, and cloud-vendor storage where the platform is single-cloud. The point is not the tool. The point is that Day 2 data operations are part of the inference platform, not an afterthought.
Think of choosing a storage approach the way you would choose a foundation for a building. The load above dictates what the foundation needs to carry. An inference platform puts different loads on the data layer, and the right choice depends on which load dominates.
| Inference need | Data characteristic that matters | Why it matters |
| Loading model weights | High sequential read throughput | Shorter cold starts and faster scale-out |
| Managing the KV cache | Sufficient GPU and CPU memory, optional offload tier | Lower time-to-first-token under cache pressure |
| RAG vector retrieval | Low-latency index access | Consistent retrieval latency at high query volume |
| Surviving pod and node churn | Persistent, cluster-wide volumes | Recovery without full model reload |
The second decision is where model weights live before they reach the GPU. The options trade speed against operational cost.
| Approach | Strength | Tradeoff |
| Object storage as the source of truth | Simple, low cost, large capacity | Slow cold starts when streamed directly to pods |
| Shared file or block tier with caching | Faster repeat loads, weights served once and cached close to engines | Adds a storage tier to manage |
| Local NVMe on GPU nodes | Fastest possible model read into GPU memory | Data lost on node failure, no portability across nodes |
Most production platforms combine these. Object storage holds the source of truth, persistent volumes cache hot models, and local NVMe accelerates the read into GPU memory. The combination matters more than any single choice, and the right mix depends on model size, traffic shape, and recovery requirements.
Inference at scale is a data and state management problem dressed as a compute problem. The Voice of Kubernetes Experts report, a 2024 survey of 527 Kubernetes practitioners commissioned by Portworx by Everpure and conducted by Dimensional Research, found that 54% of respondents run AI/ML workloads on cloud-native platforms. Disclosed as vendor-commissioned, that figure still tracks with the independent CNCF data, and those teams are discovering that the data layer decides whether their GPUs earn their cost.
The work is straightforward once you name it. Measure model load time and treat it as a first-class metric. Cache weights on storage that survives pod churn. Decide whether your workload needs a KV-cache offload strategy before traffic forces the question. Build Day 2 operations into the platform from the start. Storage and data movement is the layer that gets the least planning attention, and it decides whether inference at scale works.
Inference spends much of its operational life moving data. Model weights load from storage into GPU memory, the KV cache is managed in GPU and CPU memory during serving, and RAG retrieval reads vector indexes. A slow data path stalls the pods that wait on it, regardless of how fast the GPU is.
Inference pods carry state even though teams plan them like stateless services. Model weights have to load fast on every scale-out, and the KV cache holds context that a pod restart loses. Inference pods are stateful workloads that need a model-distribution strategy and, for some workloads, a deliberate KV-cache plan.
The horizontal pod autoscaler assumes a new pod serves traffic almost immediately. An inference pod cannot serve anything until its model finishes loading, which can take five to ten minutes for a 7-billion-parameter model depending on the workload. A slow model-loading path widens that gap. A fast one shrinks it.
Day 1 is getting a model deployed. Day 2 is model version changes, traffic shifts, node failures, snapshots, backups, and disaster recovery. These are data and state operations, and they get skipped in planning and discovered in production.
Match the data layer to the dominant load. Model loading needs high sequential read throughput, the KV cache needs sufficient GPU and CPU memory plus an optional offload tier, and RAG retrieval needs low-latency index access. Most production platforms combine object storage for the source of truth, persistent volumes for caching, and local NVMe for the fastest read into GPU memory.

