In today’s world data is the new currency. Data and data analysis allows you to make informed decisions that help drive desired business outcomes. Data management brings with it many challenges such as data-pipeline architecture design, data modeling, data governance, data curation, and data lifecycle management. Systems and applications are being developed to address the above mentioned concerns for structured and unstructured data. This blog focuses on one such system: Elasticsearch. We will demonstrate how you can scale your Elasticsearch cluster easily using Kubernetes and improve observability of the data system behind the Elasticsearch cluster.
Why use Elasticsearch?
Elasticsearch is an open source distributed full text search engine capable of indexing vast amounts of structured and unstructured data in real time. Elasticsearch offers a RESTful search and analytics engine based on the Lucene library. Elasticsearch, as the name implies, started with a “You know, for search!” use case, but it continues to expand its application to other use cases. Here are some of the top use-cases:
- Log monitoring and analytics
Elasticsearch is at the heart of the ELK stack. Elasticsearch is used for indexing, Logstash is used for ingesting data, and Kibana for visualizing log data. You can set up alerts if certain critical business conditions are discovered in the log data. - Full-Text search
Full-text search is considered as the core capability of Elasticsearch. Full text search can be used to recommend related products and can aggregate answers in knowledge sharing websites. It can also be applied towards a fraud detection solution. - Event data with metrics
Elasticsearch, with its plugin architecture makes it flexible for indexing data from remote systems. The remote data systems could be a data generator such as a Twitter feed or it could be any type of time-series data. - GIS System and visualization
Managing and analyzing spatial information for Geographic Information Systems (GIS) is possible with the built-in datatype such as geo_shape within the Elasticsearch platform.
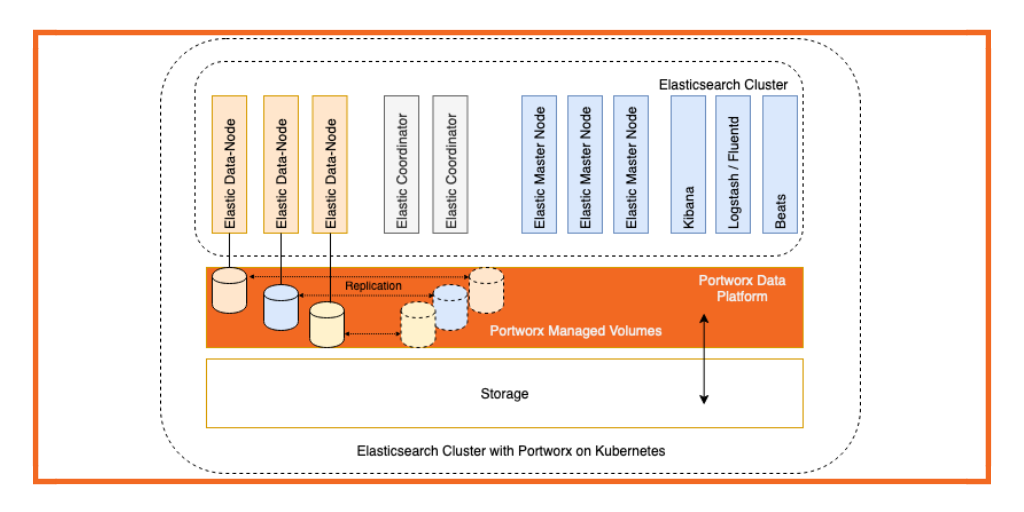
Deploy Elasticsearch with the Portworx Data Platform on Kubernetes
Elasticsearch, depending on the use case, has become a critical component in business success. You can no longer afford any downtime of the Elasticsearch system. The following is a list of advantages running Elasticsearch in a Kubernetes cluster:
- Kubernetes, with the introduction of StatefulSets allows you to run stateful workloads with persistent data, like Elasticsearch on the container platform. StatefulSets also allow you to control operations using the ordinal index of StatefulSets.
- Kubernetes can help you to effortlessly scale the Elasticsearch cluster horizontally through API calls and expand the compute or worker nodes. The advantage of using the Portworx data platform along side Kubernetes is that it can dynamically scale your storage as the worker nodes are expanded.
- With Kuberentes, you can easily scale down one version of Elasticsearch and scale up a new version of the application for testing while using the same data. Additionally, the Portworx data platform can not only take snapshots between version changes but it can also backup your Elasticsearch volumes to a cloud Objectstore.
- If you set up two different Kuberentes clusters to test two different versions of Elasticsearch for business-continuity reasons, the Portworx data platform can migrate your Elasticsearch persistent volumes between the two Kubernetes clusters that are running on different cloud environments.
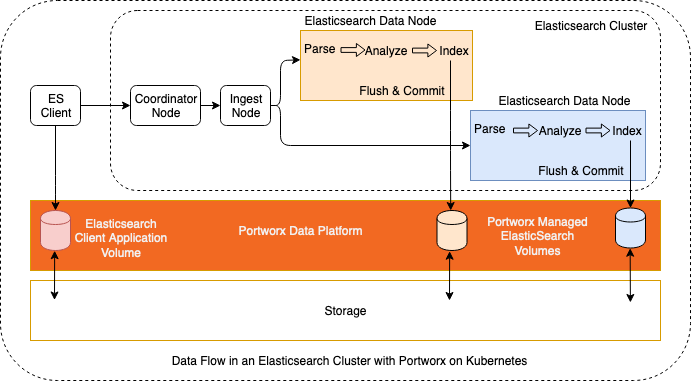
Data flow between Elasticsearch and the Portworx Data Platform
Before we discuss any performance tuning and scaling of an Elasticsearch cluster, we need to understand the data flow inside the Elasticsearch cluster and also understand the integration between the Elasticsearch cluster and the Portworx data platform. When an Elasticsearch client generates data for indexing, the data record passes through a coordinator and/or ingest nodes so that it can be indexed by the data node. Once the data enters the Elasticsearch data node, it is parsed, analyzed, and indexed so that it can be searched using the Kibana front end. In order to save the data, the index is flushed to the storage system. In this instance, the Portworx data platform manages the PersistentVolumes (PV) and commits the index data to the underlying storage medium.
Recommendations for Scaling Elasticsearch with the Portworx Data Platform
You can find detailed instructions for installing Elasticsearch with Portworx here. In the section below we will focus on describing the best practices for Elasticsearch and how you can scale an Elasticsearch cluster with its persistent storage.
- Since Elasticsearch indexes the data records within seconds using the Lucene JAVA library, you should ensure that the nodes are capable of processing data quickly by specifying a large heap size for the Elasticsearch data nodes. You will specify the heap size as such:
...
- name: "ES_JAVA_OPTS"
value: "-Xms12g -Xmx12g"
... - Elasticsearch indexes new data quickly. The newly built index needs to persist on the PV managed by the Portworx data platform. The Portworx-provided StorageClass (SC) should be configured with a high-IO class of service (CoS) to ensure high throughput for the Elasticsearch data nodes.
- Elasticsearch nodes should be configured with swap off in order to increase stability and performance of the Elasticsearch nodes in the cluster.
- If your Elasticsearch cluster is experiencing slow indexing, you should consider scaling your data nodes horizontally, in order to distribute the indexing of new data. You can scale Elasticsearch data nodes from 3 to 5 using the command:
kubectl scale sts elasticsearch-data --replicas=5
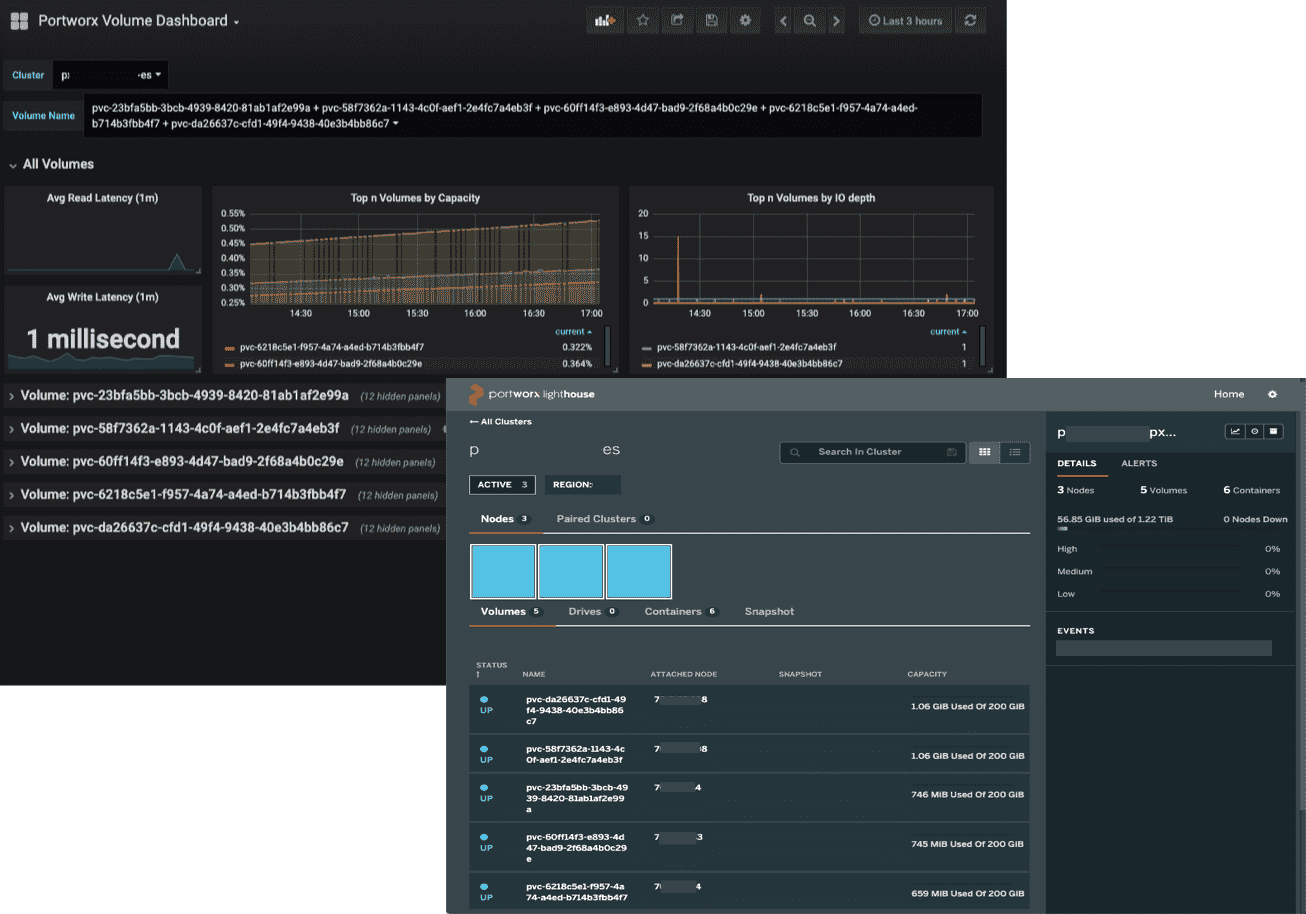
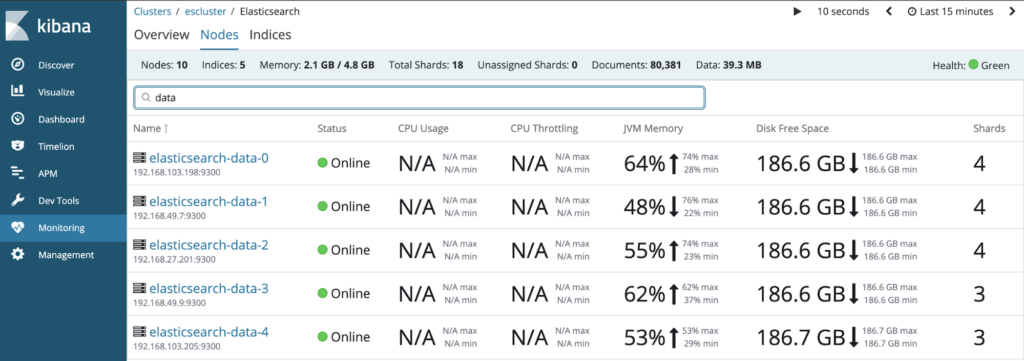 The Portworx data platform automatically scales with the Elasticsearch data nodes and dynamically provisions additional high-IO CoS storage. You can observe the storage performance and capacity using Portworx’s Grafana dashboard and built-in GUI as shown below.
The Portworx data platform automatically scales with the Elasticsearch data nodes and dynamically provisions additional high-IO CoS storage. You can observe the storage performance and capacity using Portworx’s Grafana dashboard and built-in GUI as shown below.
Where do we go from here?
This blog covered use cases of Elasticsearch and topics of deployment, scalability and observability of Elasticsearch with the Portworx data platform. In the next blog post related to Elasticsearch, we will dive deep into a particular use case and show you how you can deploy Elasticsearch with Portworx to reduce recovery time and increase cost savings.
If you would like to learn more about the Portwox Data Platform, please request a demo and talk to one of our Elasticsearch experts. You can also join our slack channel to discuss how Portworx Enterprise can help you run stateful workloads in production.
Resources
You can also check out these tutorials on running Elasticsearch on the most popular Kubernetes platforms.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Tushar Raut
Tushar Raut is a Member of Technical Staff at Portworx with over 4 years of experience in application development, databases, and running stateful application on different container orchestrators. Currently he is working on adding persistent storage support for different applications to run on orchestrators like Kubernetes and DC/OS.

Vick Kelkar
Vick is Director of Product at Portworx. With over 15 years in the technology and software industry, Vick’s focus is on developing new data infrastructure products for platforms like Kubernetes, Docker, PCF, and PKS.
Explore Related Content:
- elasticsearch
- kubernetes
- portworx data platform