

I wanted to talk about how we should handle high availability of stateful applications in Docker. Some applications handle their own availability at the application level, and some don’t. So it can get confusing about how you provision storage to applications running in Docker:
- Do I rely on the application’s internal replication and disable external storage replication? Or do I use both?
- What if the scheduling software respawns my container on a different node? Was the storage local to the node or external? Can the data be made available on the new node, or should the scheduler respawn the container on the same node (node affinity)?
- What if my physical server that I run my container on needs to be decommissioned?
In production, these questions can really make you rethink how you handle stateful containerized applications.
So I wanted to take a step back and walk you through the basics of handling highly available stateful services in Docker.
Handling stateful applications in Docker relies on two things:
- A scheduling layer that is at minimum node affinity aware.
- A storage layer that can ensure data availability across nodes in case a server permanently (or for a prolonged period of time) fails.
In my experience in dealing with production applications in enterprise IT infrastructure, I find that applications fail more frequently (due to crashes and restarts) than servers do. Next, servers fail more frequently or run out of life compared to the storage fabric (usually because storage is inherently highly available in any sane enterprise).
Finally, there always is a disaster scenario where data is lost and DR needs to be implemented.
Below is a diagram on how I think these scenarios can be handled with stateful Dockerized applications:
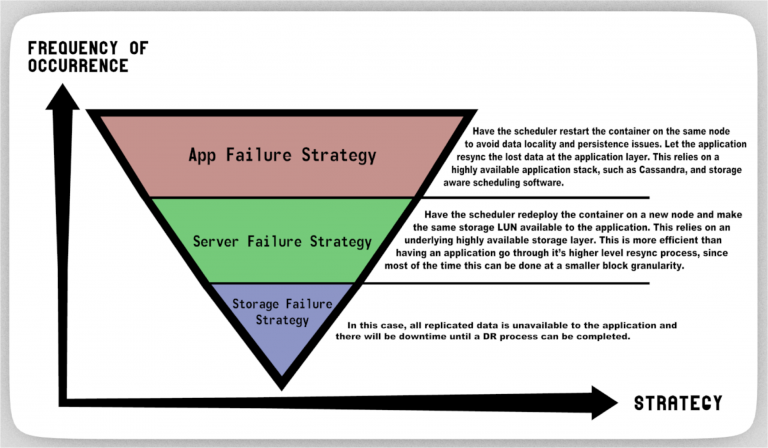
Here is an example… I deploy Cassandra in a container and for whatever reason it crashes once an hour (hypothetically). I don’t want to initiate a whole storage level replication resync process just because of that… let the storage layer take it easy, and the scheduler will respawn the container and let Cassandra do its thing.
But then let’s say my server fails for a prolonged period and I want to just move that container to a new node… and the storage layer has already replicated that container’s data… do I want Cassandra to go through its complex resync steps? No.
These are the type of issues I hear from enterprise devops teams in managing these stateful applications, so I think that formalizing on an overall strategy is in the best interest in a template on how to manage stateful containerized applications.
Did you enjoy what you just read? Learn more about Docker storage, Kubernetes storage or DC/OS storage.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

