Portworx builds a software scaleout block storage solution for Docker. We rely on commodity hardware and assume customers have existing underlying physical storage (DAS or SAN, we don’t care), from which we carve out virtual volumes for Linux containers.
A fundamental question is how these storage volumes can be directly attached to a stateful application running in Docker, which was seen to be mostly meant for stateless applications.
As we saw customers starting to deploy Docker in production, it made less sense to have two parallel application deployment schemes: one for statefull apps and one for stateless services. People wanted a coordinated, container granular way of describing and deploying their distributed application, regardless of its scale.
Since the application scope in these environments changed from a machine to a Docker container, how do you orchestrate the provisioning of storage to that container in a distributed computing, multi node environment? With VMs, you have the luxury of virtual volumes tied to hosts. Do you use that same boundary for containers? Why would you do that if the application boundary, the scheduling layer and your devops process are Docker centric?
The horizontal spread of Docker in the mainstream enterprise continues to spread and the container ecosystem has been working on solving this problem. Kudos to Docker for working on this problem with the ecosystem in a very open way.
Docker recently released support for Docker volumes, where storage providers can coordinate the provisioning and orchestration of storage with the Docker runtime by way of the Docker volumes interface. I really want to thank a few guys here that saw the problem early on and rallied for a solution here…Brian Goff @cpuguy83, Luke Mardsen (ClusterHQ), David Calavera @calavera, Michael Crosby @crosbymichael and others really pushed hard on solving this issue. Brian especially went out of his way to help folks from the partner ecosystem.
Portworx integrated with the volume interface, and I have to say how easy it was. In a short amount of time, we were able to demonstrate the following capabilities:
- Provisioning a volume through the Portworx API.
- Attaching that volume to a Docker container through the plugin interface.
- When the Docker 1.7 runtime schedules the container to run, we are able to instantiate the volume and make the data available to the container.
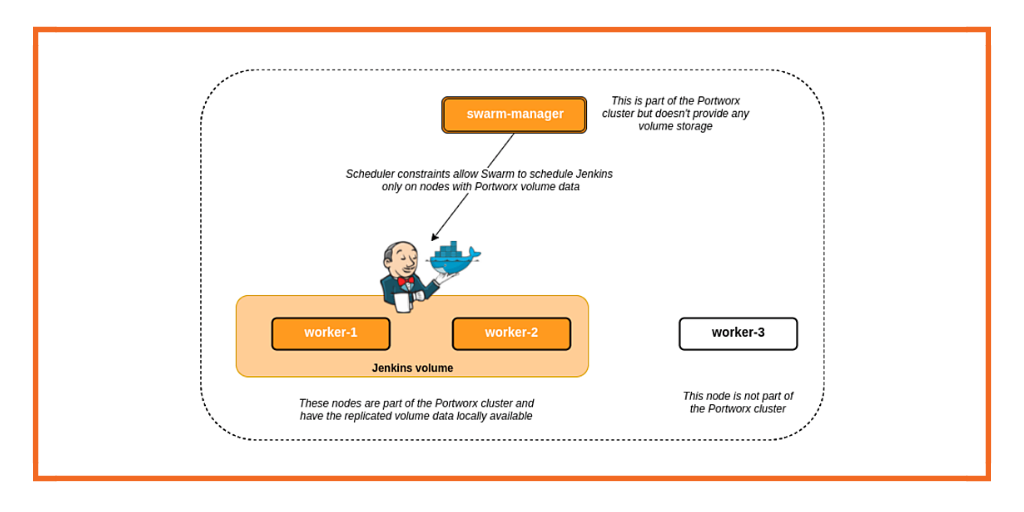
With just a little bit more effort on our part around orchestration, Portworx could demonstrate high availability of the Dockerized application. We were able to shoot a node, have the scheduler instantiate the container on a new node and, via Docker volumes, re-attach the volume to the new instance of the container and maintain high availability of the application and its data, all in a Docker centric way. Here’s a deep dive into how we make that happen: Portworx volume plugin for docker.
We’ll be making our driver available soon at http://openstorage.org. I’ll update this blog with a link to the code on Github in a few days. We’ll also be making a spec available to facilitate the orchestration of volume provisioning. Keep an eye out for that. Provisioning volumes via Docker and passing in volume properties is an integral part of this puzzle and to that end we are watching this PR closely:https://github.com/docker/docker/pull/14242.
Did you enjoy what you just read? Learn more about Docker storage, Kubernetes storage or DC/OS storage.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!