This blog is part of a series on debugging Kubernetes in production. In the past we’ve looked at issues with stuck volumes on AWS EBS and Microsoft Azure including `failed mount,` `failed attach,` and `volume is already exclusively attached to one node and can’t be attached to another.` These errors are common when using a traditional block storage device for container storage. In this post, we’ll look at common errors when using GlusterFS on Kubernetes, a popular choice on Red Hat OpenShift.
GlusterFS is a popular file storage system, originally developed in 2005 and acquired by Red Hat in 2011. In a 2014 user survey, results showed that the main use cases for GlusterFS were File Sharing and Virtual Machine Image Storage, not stateful workloads like databases or big data, data analytics, streaming or machine learning/AI workloads common on OpenShift. GlusterFS was designed for large scale file storage associated typically a small number of volumes and an assumption that a storage administrator would manage the infrequent volume provisioning required for these workloads. GlusterFS is a very good storage system for its intended use cases. These important use cases that GlusterFS was designed to handle are very different from a typical container environment managed by Kubernetes or OpenShift, in which you have a large number of relatively small volumes (10 GB-1TB) that are frequently provisioned and moved as workloads are dynamically and automatically scheduled across the cluster.
Kubernetes-based applications backed by GlusterFS volumes often come across common errors during the following situations:
- Node Failure
- Disk Failure
- Control Plane Failure
- Storage Pod Restart/Failure
- Network Failure/Partition
- High Load/Large Scale
- Capacity Planning
In this blog post, we will look at some of the most common of these errors, why they occur and how to fix them.
Background of GlusterFS
In order to talk about a few of the errors below, we need to dig into how GlusterFS works. GlusterFS has typically serviced file-based workloads, meaning you get a filesystem like you would with an NFS share, not a raw block device. This means that GlusterFS is not optimized for database workloads. To solve this issue, Red Hat introduced Gluster-block, an interface that enables block devices for single-writer applications such as a database without the overhead of metadata lookups typical to a file-based solution.
Gluster-block allows applications to provision block devices and export them as iSCSI LUN’s across multiple nodes, and uses iSCSI protocol for data transfer as SCSI block/commands. The way this architecture is exposed by GlusterFS is by first creating a “block-hosting” volume which houses the block devices applications will use. This block-hosting volume is actually a GlusterFS (file) volume that block volumes will be created on. Block volumes don’t have their own volume-granular settings, they inherit the replication factor of the file volume they sit on.
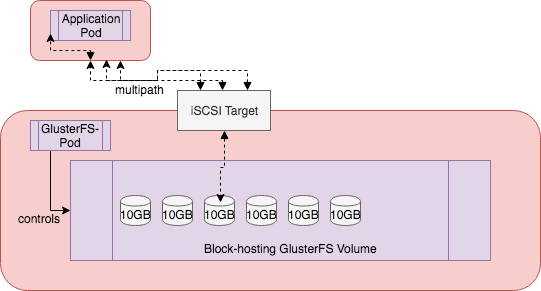
Another key part of the system is Heketi. GlusterFS was traditionally designed to be administered via CLI by a storage operator. To work in more dynamic environments such a Kubernetes, Heketi provides a RESTful interface which is used to manage GlusterFS volumes. This component is what the Kubernetes GlusterFS volume plugin will talk to in order to provision PVCs for applications. Heketi is the Kubernetes control plane for Red Hat OpenShift Storage.
With that background out of the way, let’s dig into some errors.
GlusterFS Error: ‘Multi-Attach error for volume “pvc” Volume is already used by pod(s)’
Example output failing when trying to run MySQL with Gluster-block:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 52s default-scheduler Successfully assigned mysql-547479db5b-dm2qs to ip-172-31-17-161.us-west-2.compute.internal Warning FailedAttachVolume 52s attachdetach-controller Multi-Attach error for volume "pvc-73262642-b5ee-11e8-ac27-062851c48224" Volume is already used by pod(s) mysql-547479db5b-8scqd
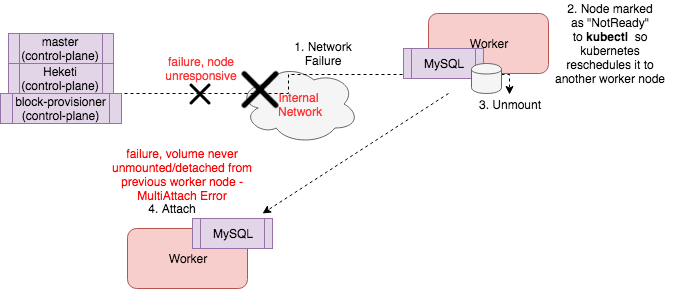
This error occurs when you try to mount a volume to a pod on one host, but it is already attached to another host. This is a common error seen when using Amazon EBS, but also happens with GlusterFS’s Gluster-block implementation and many other software-defined storage solutions that do not sufficiently abstract container storage away from physical block devices. This error occurred frequently when a network failure or partition occurs or when a node suddenly fails, for example, due to a kernel panic. You can see in the diagrams below how during a network failure or node failure this type of can error occur.
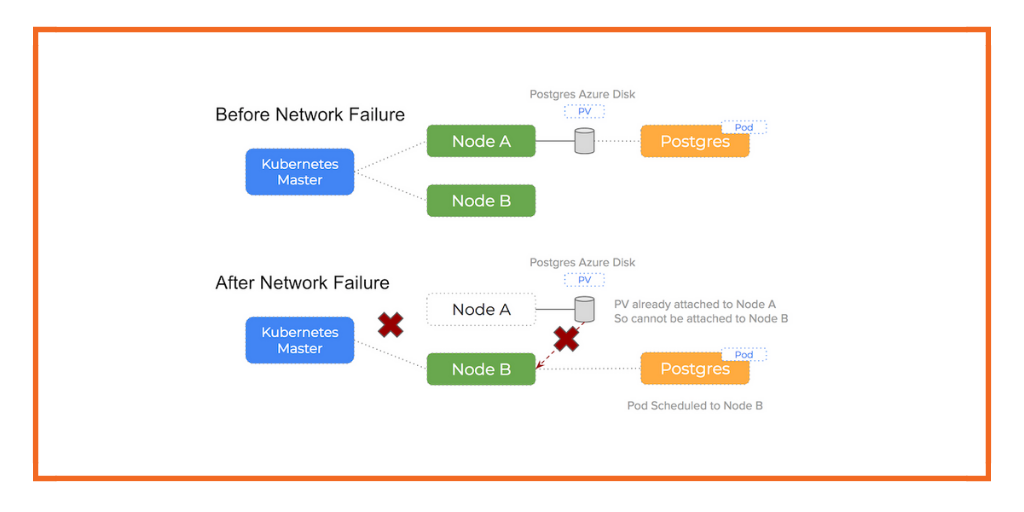
Network Partition/Failure
The below image shows the Kubernetes and GlusterFS control plane when it is unable to reach a worker node due to network failure between it and the worker node. It is unable to find needed information or run commands to properly unmount the volume before the MySQL pod is rescheduled to another worker which leads to the “Multi-Attach” error.
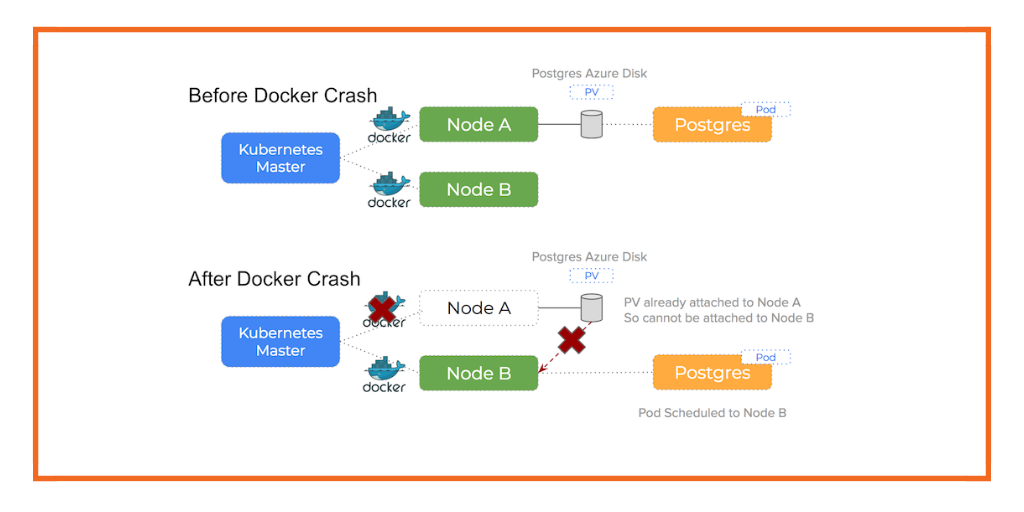
Node Crash/Failure
The below image shows a node failing and therefore Kubernetes reschedules the pod, but the volume already seems attached to the control plane because it was unable to contact the failed node to unmount it.
GlusterFS Error: ‘Provisioning Failed Failed to provision volume with StorageClass “GlusterFS-storage”: GlusterFS: create volume err: error creating volume Failed to allocate new volume: No space’
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ExternalProvisioning 15m (x25 over 16m) persistentvolume-controller waiting for a volume to be created, either by external provisioner "gluster.org/glusterblock" or manually created by system administrator Normal Provisioning 14m (x4 over 16m) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 External provisioner is provisioning volume for claim "kube-system/fio-data2" Warning ProvisioningFailed 14m gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 Failed to provision volume with StorageClass "GlusterFS-storage-block": failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: Failed to allocate new block volume: No space
This error occurs when your application is requesting more storage than is available in the underlying gluster-block volumes that has been provisioned. The “No Space” issue can come up in a few different circumstances. Here are some examples.
Size of the block hosting volume is too large relative to backing store disks.
This type of error could occur because of misconfiguration needed to enable Gluster-block. To enable Gluster-block volumes for databases in a hyperconverged deployment, operators will need to provide a setting called `openshift_storage_GlusterFS_block_host_vol_size`. This setting is asking for the size of the “block hosting” Gluster-file volume that will house the Gluster-block volumes. It’s important to make sure of a couple of things.
- It is not bigger than the amount of underlying disk storage as itself, it must fit within the size of the underlying storage passed in through
`glusterfs_devices`. - It’s big enough for growth. Block volumes use the space inside this volume when provisioned, while more of these “backing” volumes can be provisioned if there is space available.
- There is a set default maximum of (15) of the block-hosting volumes. Doing the math is important for future capacity planning.
Block volume is “full” even though no data has been written
As mentioned above, capacity planning is one thing, but let’s say you provisioned a 200GB block-hosting volume and your backing store disks on each host are 300GB. You would run out of block storage space with only four 50 GB provisioned persistent volumes because the block-hosting volumes are not thin provisioning. In other words, even if no IO has happened, you will be out of space. To keep provisioning PVC, GlusterFS will need to provision another block-hosting volume of 200GB to add capacity, it can’t, because there is only 100GB of storage left on your block devices which GlusterFS depends on and since it can’t create it, the 100GB is now wasted. Various combinations of this will have you receive a `No Space` error. While planning these particulars carefully, creating more worker nodes and over provisioning can help, there is cost and operational overhead associated with these choices. A picture of this scenario is depicted below.
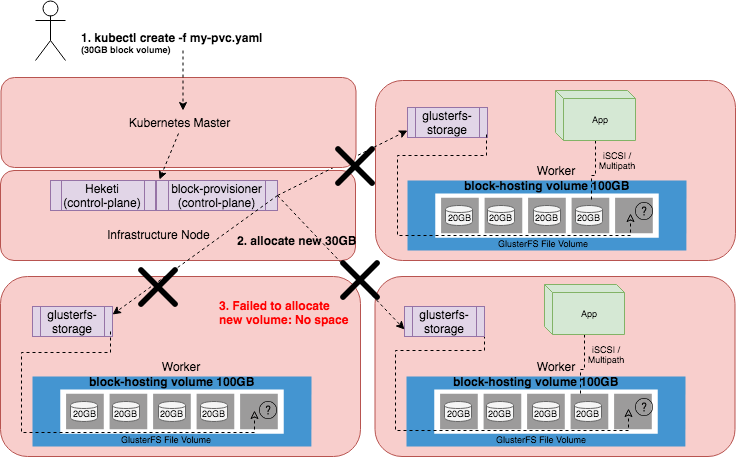
The above diagram shows an example deployment of 5 nodes. 1 Infrastructure node which runs the Heketi and Block Provisioner GlusterFS control plane, 1 Master, and 3 Workers. Each worker runs GlusterFS pods in a converged manner and has a single 100GB block-hosting volume configured on top of the raw disk, which is also 100GB. There are 4 PVCs each configured to be 20GB and because Gluster-block inherits the 3 replicas of the block-hosting volume, each 20GB is consumed on each of the Workers. When a new PVC of 30GB is requested, it fails, because there is only 20GB of space left within the 100GB block-hosting volume to host the new block device, and thus the system responds with a `No Space` error.
GlusterFS Error: “temporarily rejecting block volume request: pending block-hosting-volume found”
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Provisioning 4s (x5 over 20s) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a520a800005 External provisioner is provisioning volume for claim "default/mysql-data" Warning ProvisioningFailed 4s (x5 over 22s) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 Failed to provision volume with StorageClass "GlusterFS-storage-block": failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: temporarily rejecting block volume request: pending block-hosting-volume found
The above error often happens when a “block-hosting” volume wasn’t initially created and setup.
To resolve, make sure that you set the `openshift_storage_GlusterFS_block_host_vol_size` parameter we saw above while installing the cluster.
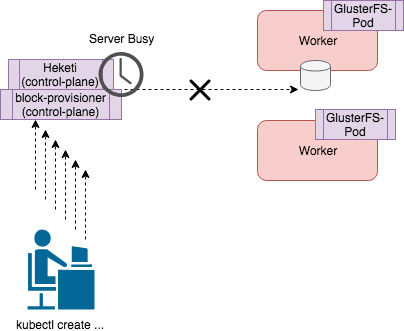
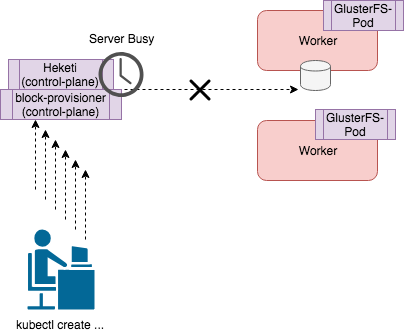
GlusterFS Error: “heketi block volume creation failed: [heketi] failed to create volume: Server busy. Retry operation later”
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ExternalProvisioning 2m (x25 over 3m) persistentvolume-controller waiting for a volume to be created, either by external provisioner "gluster.org/glusterblock" or manually created by system administrator Warning ProvisioningFailed 1m (x11 over 2m) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 Failed to provision volume with StorageClass "GlusterFS-storage-block": failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: Server busy. Retry operation later.
The above error shows up frequently in large OpenShift environments. When many volumes are being created and deleted (at the scale of thousands of volumes) you will see the error “failed to create volume: Server busy. Retry operation later” from the “describe pvc” command. The reason is that the control plane of Heketi and block-storage-provisioner are deployed to only a few containers and this causes a bottleneck. When trying to handle many Create and Delete requests for PVCs, the control plane becomes overwhelmed and causes delays in provisioning. The solution is to deploy fewer volumes, or to wait until each volume has been provisioned before creating another volume.
GlusterFS Error: ‘Multi-Attach error for volume ” to “failed to get any path for iscsi disk, last err seen: iscsi:’
Warning FailedMount 2m kubelet, ip-172-31-78-222.ec2.internal MountVolume.WaitForAttach failed for volume "pvc-fb7ae957-cb01-11e8-8652-0234bfdfcf86" : failed to get any path for iscsi disk, last err seen: Could not attach disk: Timeout after 10s Warning FailedMount 1m (x4 over 8m) kubelet, ip-172-31-78-222.ec2.internal Unable to mount volumes for pod "mysql-59f95b7885-2c82h_default(c27ee248-cb03-11e8-8652-0234bfdfcf86)": timeout expired waiting for volumes to attach or mount for pod "default"/"mysql-59f95b7885-2c82h". list of unmounted volumes=[mysql-data]. list of unattached volumes=[mysql-data default-token-9f6pf] Normal Pulling 34s kubelet, ip-172-31-78-222.ec2.internal pulling image "mysql:5.6" Normal Pulled 27s kubelet, ip-172-31-78-222.ec2.internal Successfully pulled image "mysql:5.6" Normal Created 27s kubelet, ip-172-31-78-222.ec2.internal Created container Normal Started 27s kubelet, ip-172-31-78-222.ec2.internal Started container
The above error has a few different flavors. The two most common are “… iscsi: failed to update iscsi node to portal” and “ … iscsi: could not attach disk: Timeout after 10s”.
These errors can occur in a few different situations. One reason could be node failure or another could be because Gluster-block relies on the dependency of iSCSI (iscsid) daemon on the Linux hosts. This is fairly common for storage platforms, however this means any issues with these dependencies could cause errors like this one. Other causes could be an internal metadata mismatch on path or portal.
As you can see in the above bash output “(x4 over 8m)”, during node failure, it can take 8 minutes for Gluster to properly recover from the node failure, outputting the message “failed to get any path for iscsi disk, last err seen”. You can try restarting the pod or recovering the node for a solution.
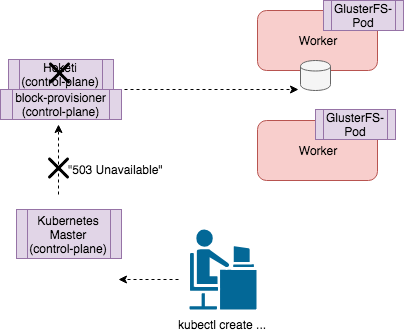
GlusterFS error: ‘Failed to provision volume with StorageClass “GlusterFS-storage-block”: failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: server did not provide a message (status 503: Service Unavailable)’
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Provisioning 4s (x5 over 22s) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 External provisioner is provisioning volume for claim "default/mysql-data" Warning ProvisioningFailed 4s (x5 over 22s) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 Failed to provision volume with StorageClass "GlusterFS-storage-block": failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: server did not provide a message (status 503: Service Unavailable)
The error above happens during installations of GlusterFS where there is a single Heketi and Gluster-block Provisioner container (control plane). This does not provide much high availability for the control plane in the event of an error. The “503” errors occur when the node or container of one of these services failed, could not be accessed over the network or was restarted.
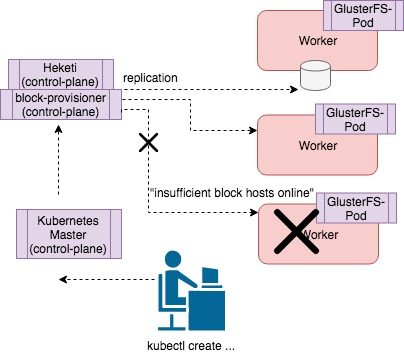
GlusterFS error: `Failed to provision volume with StorageClass “GlusterFS-storage-block”: failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: insufficient block hosts online`
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Provisioning 4s (x5 over 22s) gluster.org/glusterblock 4e0a0983-b692-11e8-a360-0a580a800005 External provisioner is provisioning volume for claim "default/mysql-data" Warning Provisioning Failed Failed to provision volume with StorageClass "GlusterFS-storage-block": failed to create volume: heketi block volume creation failed: [heketi] failed to create volume: insufficient block hosts online
Gluster-block uses a 3-way replicated file volume to host the block volume, meaning there are three replicas of the data spread across three different hosts. If there are less than three hosts available that are healthy, or there are less than three hosts available with enough storage, you will run into a similar error. The below diagram shows the scenario where there is a small three-node cluster and one node is not healthy. As a result, the third replica of the volume cannot be written to a valid healthy host and therefore, will return with “insufficient block hosts online”.
Conclusion
We hope that the above explanations have helped you understand some common errors you may run into when trying to use GlusterFS for your Kubernetes or OpenShift cluster. At Portworx, we’re big fans of GlusterFS for file workloads. If the errors above are giving you trouble, we hope you will consider Portworx for your database projects on Kubernetes and OpenShift. Portworx is a Red Hat partner and PX-Enterprise, our flagship product, is certified on OpenShift. We hope you’ll check it out.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!