
By their nature – cryptocurrency nodes are append only databases. This means the storage requirements for the node will always be increasing in direct correlation to the number of transactions processed per second.
As the popularity of cryptocurrency increases over the next few years – we will see a huge increase in the storage requirements for running these nodes. In December 2017, the size of the Bitcoin ledger is 149 gigabytes and this is predicted to grow exponentially into Terabytes of data over the coming years as more and more payments are made as adoption increases.
This will increase in direct correlation to the number of nodes you run in parallel – each will need their own writable copy of the ledger and if you are running at any kind of scale (hundreds or even thousands of nodes) – the storage requirements become an operational issue.
Ever growing ledger size
For two reasons – the storage requirements for blockchain systems will grow for two reasons:
- As the userbase grows – there are more transactions happening per second
- Each transaction increases the size of the ledger and because it is append-only there is always an upward trend in storage consumption
Compare this to mutable systems where values are replaced and you can see that as we go forward in time – we start to suffer from the ever growing ledger size.
There are ways to prune the ledger size but it is a growing concern that in a few years the size of these ledgers will grow beyond the reasonable size of available disks.
In a traditional cloud based application – where you might be using a database such as Cassandra – it would be possible to add new nodes to the cluster and as such, increase your storage capacity to solve this problem.
However – blockchain systems are databases and as such it is not an option to simply use a distributed database as the underlying storage mechanism.
We could do a hack and implement a FUSE filesystem that actually wrote data to a Cassandra cluster – but this would directly impact performance and the performance of cryptocurrency nodes can directly correlate to profits when running at scale
Put simply, we need a solution that allows us to grow our storage capacity without affecting performance or having to perform migrations that will mean down-time.
Portworx storage pool
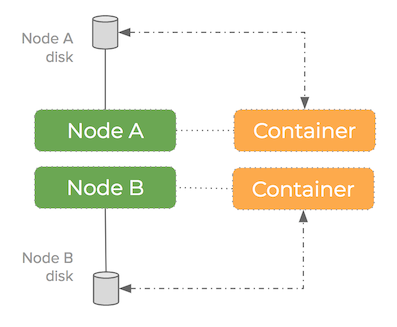
Portworx takes a different approach to the traditional approach of connecting a single disk to a container – it pools the underlying disk drives into a storage fabric.
How it looks using a single disk per container:
And how it looks when we pool disks and decouple the storage from the containers:
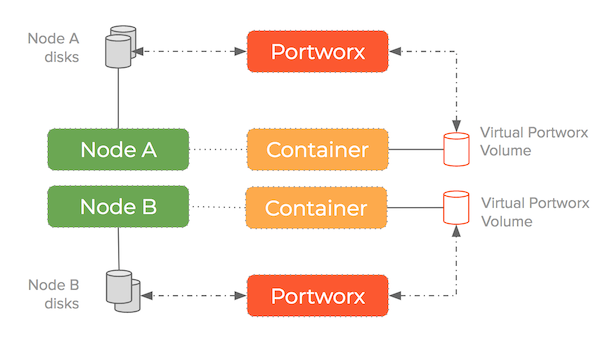
This setup means containers get virtual slices of the underlying storage pool on demand. It is able to replicate data to multiple nodes and work alongside schedulers such as Kubernetes to ensure containers and data converge efficiently.
However – the feature we will take a look at today is it’s ability to:
present a volume to a container that is LARGER than any of your physical disks
Running out of space on a physical disk
Imagine you have a 1TB disk and your dataset is using 99% of that disk. A one percent increase in your dataset leads to a dreaded disk is full message.
This normally results in having to add a larger disk to the node, bringing down the existing container and then switching it to use the new, larger disk. You also have the problem that the new disk is empty meaning the cryptocurrency node would have to re-download the entire ledger – which can take some time and that means prolonged downtime for your service. The other solution is to copy the contents of the old disk onto the new disk and whilst being faster – would still require downtime and introduces operational complexity that could be avoided if using Portworx.
Think of this as having 2 boxes for stuff – one is X big and the other is 2X big. As we add stuff to the first smaller box – we are filling it up. Because each box is entirely seperate from the other – once the smaller box is full, we would have to take all the stuff out of the first box, put it into the second and then continue filling up the second box.
The key factor here is:
there is a one-to-one mapping of physical storage onto a container volume
If the disk fills up – you have to switch out to a larger disk:
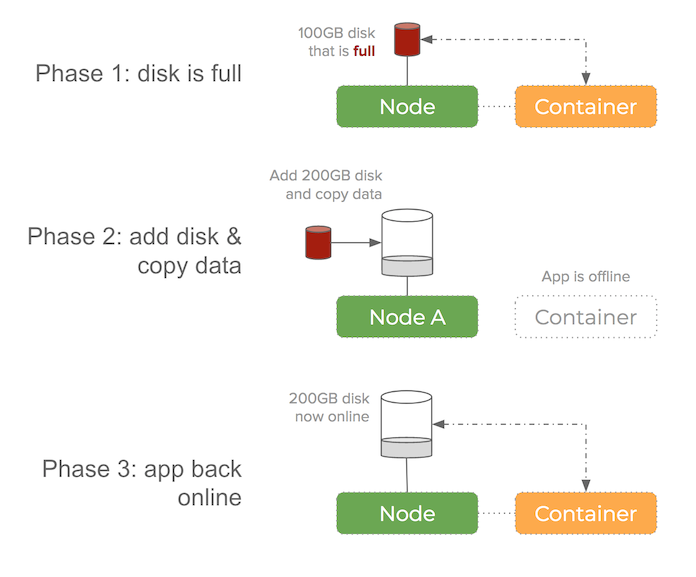
You then have another problem – what if the ledger size for a cryptocurrency node starts to become larger than the capacity of any of your disks?
Using the Portworx storage fabric
Because Portworx decouples storage from containers – it means we have a software defined storage fabric sat in between the container itself and the underlying storage resources.
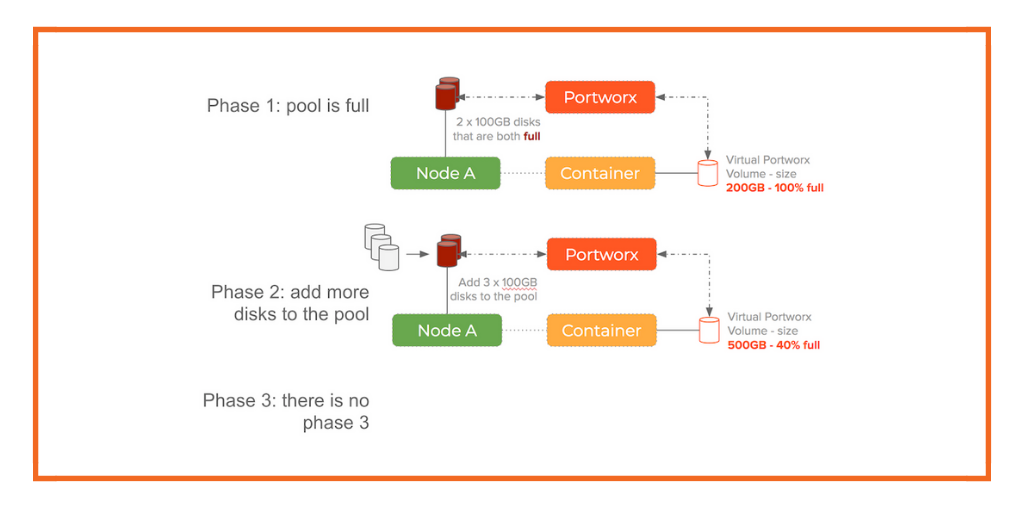
This means we can:
- Add disks to the storage pool without stopping any containers
- Increase the size of a container volume without stopping the container
- Have a container volume that is bigger than any of the physical disks
Back to our storage in a box example – we now have a funnel we can put stuff into that is aware of how full each box is and intelligently put it into a box that has the space.
From a logical perspective – we have one very large box – we don’t have to worry about what box is full and what box we should put the next thing into. The clever funnel does this for us.
Portworx does exactly this but for data and disks – it is able to route writes to any of the underlying storage devices but still present a logical volume to a container that is comprised of a combination of all these disks. The container just sees a massive disk!
Think of this like RAID0 but for a cluster of machines. Add in the fact that Portworx is able to synchronously replicate the data at the same time and we have:
A cluster aware, software defined RAID0 and RAID1 solution for containers
Let’s see how this works from a cluster perspective:
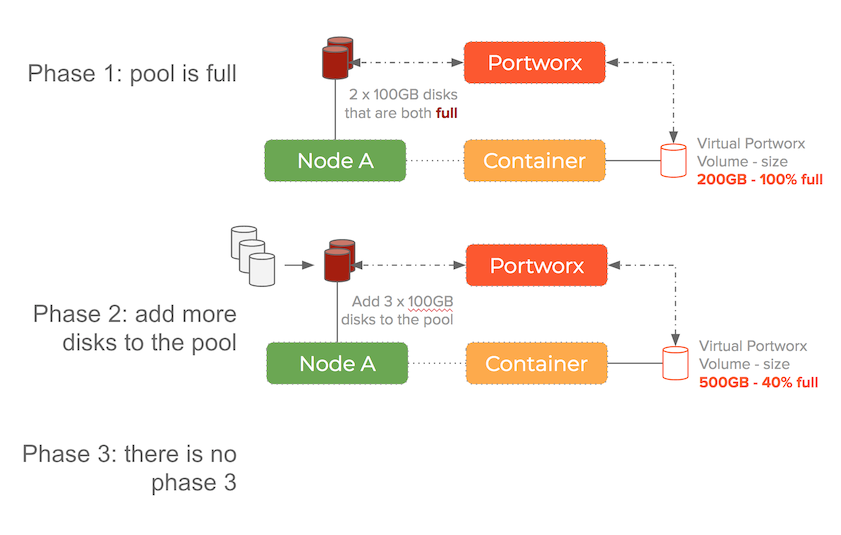
The main point is that from an operational perspective – you want to separate the following two things:
- For each container how much storage of it’s volume is it using – if getting full then dynamically resize
- For the whole cluster – what is my total storage pool capacity – if getting full then dynamically add storage devices
These operations become simple using pxctl – the command line tool that manages a Portworx cluster.
In both cases – without restarting containers, you can grow the size of a container volume and add devices to the underlying storage pool.
This vastly simplifies the operational complexity of running a storage intensize cluster which becomes especially useful for cryptocurrency nodes.
The ability to have a container volume that is larger than any of your physical disks is literally impossible without using some kind of Software Defined Storage solution and Portworx is the leader in it’s field with many customers running in production.
Conclusion
As cryptocurrencies gain adoption – the storage challenges we see today will only grow exponentially. It’s important to get the foundation of your system solid before the real challenge of global usage arrives.
To summarise, the key to how to deal with the ever growing ledger size:
- Use a software defined storage solution that de-couples storage from containers
- You can then add storage devices to your pool to increase the total capacity
- Then increase the logical size of your container volume
- The solution you use should be able to do these two things without container downtime
Make sure you also read the other posts in this series:
- How to run production blockchain applications using Portworx
- Using Portworx to improve mining pool performance
- Acceptance test smart contracts with Portworx to avoid expensive mistakes
Be sure to download and try Portworx today so you can see how it works and get a feel for the product – it’s free to try for 30 days!
Here are some links that you might find useful to find out more about our product and awesome team:
* Docs
* Product introduction
* Our customers
* Team
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.
