
Kubernetes is one of the fastest growing open source projects in recent times. Kubernetes abstracts away infrastructure resources so that you can run your containerized workloads on any cloud, bare metal server or even on your local laptop using minikube. The challenge with a fast evolving project like Kubernetes is that you have to stay current with upstream releases. Unless you have in-house Kubernetes experts, you should consider running your production workloads on a hosted managed Kubernetes cluster. Hosted managed Kubernetes clusters are available from all the major cloud providers. Today’s post will look at running a mission-critical application across multiple Kubernetes clusters running on Google Kubernetes Engine (GKE). The same workflow can be accomplished on any Kubernetes service when you use Portworx.
Why GKE?
GKE is a hosted managed offering of Kubernetes from Google Cloud. Some of the benefits of using GKE for your containerized workloads include:
- Setup of a highly available Kubernetes cluster across availability zones
- Autoscaling of Kubernetes worker nodes
- Auto-upgradability of your Kubernetes worker nodes
- Integrated logging & monitoring service
Why Portworx Enterprise?
Portworx Enterprise is a cloud native storage and data management platform trusted in production by over 100 customers and dozens of the Fortune Global 2000. The Portworx Enterprise platform allows GKE customers to run mission-critical stateful applications on Kubernetes with the reliability, performance and security of a traditional enterprise-class storage solution, but with the agility, speed and automation you expect for cloud native applications. The Portworx solution provides the following benefits to containerized mission-critical applications:
- Data availability by being datacenter topology-aware for HA across racks and availability zones along with scheduled snapshots & auto-scaling capabilities
- Data security by providing encryption at rest and in flight, Google KMS integration and role-based access controls integrated with Corporate Auth systems
- Data management features like dynamic scaling of storage, thin provisioning and application consistent snapshots and backups
- Disaster recovery by easily migrating applications and data between GKE clusters in the same data center or across data centers.
Portworx Enterprise is available today via the Google Cloud Platform (GCP) Marketplace.
Migrating Gitlab between Kubernetes Clusters
If your Kubernetes applications are stateless, moving them between clusters is straightforward. At a high level, the solution may involve dumping Kubernetes object configuration (deployments, service accounts, etc) in a given namespace to a Google Cloud Storage bucket or a git repository of your choice for recovery purposes. Then you can use the recovery location’s artifacts to redeploy the saved objects to the restored cluster, thus recovering your stateless applications. In this article, we will not focus on these stateless application migrations but rather focus on stateful apps.
When you put your business-critical stateful applications like Gitlab in a Kubernetes cluster, you have to ensure that all aspects of the application lifecycle are covered in order to recover your application after a cluster failure.
For stateful applications like Gitlab, you have to not only backup configured Kubernetes objects like PVs, PVCs, stateful sets, service accounts, etc. but also the volumes associated with your applications. If you do not back up the data as well as the application configuration, the difficulty and time it takes to recover your application after a disaster increases greatly. One of the most common reasons that DR projects fail is not because data is not backed up. It is because applications cannot be restored. Portworx solves this recoverability challenge directly by ensuring that data and app config are backed up together.
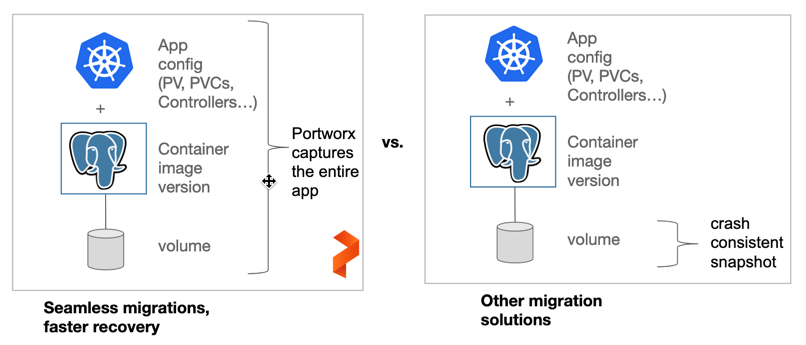
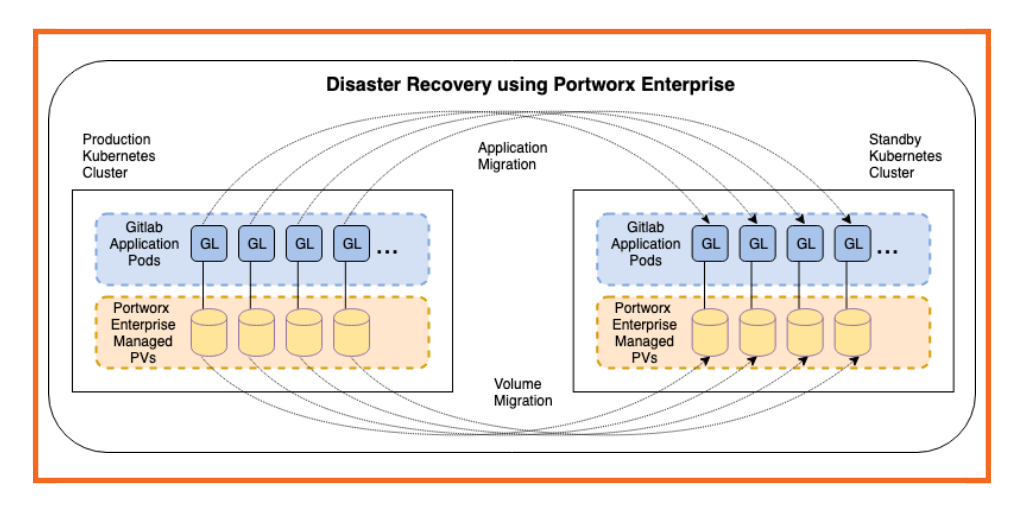
In order to address business continuity of the deployed services, one approach is to have a standby or backup cluster where you can sync configured Kubernetes objects and persistent volumes on a continuous, on-demand or user-specified frequency. This ensures that in the case of a failure in your primary data center or cluster, you can recover in the standby cluster. For data centers located in a metro area, this results in RPO-zero failover. For data centers located across the WAN, the result is an RPO determined by the user-configured backup frequency. In both cases, RTO is very low, since recovery entails only redeploying Kubernetes pods in the standby location.
In addition to the business continuity use case, you may want to implement a standby or backup cluster in the following scenarios:
- Test N+1 versions of your application with a particular version of Kubernetes.
- Migrate production application data back into a development cluster for detailed debugging without redeploying your applications and or restoring from volume snapshots.
- Expand your application workloads into another cluster for additional capacity and multi-cloud strategy.
The following instructions describe the steps needed to successfully migrate the Gitlab application, including its data, to another cluster.
-
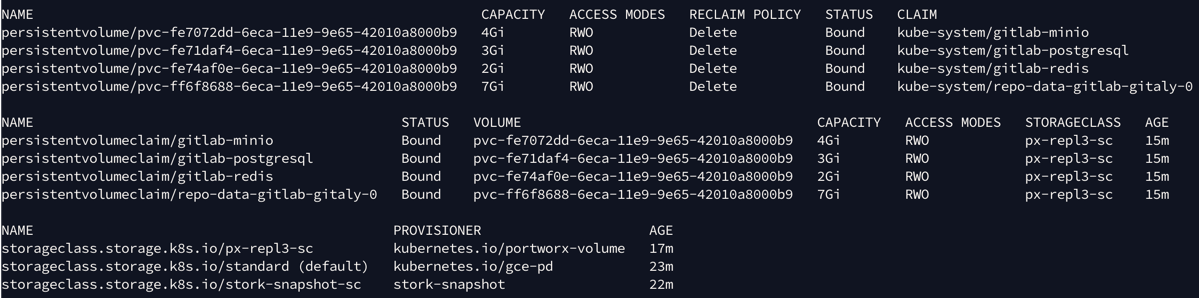
- Configure the Gitlab application to use Portworx Enterprise provisioned volumes. In the image below, four volumes were provisioned for the Gitlab application using the Portworx Enterprise storage class which has a replication factor of three.
-
- We will ensure that two Kubernetes clusters have established trust between them so that the clusters are allowed to migrate applications, resources and persistent volumes between them. You can read more about the migration concept here. Exact steps to generate the migration configuration can be found here. Establishing trust between paired clusters is done using a token.
- Once the trust is established between the paired clusters, we can migrate the deployed stateful application using an ad-hoc migration task. In the command below, we are creating a migration task called gitlab-migration using stork CLI to migrate gitlab namespace to a different cluster using clusterpair called cluster.
storkctl create migration -n gitlab --namespaces gitlab -c cluster gitlab-migration
In the image below, you will notice that the migration task has migrated 78 Kubernetes resources to the standby cluster. The migration task also migrated the four persistent volumes to the standby cluster.

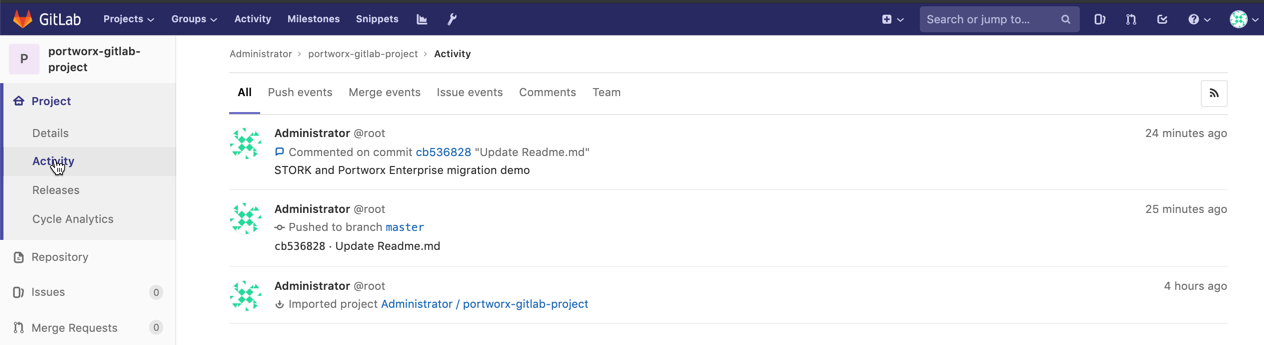
- Once the migration of application data and Kubernetes objects to the standby cluster is completed, you can switch your web traffic to the new cluster and make it the primary. The image below shows that the Gitlab application is running in the new cluster and git commits and persistent volumes are in the new cluster.
Where do we go from here?
The detailed steps needed to install Portworx Enterprise through the GCP Marketplace are described here.
Please visit the GCP Marketplace and try out Portworx Enterprise offering for GKE. If you would like to learn more about the Portworx Enterprise solution, please visit the GKE section of our docs page. Join our Slack channel to discuss how Portworx Enterprise on GKE can help you run stateful workloads in production.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Dinesh Israni
Dinesh Israni is a Principal Software Engineer at Portworx with over 12 years of experience building Distributed Storage solutions. Currently, he is working on developing cloud native storage technology and is the lead for the open source project STORK. He is working on integrating cloud native solutions with container orchestrators like Kubernetes and DC/OS, helping customers deploy their cloud native applications more efficiently at scale.

Vick Kelkar
Vick is Director of Product at Portworx. With over 15 years in the technology and software industry, Vick’s focus is on developing new data infrastructure products for platforms like Kubernetes, Docker, PCF, and PKS.



