
Chapter 1: The Paradigm Shift: From ClickOps to GitOps

This blog is part of Demystifying Kubernetes for the VMware Admin, a 10-part blog series that gives VMware admins a clear roadmap into Kubernetes. The series connects familiar VMware concepts to Kubernetes—covering compute, storage, networking, security, operations, and more—so teams can modernize with confidence and plan for what comes next.
The VMware era shaped a generation of infrastructure professionals. You learned to manage data centers through vCenter’s interface. You clicked through wizards, configured VMs, and built reliable infrastructure that powered enterprises for decades. That expertise has proven value.
But the ground is shifting beneath your feet.
Broadcom’s acquisition of VMware changed the economics overnight. License costs increased dramatically. Support models shifted. Organizations that ran VMware for 15 years are now questioning their infrastructure strategy for the first time.
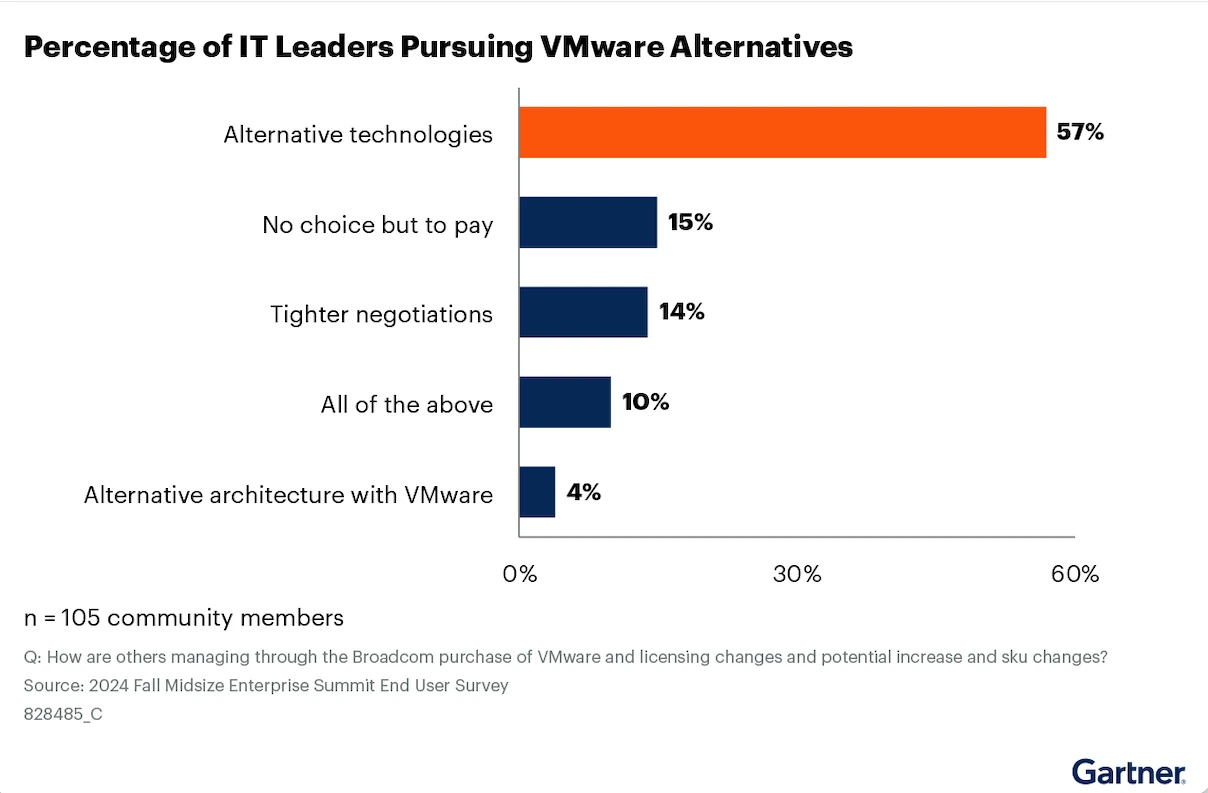
This isn’t about whether Broadcom is right or wrong. This is about recognizing a forcing function. The acquisition accelerated a transition that was already underway. Kubernetes adoption has grown steadily for years. The Broadcom catalyst compressed years of gradual change into months of accelerated decisions.
Your organization faces a choice. Pay significantly more for the same VMware capabilities. Or invest that budget into building cloud-native infrastructure skills. Many organizations are choosing option two.
Now you need to make it happen!
This is a forcing function for VM admins like you. The real question is how you move forward without starting over. You already understand infrastructure. You know networking, storage, compute, and security. Those concepts translate directly to Kubernetes. The mental models you built over years of VMware work remain valuable. You need to learn new tools and new workflows, not new fundamentals.
At Portworx, we have built this 10-part series to demystify Kubernetes from a VM admin’s perspective. This series will map VMware concepts to their Kubernetes equivalents. Each part addresses a domain you already understand and shows how it translates to the cloud-native world.This blog series will guide you through that transition.
Let’s start with the basics in the blog – from ClickOps to GitOps.
The ClickOps Model and Its Limits
Let’s start with the most significant shift: how you operate infrastructure.
VMware built its success on making complex operations accessible through graphical interfaces. vCenter provides a single pane of glass for your entire infrastructure. You point, click, configure, and deploy.
This model works. Millions of VMs run in production because administrators used vCenter’s interface to create them. The GUI provides immediate feedback. You see your changes reflected in real time. Error messages appear in dialog boxes. Logs populate in dedicated windows.
Consider how you deploy a new VM today:
You log into vCenter. You right-click a cluster. You select “New Virtual Machine.” You walk through a wizard. You select a template. You configure CPU, memory, and disk. You choose a network. You click through screens until you reach “Finish.”
The VM appears in your inventory. You watch its creation progress. It powers on. You move to the next task.
This workflow is called ClickOps. Operations driven by clicking through graphical interfaces.
ClickOps delivers immediate satisfaction. You see results instantly. The learning curve feels manageable because the interface guides you. VMware invested heavily in UX design to make infrastructure management approachable.
Advanced VMware professionals recognized the limits of manual operations years ago. Many adopted Infrastructure as Code tools to automate provisioning. Terraform modules deploy VMs consistently. Ansible playbooks configure guest operating systems. PowerCLI scripts batch repetitive tasks. vRealize Automation provides self-service catalogs backed by code. These approaches bring version control and repeatability to VMware environments. They represent a significant step toward declarative infrastructure. Yet IaC adoption within VMware shops remains uneven. Many administrators prefer the GUI for its immediacy and visual feedback. Some organizations lack the development culture required for IaC. Others invested in automation only for specific use cases while handling everything else manually. The result is a spectrum: some teams operate almost entirely through code, while others rarely leave vCenter’s interface.
But ClickOps creates problems at scale.
Every click you make in vCenter is ephemeral. No record exists of which buttons you pressed or which options you selected. The VM exists, but the process that created it vanished the moment you clicked “Finish.”
When a colleague asks how you configured that VM, you describe it from memory. When you need to create 50 similar VMs, you click through the wizard 50 times. Or you build automation after the fact to replicate what you did manually.
Consider what happens when something breaks at 2 AM. You log into vCenter. You click through menus searching for the problem. You find it, fix it, and go back to sleep. Tomorrow, your colleague asks what happened. You explain verbally. Maybe you write it up. Maybe you don’t.
Now multiply this across a team of ten administrators over five years. Thousands of configuration decisions exist only in your current infrastructure and in the memories of the people who made them.
ClickOps also struggles with consistency. Human operators make human mistakes. The VM you create on Monday might differ slightly from the one you create on Friday. Those differences compound over time. Your infrastructure drifts from its intended state without anyone noticing.
You’ve felt this problem even if you haven’t named it. You’ve inherited VMs configured by people who left the company years ago. You’ve spent hours figuring out why one server behaves differently from its neighbors. You’ve rebuilt environments from scratch because documenting the existing state would take longer than starting over.
These aren’t VMware problems. These are ClickOps problems. The GUI made the infrastructure accessible. It also made infrastructure opaque.
The GitOps Model Kubernetes Demands
Kubernetes operates on a different philosophy. You declare the state you want. Kubernetes works continuously to make that state real.
This is declarative infrastructure. You write a YAML file describing your desired configuration. You commit that file to a Git repository. An automated process applies that configuration to your cluster. Kubernetes compares the desired state to the current state and reconciles any differences.
Consider deploying an application in Kubernetes:
You write a manifest describing your deployment. Three replicas. Two gigabytes of memory each. A specific container image. Environment variables. Health checks.
You then commit this manifest to Git. A GitOps tool like Argo CD or Flux detects the change. It applies the manifest to your cluster. Kubernetes creates the pods. The application runs.
The next day, when your colleague asks how you configured that application. You point them to the Git repository. Every detail is documented. Every change is tracked. Every decision has a timestamp and an author.
When you need to create 50 similar applications, you write a template. Or you copy and modify the manifest. The process scales because the configuration exists as code.
When something breaks at 2 AM, you check Git to see what changed recently. You revert the problematic commit. The GitOps tool detects the reversion and rolls back automatically. Tomorrow, the incident review examines the Git history. The timeline is complete and accurate.
This is GitOps. Operations driven by Git repositories as the source of truth.
The Rise of Cloud Native
GitOps is one component of a larger movement. Cloud native computing has grown from a niche approach to the dominant paradigm for modern infrastructure.
The Cloud Native Computing Foundation now hosts over 180 projects. Kubernetes sits at the center, but the ecosystem extends far beyond container orchestration. Service meshes handle traffic management. Observability platforms collect metrics, logs, and traces. Policy engines enforce security and compliance. Each project solves a specific problem. Together, they form a complete infrastructure stack.
This ecosystem delivers advantages that traditional virtualization struggles to match.
Portability becomes real. A Kubernetes manifest runs on any conformant cluster. Your application deploys the same way on AWS, Azure, Google Cloud, or your own data center. Vendor lock-in decreases because the API remains consistent across providers. Organizations run workloads where economics and requirements dictate, not where infrastructure constraints force them.
Scalability becomes automatic. Kubernetes scales pods based on CPU, memory, or custom metrics. You define thresholds. The platform responds to demand without manual intervention. Applications handle traffic spikes without operators watching dashboards and clicking buttons. Scale-down happens automatically when demand subsides, reducing costs during quiet periods.
Resilience becomes built-in. Kubernetes restarts failed containers. It reschedules workloads when nodes fail. Health checks detect problems before users notice. Self-healing behavior runs continuously without operator involvement. The platform assumes failure will occur and handles it automatically.
Resource efficiency improves. Containers share operating system kernels. They start in seconds rather than minutes. Bin-packing algorithms place workloads optimally across nodes. Organizations run more applications on fewer servers. The density gains compound as container adoption increases.
Developer velocity increases. Teams ship changes faster when deployments are automated and rollbacks are simple. The feedback loop from code commit to production shrinks from days to minutes. Developers take ownership of their applications because the deployment process is accessible and repeatable.
These advantages explain why cloud native adoption accelerates year over year. Organizations that adopt Kubernetes report faster deployment cycles, improved uptime, and lower infrastructure costs. The benefits are measurable and documented across industries.
VMware served enterprises well for two decades. Cloud native infrastructure serves them better for the workloads and economics of today.
The Statefulness Question
You have a valid concern. Data persistence is the elephant in the room for any VMware professional evaluating Kubernetes.
VMware excels at protecting stateful workloads. vMotion migrates running VMs without downtime. High Availability restarts failed VMs on healthy hosts. vSAN replicates data across the cluster. These capabilities took years to mature. You trust them because you’ve seen them work in production for over a decade.
Kubernetes was originally designed for stateless applications. The early philosophy assumed containers were ephemeral. Pods came and went. Data lived elsewhere. This worked for web frontends and microservices. It failed for databases, message queues, and legacy applications that expected persistent local storage.
That limitation no longer exists.
The Container Storage Interface (CSI) standardized how Kubernetes interacts with storage systems. Every major storage vendor now ships CSI drivers. NetApp, Pure Storage, Dell EMC, and dozens of others provide enterprise-grade integration. Your existing SAN or NAS works with Kubernetes through CSI. The storage you trust already supports the platform you’re learning.
Portworx represents the enterprise-grade answer to Kubernetes storage. It delivers software-defined storage built specifically for containers. Portworx replicates data across nodes, provides snapshots and backup, and enables disaster recovery across clusters. For VMware professionals, the capabilities feel familiar: high availability, data locality, and storage policies that follow your workloads. Portworx runs on any infrastructure, from bare metal to public cloud. It turns Kubernetes into a platform you can trust with your most demanding stateful applications.
Operators changed how Kubernetes manages complex applications. An Operator encodes operational knowledge in software. The PostgreSQL Operator handles database clustering, failover, and backup. The Kafka Operator manages broker scaling and partition rebalancing. These aren’t scripts or runbooks. They’re control loops that continuously reconcile desired state with actual state. The same pattern Kubernetes uses for pods now applies to stateful applications.
StatefulSets provide stable network identities and persistent storage for pods. When a database pod restarts, it reconnects to its existing storage and rejoins the cluster with its original hostname. The abstraction handles the complexity that vMotion handles in VMware environments.
GitOps manages configuration. CSI, Operators, and StatefulSets manage data. The combination delivers the data protection guarantees you expect from VMware. Part 5 of this series covers storage in depth. You’ll see exactly how vSAN concepts translate to Kubernetes persistent volumes and how data services like snapshots and replication work in cloud native environments.
Your concern is valid. The answer is that Kubernetes has grown up and matured.
Why This Shift Matters for Your Career and Organization
The infrastructure industry is moving toward declarative, version-controlled operations. This isn’t speculation. Job postings increasingly list Kubernetes as a requirement. Cloud providers offer managed Kubernetes services. Enterprise software vendors ship Kubernetes operators.
Your VMware skills remain relevant. Understanding compute clusters, distributed storage, and software-defined networking translates directly. The concepts match, even when the tools differ.
But you need to add new capabilities. You need to learn YAML manifests and kubectl commands. You need to understand Git workflows and CI/CD pipelines. You need to think in terms of desired state rather than manual steps.
This is an expansion, not a replacement. The administrator who understands both VMware and Kubernetes has more career options than one who knows only VMware. The market values people who bridge these worlds.
Your organization needs people who guide this transition. You understand the current state. You know which workloads run where and why. That institutional knowledge is irreplaceable during migration. Position yourself as the person who leads this change rather than the person who resists it.
Moving from ClickOps to GitOps requires cultural change. Teams accustomed to GUI-driven workflows must adopt new habits. The transition affects more than technology.
Change management becomes explicit. In ClickOps, changes happen immediately when someone clicks a button. In GitOps, changes go through pull requests. Colleagues review proposed modifications before they apply. This slows down individual changes but reduces incidents caused by hasty modifications.
Documentation becomes automatic. The Git repository serves as a living record of your infrastructure. New team members read the manifests to understand the environment. Auditors examine the commit history for compliance evidence. The documentation stays current because the documentation is the configuration.
Troubleshooting becomes traceable. When problems occur, you correlate symptoms with recent commits. The sequence of changes is recorded with precision. “What changed?” becomes an answerable question.
Rollbacks become routine. Reverting to a previous configuration means reverting to a previous commit. The process is identical whether you’re rolling back a minor tweak or a major deployment. Recovery time decreases because recovery is automated.
These organizational benefits compound over time. The initial learning curve is real. Teams invest weeks or months developing GitOps proficiency. But that investment pays dividends for years to come as operational overhead decreases and consistency improves.
The Journey Ahead
The shift from ClickOps to GitOps represents the largest operational change in enterprise infrastructure since virtualization itself. That transition happened over a decade. This one is happening faster.
You have skills that transfer. You have knowledge that matters. The question is whether you’ll add Kubernetes to your capabilities or watch colleagues do it instead.
Start small. Provision a managed Kubernetes cluster on your preferred cloud provider. AWS offers EKS. Azure provides AKS. Google Cloud runs GKE. Each provider offers free tiers or credits for learning. Deploy a simple application. Read the YAML manifest and understand what each line does. Commit the manifest to a Git repository.
The first step requires minimal investment. Most cloud providers let you run small clusters at low cost or no cost during trial periods. You begin learning this week.
What’s next in this series?
Part 2 of this series introduces KubeVirt as your bridge between worlds. You’ll see how your VM expertise applies directly to running virtual machines in Kubernetes. The skills you built over years of VMware work become assets rather than baggage.
The Broadcom acquisition forced a conversation many organizations had avoided for years. That conversation is now unavoidable. Participate in it with knowledge rather than uncertainty.
Demystifying Kubernetes – Blog series
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!
Chapter 1: From ClickOps to GitOps: Why the Paradigm Is Shifting
Economic pressure, operational philosophy changes, and what this means for VMware professionals.
Chapter 2: KubeVirt: Running Virtual Machines in a Kubernetes World
How VMs and containers coexist—and why KubeVirt is the practical bridge forward.
Learn MoreChapter 3: Mapping the Stack: From VMware SDDC to Cloud-Native Architecture
A mental model that translates vSphere, vSAN, and NSX into Kubernetes equivalents.
Learn MoreChapter 4: Compute Reimagined: ESXi Hosts vs Kubernetes Nodes
How scheduling, abstraction, and control planes differ between hypervisors and Kubernetes.
Learn MoreChapter 5: Storage Evolution: From Datastores to Persistent Volumes
Translating vSAN concepts into container-native storage and CSI-driven architectures.
Learn MoreChapter 6: Networking Translated: NSX and the Kubernetes Networking Model
CNI plugins, services, ingress, and service meshes explained for VMware practitioners.
Learn MoreChapter 7: Security Models Compared: vSphere Security vs Kubernetes Security
RBAC, isolation, policy enforcement, and shared responsibility in a cloud-native world.
Learn MoreChapter 8: Day 2 Operations: Monitoring, Lifecycle, and Reliability
How observability, upgrades, backup, and DR work once Kubernetes is in charge.
Learn MoreChapter 9: Planning the Migration: From VMware Estate to Kubernetes Platform
Assessment frameworks, migration strategies, team structure, and common pitfalls.
Learn MoreChapter 10: Beyond Migration: Building a Cloud-Native Operating Model
Platform engineering, GitOps, extensibility, and preparing for what comes next.
Learn More
Janakiram MSV
Industry AnalystJanakiram MSV (Jani) is a practicing architect, research analyst, and advisor to Silicon Valley startups. He focuses on the convergence of modern infrastructure powered by cloud-native technology and machine intelligence driven by generative AI. Before becoming an entrepreneur, he spent over a decade as a product manager and technology evangelist at Microsoft Corporation and Amazon Web Services. Janakiram regularly writes for Forbes, InfoWorld, and The New Stack, covering the latest from the technology industry. He is an international keynote speaker for internal sales conferences, product launches, and user conferences hosted by technology companies of all sizes.
Related posts



Chapter 8: Day 2 Operations: Lifecycle Management and Observability