
Chapter 6: Networking: NSX to Kubernetes Networking

This blog is part of Demystifying Kubernetes for the VMware Admin, a 10-part blog series that gives VMware admins a clear roadmap into Kubernetes. The series connects familiar VMware concepts to Kubernetes—covering compute, storage, networking, security, operations, and more—so teams can modernize with confidence and plan for what comes next.
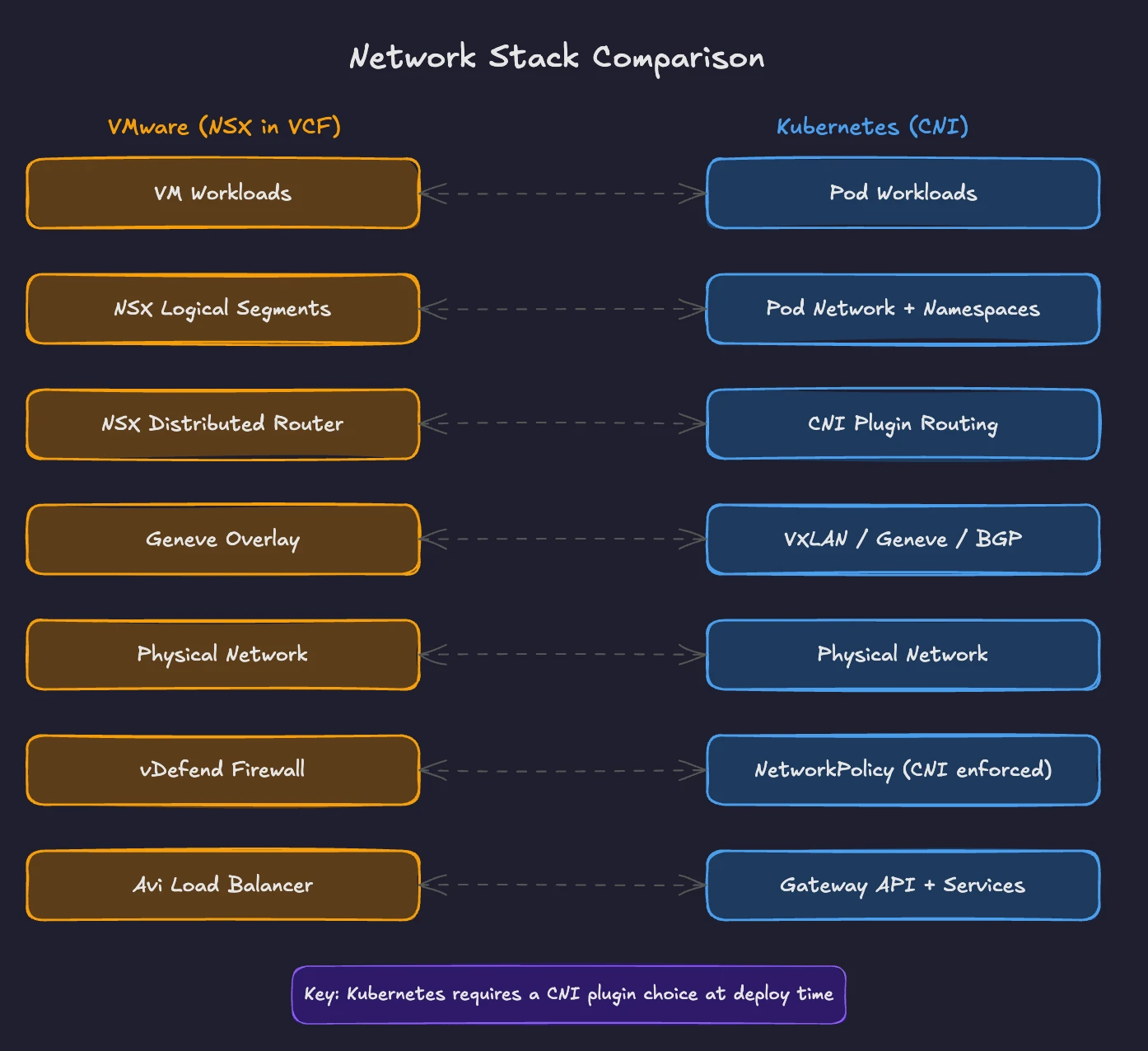
You know software-defined networking. NSX creates virtual switches, distributes routing to hypervisors, and segments traffic with firewall rules. You configure overlay networks through NSX Manager. You deploy VMware Avi Load Balancer for application delivery. The network layer is the part of the VMware stack you rely on most and understand least when mapping to Kubernetes.
Kubernetes networking follows the same principles. Virtual networks connect workloads. Policies segment traffic. Load balancers distribute requests. The implementations differ, but the goals are identical: provide connectivity, enforce isolation, and deliver traffic to the right destination.
This part maps your NSX knowledge to Kubernetes networking concepts. You will see how CNI plugins replace virtual switches, how Services and the Gateway API replace load balancers, how Network Policies replace micro-segmentation, and how service meshes extend the model for complex environments.
Virtual Switches and Overlays: NSX vs CNI Plugins
In VMware Cloud Foundation, NSX provides the virtual networking layer. NSX creates overlay networks using the Geneve (Generic Network Virtualization Encapsulation) protocol. Each ESXi host runs a distributed router and a distributed firewall. VMs connect to logical segments through these constructs. Traffic between VMs on different hosts travels through Geneve tunnels. The underlying physical network sees only tunnel endpoints, not the VM traffic inside.
Starting with VCF 9.0, NSX is available exclusively as part of the VCF stack. Standalone NSX is no longer sold. Security capabilities previously bundled with NSX are now split into VMware vDefend, a separate add-on. Security and firewall licensing is now delivered via vDefend add-ons, while NSX handles overlay transport, distributed routing, and segment management.
Kubernetes uses Container Network Interface (CNI) plugins to provide pod networking. The CNI specification is a CNCF project defining how container runtimes configure network interfaces. When Kubernetes creates a pod, it calls the CNI plugin to set up networking. When the pod terminates, the CNI plugin cleans up.
This mirrors how NSX integrates with ESXi. The hypervisor calls NSX components when a VM powers on to connect it to the right logical segment. The CNI plugin does the same for pods.
The key difference: upstream Kubernetes does not ship with a built-in networking stack. You choose a CNI plugin during cluster deployment. Most enterprise distributions and managed services make this choice for you. OpenShift defaults to OVN-Kubernetes. AKS uses Azure CNI. EKS uses the Amazon VPC CNI. You only need to think about CNI selection when building clusters from scratch or when your requirements outgrow the default. This is similar to choosing between vSphere Standard Switch and NSX, except in Kubernetes, the choice is mandatory. Every cluster needs a CNI plugin.
Three CNI plugins dominate production environments.
Cilium uses eBPF (Extended Berkeley Packet Filter) to implement networking at the kernel level. Cilium bypasses traditional iptables-based packet processing, which reduces latency and CPU overhead. It is a CNCF Graduated project and the default CNI in Canonical Kubernetes LTS. It provides networking, network policy enforcement, load balancing (replacing kube-proxy entirely), and observability through its companion tool Hubble. Cilium supports both overlay (VXLAN, Geneve) and direct routing modes. For VMware professionals, think of Cilium as the closest equivalent to NSX in ambition: a comprehensive networking and security platform built into the infrastructure layer.
Calico provides networking through BGP routing or VXLAN encapsulation. Calico is well established and known for its network policy engine. Organizations like Reddit and CoreWeave run Calico in production. Calico supports both iptables and an eBPF data plane. In BGP mode, routes pod traffic without overlay encapsulation, similar to how NSX handles routing at the hypervisor level. Calico is the default CNI in many enterprise Kubernetes distributions.
Flannel is the simplest option. It provides basic pod-to-pod connectivity using VXLAN overlay networking. It does not include network policy enforcement. Flannel works well for lightweight clusters, development environments, and situations where simplicity is the priority.
The choice between CNI plugins depends on your requirements. Need advanced security, observability, and kube-proxy replacement? Choose Cilium. Need proven enterprise networking with strong policy enforcement and BGP routing? Choose Calico. Need basic connectivity for a simple cluster? Flannel gets you started.
Load Balancing: NSX and Avi vs Kubernetes Services and Gateway API
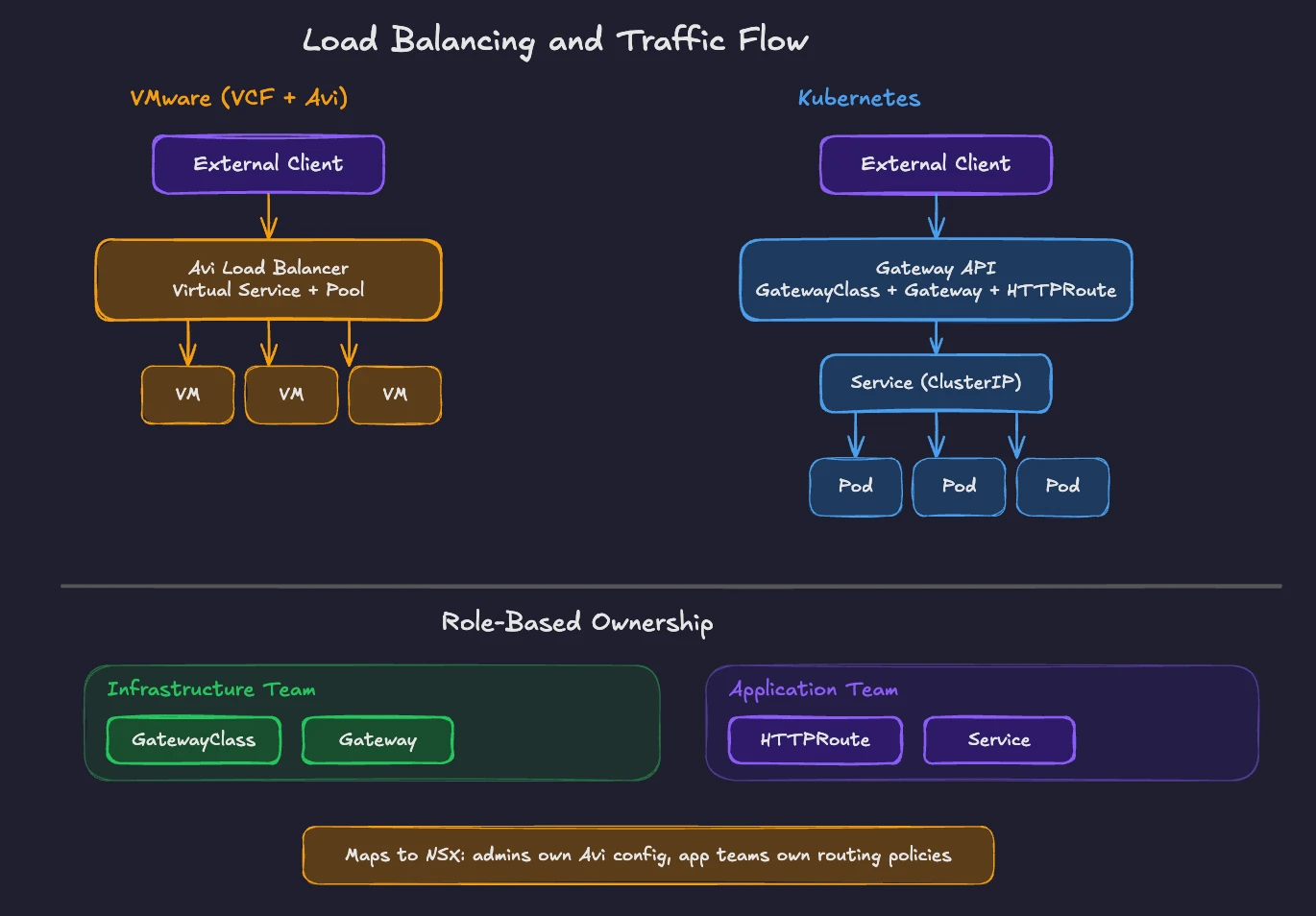
In VCF, load balancing is handled by VMware Avi Load Balancer (formerly NSX Advanced Load Balancer). The embedded NSX load balancer is deprecated and will be removed in future releases. Avi separates its control plane (the Avi Controller) from its data plane (Service Engines). The Controller manages policies and configuration. Service Engines handle traffic. This architecture scales horizontally and supports local load balancing, global server load balancing (GSLB), WAF (Web Application Firewall), and container ingress.
Kubernetes implements load balancing through Services and the Gateway API.
A Kubernetes Service is the fundamental mechanism for distributing traffic. When you create a Service, Kubernetes assigns it a stable virtual IP (a ClusterIP). Any pod matching the Service’s label selector becomes a backend. Traffic to the ClusterIP gets distributed across those pods.
Three Service types handle different scenarios. ClusterIP exposes the Service within the cluster only. NodePort exposes it on a static port on every node. LoadBalancer provides an external load balancer from the cloud provider or from a platform like MetalLB for bare-metal environments.
The kube-proxy component on each node implements Service VIP routing and load balancing. In clusters running Cilium, kube-proxy is often replaced entirely by Cilium’s eBPF implementation, which provides the same functionality with lower latency.
For more sophisticated traffic management, Kubernetes introduced the Gateway API. The Gateway API is an add-on CRD set. It is the successor to the older Ingress resource. Where Ingress was limited to basic HTTP routing and required vendor-specific annotations for advanced features, the Gateway API provides a role-oriented, portable model.
The Gateway API uses three resource types. GatewayClass defines which controller implementation handles traffic (similar to choosing between different Avi deployment profiles). Gateway configures listeners, ports, and protocols. HTTPRoute, TCPRoute, GRPCRoute defines routing rules that direct traffic to backend Services.
This role separation maps to organizational boundaries. Infrastructure teams manage GatewayClass and Gateway resources. Application teams manage Route resources. In NSX terms, this is similar to how network administrators configure Avi virtual services and pools while application owners define their health monitors and routing policies through self-service workflows.
The Gateway API is vendor-neutral. The same HTTPRoute configuration works with NGINX Gateway Fabric, Istio, Cilium, Envoy Gateway, and VMware Avi (which now supports Gateway API for Kubernetes workloads). This portability eliminates the vendor-specific annotation sprawl plaguing the old Ingress model.
Network Policies: The Kubernetes Equivalent of Micro-Segmentation
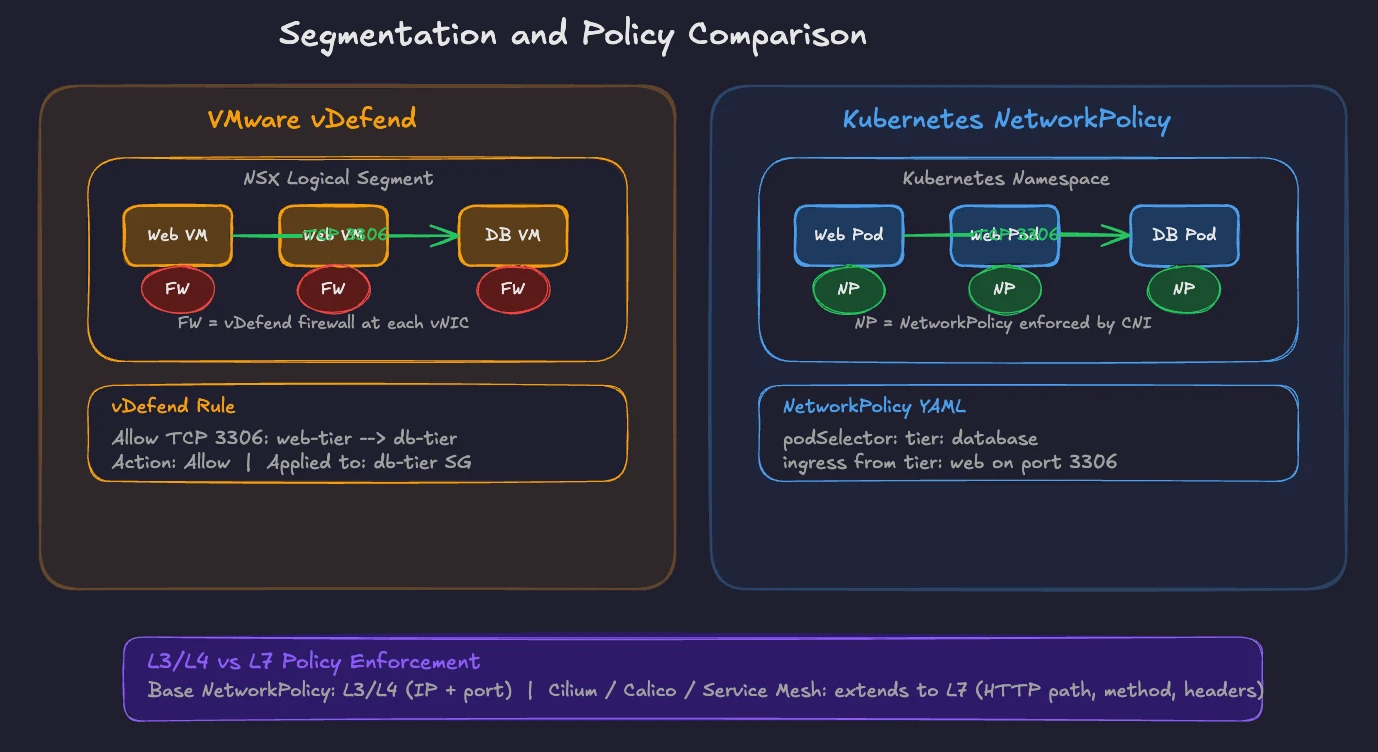
Micro-segmentation is one of NSX’s defining capabilities, now delivered through VMware vDefend in VCF. vDefend applies firewall rules at the virtual NIC level. Every VM gets its own firewall enforcement point. You define rules based on VM attributes, security groups, tags, and IP sets. Traffic between VMs in the same segment gets inspected and filtered. This level of granularity makes NSX valuable for zero-trust architectures.
Kubernetes Network Policies achieve the same goal. A NetworkPolicy is a namespace-scoped resource controlling traffic flow to and from pods. By default, all pods in a Kubernetes cluster accept traffic from any source. When you apply a NetworkPolicy to a set of pods, those pods become isolated according to the rules you define.
Network Policies use label selectors to identify pods, namespace selectors to scope rules across namespaces, and IP blocks for external traffic. You define ingress rules (what traffic a pod accepts) and egress rules (what traffic a pod sends).
Here is a concrete comparison. In vDefend, you might create a rule: “Allow TCP 3306 from web-tier security group to database-tier security group. Deny all other traffic to database-tier.” In Kubernetes, the equivalent NetworkPolicy selects pods with label tier: database, allows ingress on port 3306 from pods with label tier: web, and denies everything else by default.
The enforcement mechanism depends on your CNI plugin. The Kubernetes API server stores the NetworkPolicy object. The CNI plugin reads it and enforces the rules on the data plane. Cilium enforces policies using eBPF programs in the kernel. Calico enforces them through iptables or its eBPF data plane. Flannel does not enforce Network Policies, which is why production clusters rarely run Flannel alone.
An important distinction: Kubernetes Network Policies operate at L3/L4 (IP addresses and ports). For L7 policies (HTTP methods, URL paths, headers), you need a CNI plugin with extended capabilities. Cilium provides L7-aware network policies natively. Calico offers similar L7 enforcement through its enterprise features. Service meshes like Istio also enforce L7 policies through their sidecar proxies. We cover service meshes in detail in the next section, including when and why you would add one to your cluster.
VMware professionals will notice Kubernetes Network Policies are declarative, defined in YAML, and version-controlled in Git. This aligns with the GitOps operational model described in Part 1. Your network security rules become code, reviewed in pull requests, and applied through CI/CD pipelines. If you prefer a visual approach, there are options. Rancher and OpenShift provide UIs for editing network policies. Calico includes a visual policy editor. These tools are not as integrated as vSphere’s interface, but they bring familiar ClickOps workflows to Kubernetes networking for teams that want them.
Service Meshes: When You Need More
NSX provides a comprehensive networking and security platform through a single product family. Distributed routing, firewall, load balancing, VPN, and traffic analysis are all provided by a single vendor. You configure everything through NSX Manager.
Kubernetes takes a more modular approach. Basic networking comes from CNI plugins. Load balancing is provided by Services and the Gateway API. Network policies come from the CNI enforcement layer. When you need advanced traffic management for service-to-service communication, you add a service mesh.
A service mesh manages east-west traffic (service-to-service within the cluster), while the Gateway API manages north-south traffic (external clients to services). Service meshes provide mutual TLS (mTLS) encryption between services, traffic splitting for canary deployments, retry and timeout policies, circuit breaking, and observability through distributed tracing.
Istio is the most widely adopted service mesh. Istio uses Envoy proxy sidecars injected alongside application containers to intercept and manage traffic. Istio’s newer “ambient mode” eliminates sidecars by using a node-level ztunnel proxy for L4 concerns and optional waypoint proxies for L7 policies. This reduces resource overhead significantly. Istio supports the Gateway API natively and intends to make it the default traffic management API.
Linkerd is a lightweight alternative focused on simplicity and performance. Linkerd uses its own Rust-based micro-proxy instead of Envoy. It provides mTLS, traffic splitting, retries, and observability with lower resource consumption than Istio. Linkerd also supports the Gateway API for both ingress and mesh traffic through the GAMMA (Gateway API for Mesh Management and Administration) initiative.
Cilium offers service mesh capabilities without sidecars by handling traffic management with eBPF and proxy components, as needed, in a sidecar-less model. This approach provides mTLS, traffic policies, and observability without the per-pod proxy overhead.
Not every cluster needs a service mesh. If your workloads communicate over well-defined APIs and you need mTLS, traffic management, and service-level observability, a mesh adds real value. If your applications are simpler, CNI-level networking with Network Policies provides sufficient control.
For VMware professionals, the mental model is this: the CNI plugin is your virtual switch and distributed router. Network Policies are your distributed firewall (vDefend). The Gateway API, with a controller such as Avi, Istio, or Cilium, serves as your load balancer. A service mesh adds features equivalent to advanced NSX capabilities, such as traffic analysis, encryption, and application-level routing, for service-to-service communication.
Bringing the Concepts Together
The networking transition from VMware to Kubernetes follows a clear mapping:
NSX logical segments map to the combination of pod IPAM and cluster networking managed by your CNI plugin, with isolation enforced through NetworkPolicy, labels, and namespaces. Distributed routing at the hypervisor level becomes pod routing at the node level through Cilium, Calico, or Flannel. VMware vDefend micro-segmentation becomes Kubernetes Network Policies enforced by the CNI. VMware Avi Load Balancer becomes Kubernetes Services for L4 and the Gateway API for L7 traffic management. NSX’s integrated networking and security platform maps to a combination of CNI plugins, Network Policies, the Gateway API, and, optionally, a service mesh.
The modular approach in Kubernetes means more choices and more integration work. It also means more flexibility. You pick the CNI plugin that best matches your performance and security requirements. You pick the load balancer and the Gateway API controller fitting your operational model. You add a service mesh only when the complexity of your application architecture demands it.
Your NSX expertise gives you a strong foundation for understanding Kubernetes networking. The concepts are the same. Overlays, routing, segmentation, load balancing, and traffic management all exist in both worlds. The difference is how they are packaged, configured, and operated.
Part 7 examines security. You will learn how vCenter roles and permissions translate to Kubernetes RBAC, how VM isolation compares to pod security standards, and how secrets management and policy enforcement work in the cloud-native model. Stay tuned.
Demystifying Kubernetes – Blog series
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!
Chapter 1: From ClickOps to GitOps: Why the Paradigm Is Shifting
Economic pressure, operational philosophy changes, and what this means for VMware professionals.
Learn MoreChapter 2: KubeVirt: Running Virtual Machines in a Kubernetes World
How VMs and containers coexist—and why KubeVirt is the practical bridge forward.
Learn MoreChapter 3: Mapping the Stack: From VMware SDDC to Cloud-Native Architecture
A mental model that translates vSphere, vSAN, and NSX into Kubernetes equivalents.
Learn MoreChapter 4: Compute Reimagined: ESXi Hosts vs Kubernetes Nodes
How scheduling, abstraction, and control planes differ between hypervisors and Kubernetes.
Learn MoreChapter 5: Storage Evolution: From Datastores to Persistent Volumes
Translating vSAN concepts into container-native storage and CSI-driven architectures.
Learn MoreChapter 6: Networking Translated: NSX and the Kubernetes Networking Model
CNI plugins, services, ingress, and service meshes explained for VMware practitioners.
Chapter 7: Security Models Compared: vSphere Security vs Kubernetes Security
RBAC, isolation, policy enforcement, and shared responsibility in a cloud-native world.
Learn MoreChapter 8: Day 2 Operations: Monitoring, Lifecycle, and Reliability
How observability, upgrades, backup, and DR work once Kubernetes is in charge.
Learn MoreChapter 9: Planning the Migration: From VMware Estate to Kubernetes Platform
Assessment frameworks, migration strategies, team structure, and common pitfalls.
Learn MoreChapter 10: Beyond Migration: Building a Cloud-Native Operating Model
Platform engineering, GitOps, extensibility, and preparing for what comes next.
Learn More
Janakiram MSV
Industry AnalystJanakiram MSV (Jani) is a practicing architect, research analyst, and advisor to Silicon Valley startups. He focuses on the convergence of modern infrastructure powered by cloud-native technology and machine intelligence driven by generative AI. Before becoming an entrepreneur, he spent over a decade as a product manager and technology evangelist at Microsoft Corporation and Amazon Web Services. Janakiram regularly writes for Forbes, InfoWorld, and The New Stack, covering the latest from the technology industry. He is an international keynote speaker for internal sales conferences, product launches, and user conferences hosted by technology companies of all sizes.
Related posts



Chapter 8: Day 2 Operations: Lifecycle Management and Observability