



NetApp provides great storage systems, and you should consider using it as the physical storage layer of your Kubernetes cluster — just as many Portworx customers do. If reliability and uptime of stateful applications are important to you, avoid using the NetApp Trident driver, as it runs as a single master and is unreliable during node failures. Instead, consider running Portworx on top of NetApp, and get the best of both worlds. NetApp provides enterprise-class infrastructure. Portworx provides reliable, fast, scalable Kubernetes-native storage — plus integrated backup, DR, migrations, data security, and automated capacity management.
One of the advantages of working with so many customers is that we see a lot of production environments and use cases when it comes to Kubernetes storage. This experience helps our customers reduce downtime-causing infrastructure and application errors before they occur. Every day, we see hundreds of combinations of the following:
Apps — MongoDB, Kafka, Cassandra, Elasticsearch, MySQL, PostgreSQL, Couchbase, etc.
Infrastructure — AWS, Azure, Google, VMware, Bare Metal, etc.
Storage — EBS, Google PD, Azure Block, NetApp, Pure, Ceph, HPE, IBM, etc.
Because of this diversity, we have uncovered a number of patterns to avoid with our customers when they need to prioritize speed of operations and application availability to minimize downtime.
We have blogged about these issues on AWS and Azure in the past, but because details of the particular system matter, today we will focus on one of the most common issues our customers have with their NetApp storage and how to get the most out of NetApp and Kubernetes.
NetApp is one of the most successful and reliable enterprise storage systems on the market, and we are proud that NetApp is an investor in Portworx. NetApp is known for its innovation and enterprise-class support, and without a doubt, NetApp provides some of the best enterprise-class storage arrays on the market. Architected correctly, a Kubernetes cluster backed by NetApp storage can provide high levels of performance and resilience. This blog will share how to do just that by combining NetApp storage like ONTAP or SolidFire with Portworx.
The first thing to understand about Kubernetes storage is that Kubernetes itself doesn’t provide storage. Kubernetes is designed as a set of pluggable interfaces and — most recently — provides storage through an aptly named interface called CSI (container storage interface). When a stateful pod — such as MySQL — is deployed via Kubernetes, the volume will be provisioned on the underlying storage system, attached to the host where the pod is running via some protocol such as iSCSI, and then bind-mounted to the container itself via the CSI driver. Kubernetes provides “primitives” — like storage classes and persistent volume claims — but actual storage itself is made available to Kubernetes via the CSI driver.
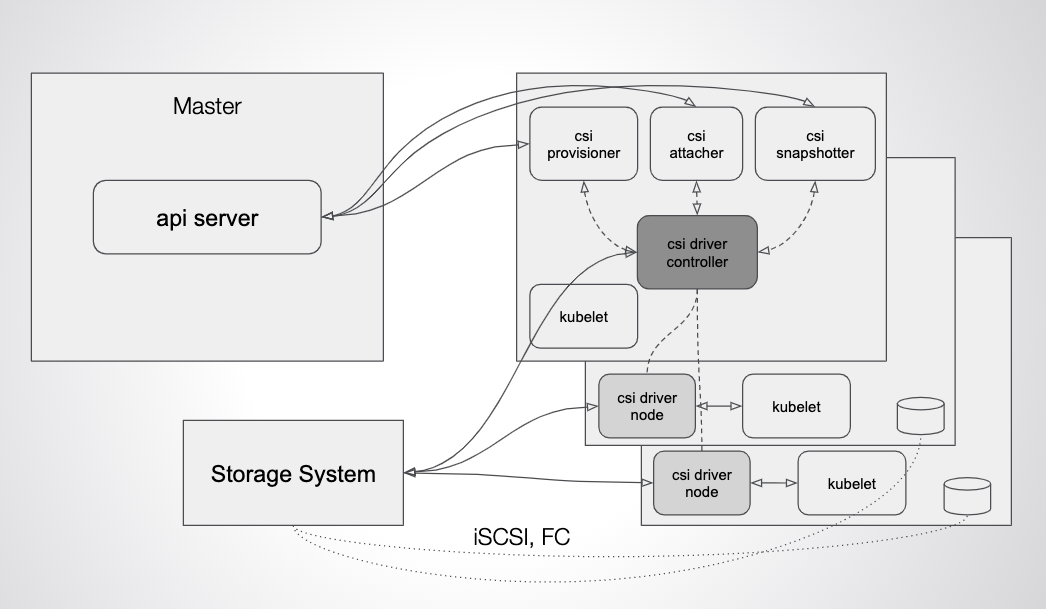
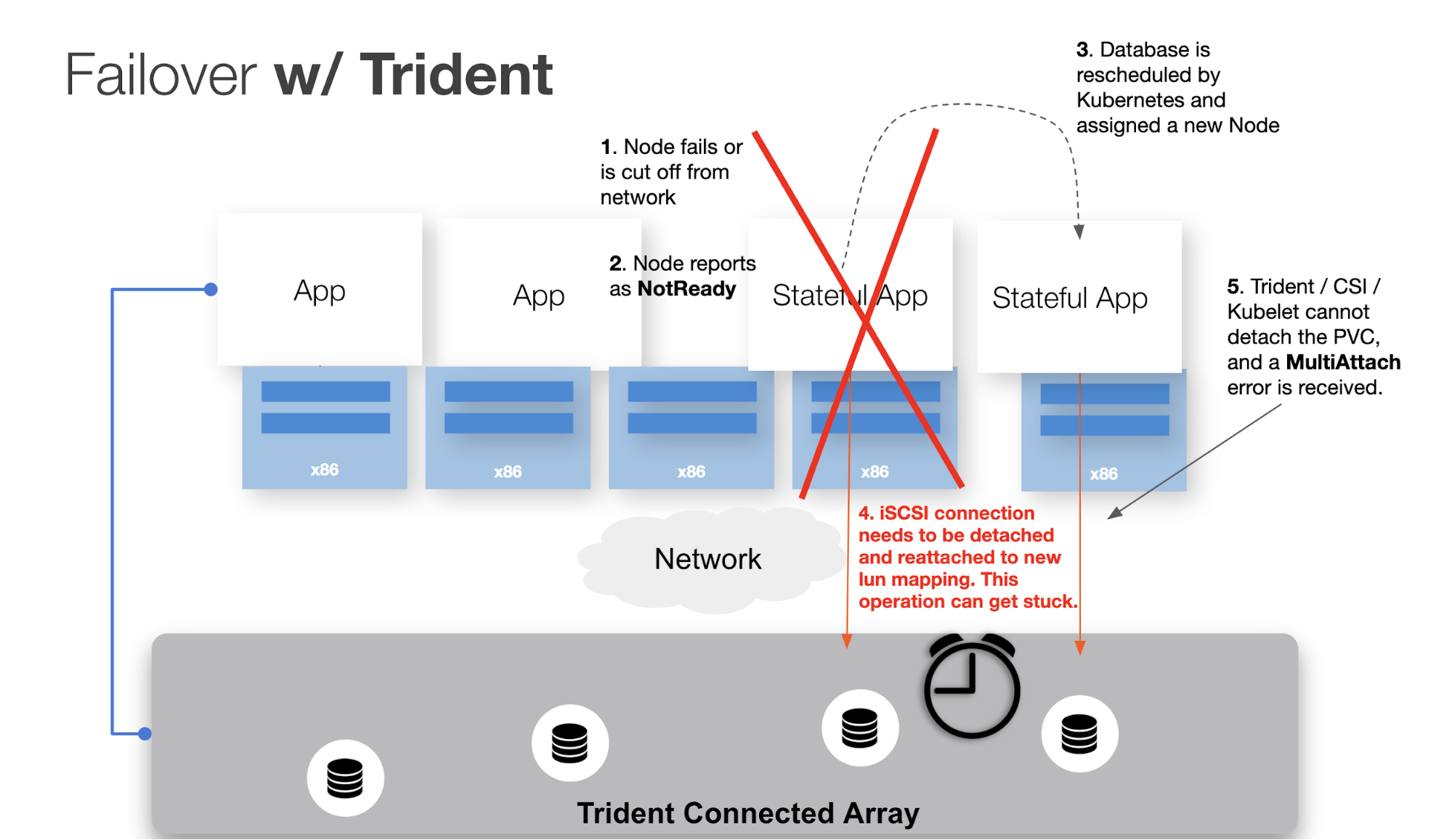
Likewise, when a pod is rescheduled by Kubernetes between hosts, the CSI driver is responsible for moving the volume attached to the new node. This is an example commonly called “failover.”
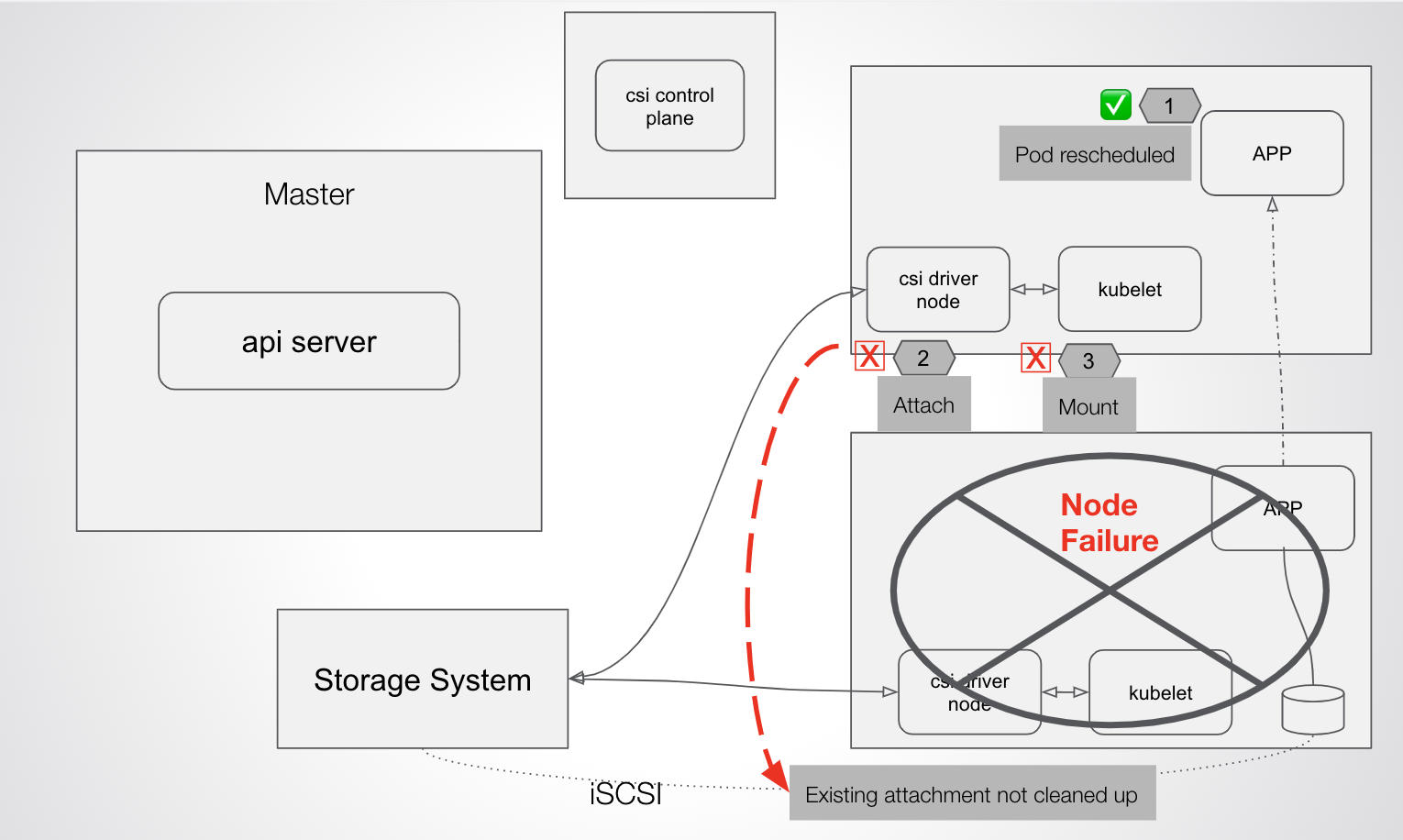
Because Trident handles control path communication between Kubernetes and the underlying storage system, any breakage of that pathway can cause situations in which Kubernetes is not able to start up a rescheduled stateful service on a new node because of control path issues detaching, attaching, and mounting — which leads to downtime.
This blog is about how to succeed with NetApp and Kubernetes, but this issue plagues not just the NetApp CSI driver, Trident, but all Kubernetes CSI drivers that connect a traditional shared storage system like Amazon EBS, Azure Block storage, Vsphere/VSAN, and Ceph to Kubernetes. Here are a few examples across the board.
These issues are all due to the same underlying problem — communication failure between Kubernetes and the underlying storage mediated by the control plane
After hearing about this issue from multiple NetApp Trident users, we investigated and discovered that, without fail, if a Kubernetes worker node running a stateful pod like MySQL was dropped from the cluster (e.g., a kernel panic or network partition occurred causing the node itself to fail), Kubernetes could not restart the pod on a new node without manual intervention. Even after 30 minutes of waiting, Trident could not provide the volume on the new host.
After digging into this issue to help our customer continue to use NetApp storage without suffering downtime after each node failure, we discovered that the issue is not with NetApp storage but with the control path that Trident and the CSI driver implements. This is good news because it means our customers can continue to use the NetApp storage but maintain continuous operations of their data services by using Portworx on top of NetApp storage. They can also take advantage of the integrated backup, DR, data security, and capacity management that makes up the Portworx Kubernetes Storage Platform.
There are a number of issues with Trident that make it unsuitable for large-scale, dynamic production environments (again, only Trident is not suitable; NetApp storage itself can be successfully used with another CSI driver — like Porwtorx — and we have many customers doing so).
First, Trident only runs as a single master. You would never run the Kubernetes control plane as a single master in production, and we do not recommend running your storage control plane as a single master, either. Not only is this a very fragile production setup for obvious reasons, but all your operations will have to go through a single choke point, rather than being truly highly available. This leads to slow volume provisioning time during operations like migrations that tend to create and delete a large number of volumes all at once. Trident may only test to 100 PVCs in their CI system, so while potentially suitable for small environments, enterprise customers will quickly run into scale issues.
The information below is from Trident documentation.

Source: https://netapp-trident.readthedocs.io/en/stable-v20.04/kubernetes/known-issues.html
Second, even without accounting for node failures that must be resolved with manual intervention, running stateful services using Trident requires regular upkeep from a storage administrator to do things like manage igroups, scale the system, take backups, etc. Trident is very limited in what it is capable of managing, leaving the DevOps team with a powerful storage system like NetApp that they can’t manage via Kubernetes.

Third, because Trident runs as a single pod and is not present on the majority of Kubernetes worker nodes where apps themselves are running, Trident struggles to provide basic levels of uptime when the cluster is degraded.
When a Kubernetes worker node fails, what we almost always want is for the pods running on that node to be rescheduled to another node in the cluster after some waiting period (e.g., we don’t want to reschedule our pods after a 3-second network partition but we might after a 1-minute partition). Once Kubernetes determines that a node itself is “down,” the node status changes to “NotReady.” At this point, there is an additional waiting period (the default is 5 minutes), before the pods are “evicted” from the failed node and rescheduled by Kubernetes. That is a lot of downtime for a production application.
The Portworx driver running on top of NetApp storage reduces the time it takes for Kubernetes to reschedule the pods by intelligently evicting pods from the failed node as soon as Portworx detects that the node is unable to run a stateful workload — which happens almost immediately. Trident, on the other hand, doesn’t force evict the pods, resulting in waiting for the full timeout period and extending production downtime.
But even after the pod eviction has occurred, Trident and Kubernetes are not able to recover the app without manual intervention.
When the new pod is eventually rescheduled and Kubernetes attempts to reattach the volume, the following error occurs: FailedAttachVolume attachdetach-controller Multi-Attach error for volume ...Volume is already used by pod(s).
The pod will continue to receive this error until the operation times out with the error:
Unable to attach or mount volumes … timed out waiting for the condition.
At this point, the only way to fix the issue — which is causing application downtime — is for the failed node to be brought online; otherwise, manual intervention needs to be taken.
This is likely due to the nature of iSCSI/FC-based connector systems that were not designed to handle these types of failures at the Kubenetes-native layer.
With a system running Trident in front of ONTAP, the rescheduled pod remained stuck indefinitely. During this test, we waited approximately 30 minutes for Kubernetes to try and recover on its own. CSI/Kubernetes could not detach and reattach the PVC to the new node without intervention.
The only way we were able to get the pod unstuck was to login to the backend ONTAP SAN management CLI and run the following commands:*
*Running these commands is not recommended, as they are manual and forceful and could cause corruption or other side effects.
With a system running Trident in front of SolidFire, the iSCSI session seemed to timeout after about 10 to 15+ minutes after forcefully deleting the old pods and letting the scheduler continue to try and start the new one on a healthy worker. Since 15 minutes of downtime is unacceptable for many enterprise apps, you can recover the app manually by running the following commands:*
*Running these commands is not recommended, as they are manual and forceful and could cause corruption or other side effects.
While Portworx also provides a CSI driver, it is not subject to the same limitations as Trident and the other CSI drivers mentioned above because Portworx has a completely different architecture and is not dependent on storage protocols like iSCSI and Fiber Channel as an intermediary between our storage layer and Kubernetes.
The key architectural difference is that since the Portworx container runs on every Kubernetes worker node, we know down to the I/O level if a pod is using a volume. As a result, we can tell Kubernetes, via our STORK (Storage Operator for Kubernetes) solution, where it is safe to attach a volume to a rescheduled pod. This dramatically speeds up failover and eliminates a big source of downtime.
Additionally, because Portworx runs on every Kubernetes worker node, volume create and delete operations can be parallelized, completing 1,000 simultaneous requests nearly 6x faster than Trident (300 seconds versus 1700 seconds).
| Failure Mode | Trident Outcome (ONTAP and SolidFire Backends) | Portworx Outcome |
|---|---|---|
| Trident POD Fails/Restarts during Active Application I/O | ◑ – New requests will need to retry until Trident POD is rescheduled | ✔ – I/O continues, control plane is Highly Available |
| Force fail node with stateful application | ❌- Multi-attach errors | ✔ – Stork rescheduled Pod immediately and moved backend PVC |
| Drop network from node running stateful application | ❌- Multi-attach errors | ✔ – Stork rescheduled Pod immediately and moved backend PVC |
| Create 500 PVCs and Delete 500 PVCs (1,000 simultaneous requests) | ❌-It was observed PVCs could take as long as 30 minutes to be bound | ✔ – Control plane able to handle all requests under 5 minutes |
If you want to continue to get the most out of your NetApp investment — and value application uptime, quick deployments, and migrations — consider running Portworx on top of your NetApp storage. Multi-attach errors and long wait times will go away, and you will be able to take advantage of Portworx’s integrated Backup, DR, Data Security, and Capacity Management suite. The combination of features, scale, and great customer support is why GigaOm ranked Portworx the #1 Kubernetes Storage Platform — ahead of NetApp and 11 other solutions.
We hope that this article has helped you understand why NetApp is a great storage backend for your Kubernetes cluster when combined with Portworx. By avoiding the Trident driver, you increase uptime and speed deployments — while still being able to use the NetApp hardware you already purchased.



