This is a follow-up blog to disaster recovery strategies for Kubernetes where we provided an overview of the Portworx Enterprise Data Platform’s Business Continuity and Disaster Recovery solutions:
- Asynchronous DR across a WAN or geographically dispersed area.
- Synchronous DR within a metropolitan area network.
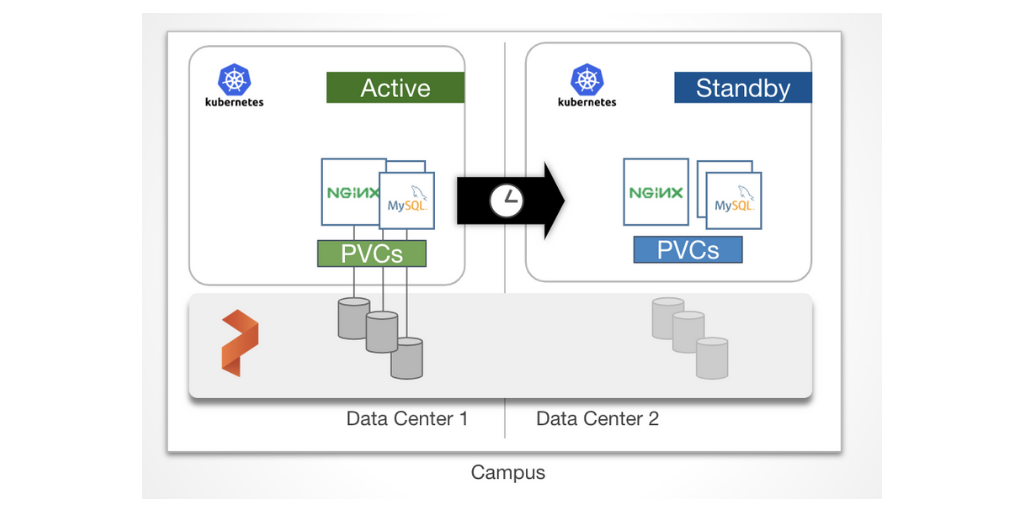
In this blog post, we will zoom in on the second option, synchronous DR which allows for zero-RPO failover of applications running in two data centers within a metropolitan area.
Providing reliable disaster recovery solutions for mission-critical applications is a must for teams running on Kubernetes today. Traditional backup and restore solutions for applications were typically designed for the virtual machine (VM), meaning they typically focused on the VM as the unit of concern. This worked great when the VM encompassed compute for the entire application, but now that VMs can run many pods, containers and services, business continuity solutions must take a fine-grained approach to provide containers and groups of microservices with proper backup and recovery solutions. Here are some limitations for DR solutions that use the VM as the unit of recovery:
- Do not account for Kubernetes namespaces so you can’t back up a particular namespace
- Do not account for applications running across multiple pods
- Is not aware of currently attached or mounted volumes for pods
- Is not aware of what Kubernetes objects belong to what applications (e.g. can back up data but not Kubernetes objects like PVCs, controllers, service accounts)
- Cannot provide a deep understanding of both the application and storage
- Is not scheduler aware
The implications of using a VM-based solution for Kubernetes applications means that recovery time objectives (RTOs) will be VERY high and there will be many operations and commands that need to be run before you can properly recover your applications in a DR site.
PX-DR solves these problems.
Synchronous DR
We will dig into how synchronous PX-DR works and how it helps achieve zero RPO failover and very low RTOs in a minute but first I want to review the differences between synchronous DR and asynchronous DR. This is important because understanding the differences between the solutions and what level of RTO and RPO they can provide directly impacts important decisions such as level of downtime and how that impacts top-line revenues which CIOs must take into account.
Synchronous vs Asynchronous DR
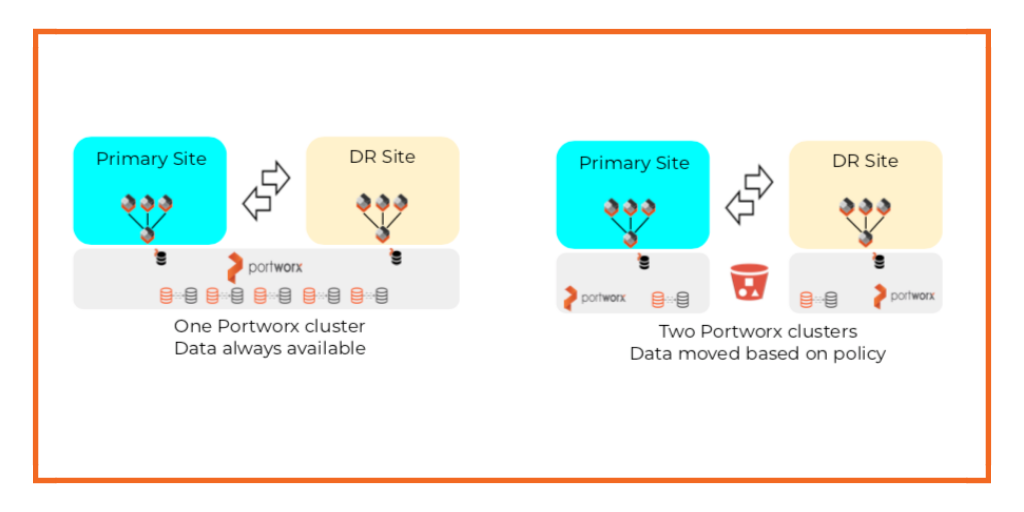
In the image below you can see that Portworx offers two business continuity solutions mentioned earlier in this post. Both provide a way to move data and application configuration between Primary and DR sites.
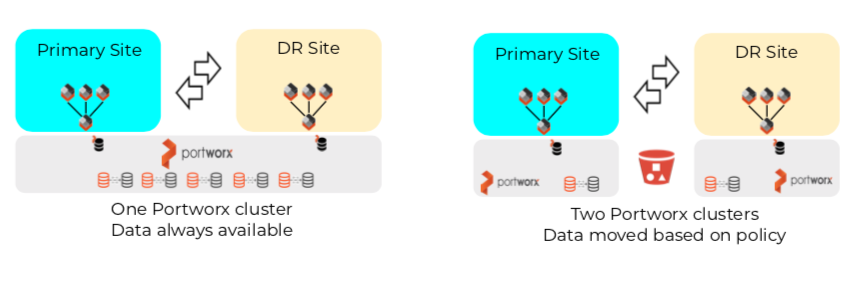
The main differences are that Synchronous PX-DR:
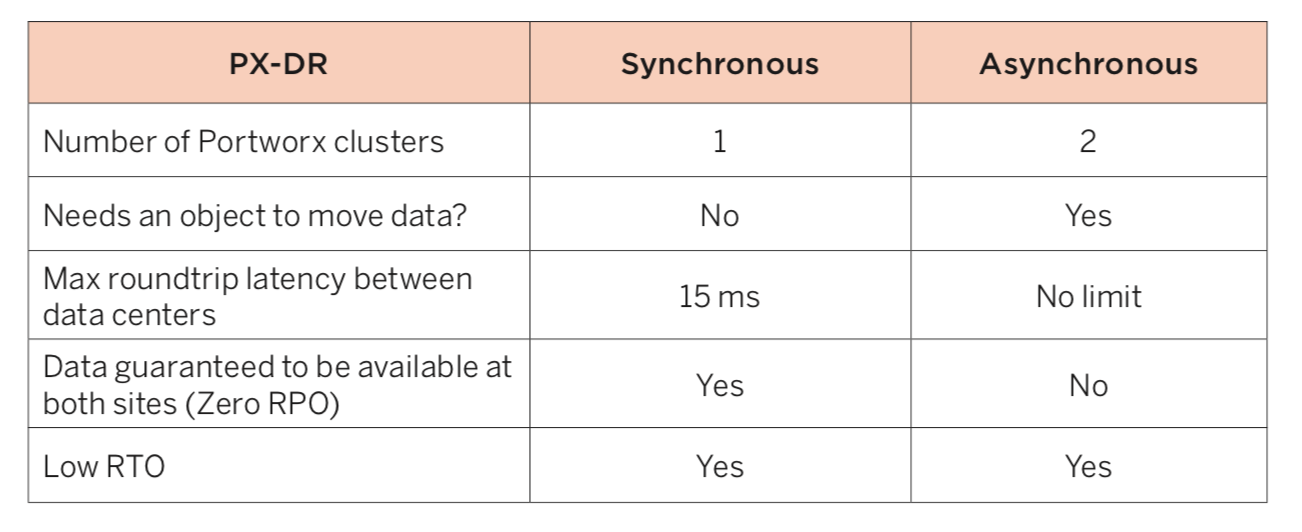
Note that there are also use cases which may be more appropriate for synchronous DR versus asynchronous DR. Below are a few examples drawn from Compliance use cases that show when it may be appropriate to consider one or both solutions.
- 164.308(7)(ii) (B) HIPAA Security Final Rule states that entities must “Establish (and implement as needed) procedures to restore any loss of data.”. When using PX-DR in synchronous mode, your disaster recovery site has a full copy of the data and you can achieve a zero RPO for data to support this use case. Using Asynchronous, there may be a very small gap in between backups. It is recommended to use PX-DR in synchronous mode to support zero RPO.
- Article 32 of the GDPR Act; Security of Processing states that entities should be able to “restore in timely manner” and other parts of the act say that “regular backups are essential”. Both synchronous and asynchronous versions of PX-DR support backing up based on policy and it is up to the administrator to set how much time between backups and retain copies such that organizations can meet these requirements.
How Synchronous DR works for Kubernetes
We’ve covered the differences between asynchronous DR and synchronous DR as well as given a few examples of some use cases where these solutions would work. So let’s dive in and see how it works.
Multiple sites, single Portworx data management layer
Synchronous PX-DR uses a single Portworx data management layer which sits below multiple Kubernetes clusters. This is important because this architecture must be used to achieve the synchronous DR capabilities of having multiple copies of data always available in both Kubernetes sites.
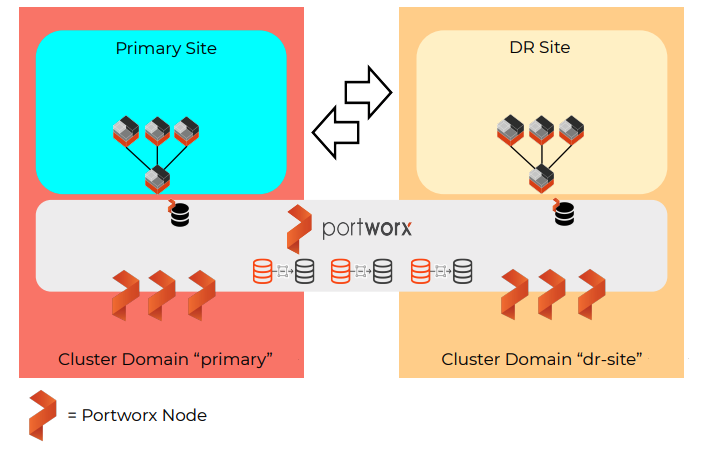
A single data management layer also means that there is effectively one Portworx cluster but with two cluster domains. A cluster domain allows the Portworx data management layer to distinguish between the Primary site versus the DR Site. The cluster domains are configured when the Portworx cluster is installed.
Low Latency Requirement
Synchronous PX-DR also needs low latency. Why? Because each write will be synchronously replicated to the backup site and application performance will suffer if the latency is too great. This is why volumes in this architecture must use a replication factor of at least two.
The latency should be a maximum of 15ms round trip time to the DR site but please keep in mind some applications may need even lower latency than this. When designing your application, think about the architecture and the overall latency needs for the application, this specific number is just a suggestion for PX-DR.
Tight integrations with Kubernetes
PX-DR is a fully-enterprise ready solution for your Kubernetes applications and data that is stored in the corresponding PVCs. Portworx also comes with the added benefit that this solution is fully integrated with the Kubernetes scheduler which makes your disaster recovery operations seamlessly integrated with your Kubernetes experience.
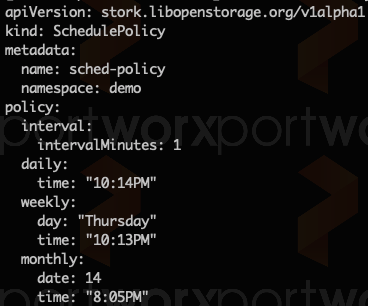
For example, creating cluster pairs, migrations or policies for these business continuity solutions can all be done via native Kubernetes YAML files. Knowing if your clusters are in sync or if your DR migrations are taking place can all be done through kubectl. This is made possible by the integration called stork that Portworx runs in every Kubernetes deployment.
Application config + data
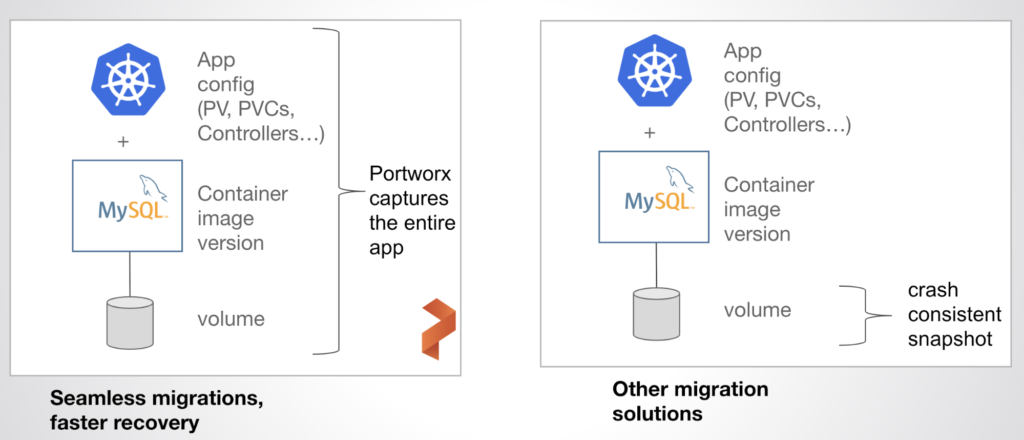
Most importantly, Portworx Enterprise disaster recovery solutions let users backup and restore the entire application stack. This means that the Portworx data management layer not only makes data guaranteed to be available in the DR site but that it is also moving copies of the application definitions that Kubernetes is aware of. This allows teams to “turn on” the DR site with the click of a button since Portworx makes everything you need available in both sites.
Let’s see it in action
Now that you have read a bit about what PX-DR can do, below is a video showcasing zero-RPO failover of an application running on Openshift’s Kubernetes Platform OCS.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!